Code for EMNLP NLPBT 2020 paper.
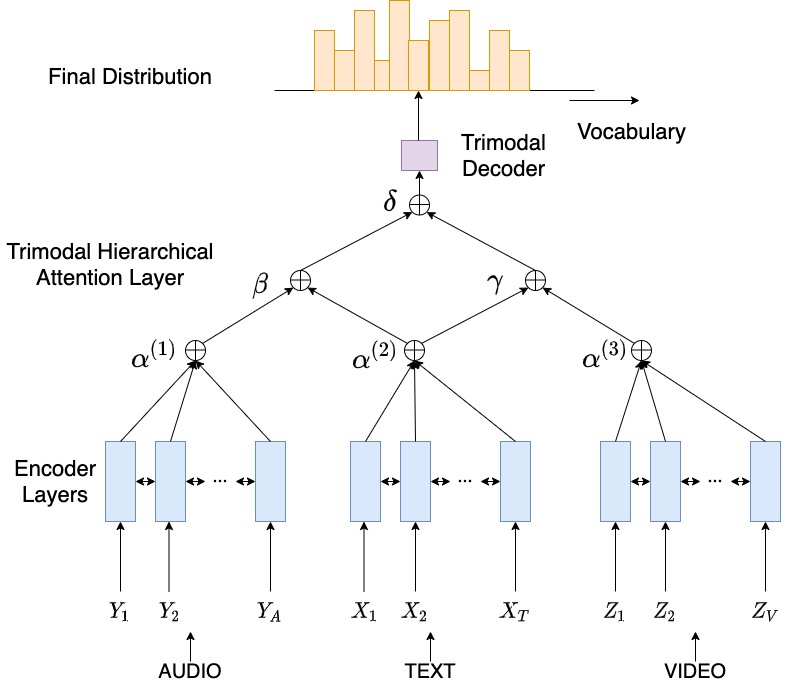
MAST is trained on the 300h version of the How2 dataset: https://github.com/srvk/how2-dataset, which includes audio, video and text.
pip install nmtpytorch
git clone https://github.com/amankhullar/mast.git- Replace
<path_to_env>/bin/nmtpywith filemast/nmtpy - Replace folder
<path_to_env>/lib/python3.6/site-packages/nmtpytorchwith foldermast/nmtpytorch
CUDA_VISIBLE_DEVICES=<gpu_id> nmtpy train -C <path_for_conf_file>CUDA_VISIBLE_DEVICES=<gpu_id> nmtpy test -b <batch_size> <model_ckpt_path> -m eval -s testIn order to load a pretrained model, add the argument 'pretrained_file' in the conf file with the path of the ckpt file as its value.
Following script combines the predictions and targets in single files (all_hyp.txt and all_ref.txt) where each line is a prediction or a target in their respective files.
python combine_txts.pyThis command calculates the Rouge 1,2 and L scores and stores them in the rouge_scores_sotah3.csv (please change name according to convenience).
python -m rouge.rouge --target_filepattern=all_refs.txt --prediction_filepattern=all_hyps.txt --output_filename=rouge_scores_sotah3.csv --use_stemmer=trueTo generate the attention on words from the transcript, run :
python text_attention.pyThis saves the file highlight.tex inside the respective folder in the att_wts dir.
Install the nlg-eval library and modify the file at <path_to_env>/lib/python3.7/site-packages/nlgeval/pycocoevalcap/meteor/meteor.py, changing the meteor_cmd to:
meteor_cmd = ['java', '-jar', '-Xmx{}'.format(mem), METEOR_JAR,
# '-', '-', '-stdio', '-l', 'en', '-norm']
'-', '-', '-stdio', '-l', 'en', '-norm', '-p', "1 1 0 0"]which updates the values of the hyperparameters required for Content-F1 metric.
To get heatmaps run :
python get_heatmaps.pyTo get heatmaps for only those examples where the predicted summary is shorter than the target summary (to account for decoder non tag)
python get_new_heatmaps.py