Display_SensorData
├── 📁src
| ├── 📁 1. 데이터 탐색 및 전처리
| | ├── 📃전처리 수행 완료코드.ipynb
| | ├── 📃(1) 컬럼명 구분.ipynb
| | ├── 📃(2) 결측치 처리.ipynb
| | └── 📃(3) 분산 0, 상관계수 0.9이상.ipynb
| ├── 📁 2. 데이터 변환
| | ├── 📃(1) PCA 수행 및 레이블 기준 선택.ipynb
| | └── 📃(2) RFE 수행 및 트리구조 확인.ipynb
| └── 📁 3. 모델링 수행 및 비교
| └── 📃분류 모델 수행 및 이상치 탐색.ipynb
├── 📁img (README.md 관련 이미지)
└── 📁old_code (시행착오 소스코드)
- 분석 환경 및 도구
- 프로젝트 개요
- 프로젝트 수행내용 요약
- (프로젝트 상세 수행내용📌(펼치기 후 클릭))
- 데이터 탐색
- 데이터 전처리
- 분류 모델링을 위한 데이터 변환
- 분류 모델 수행
- 프로젝트 결론
- HW/Server
- Window (ver 10 / CPU i7 / RAM 16)
- Ubuntu (ver 18.04)
- Language
- Python (ver 3.7)
- Tools
- Github
- Google Drive
- Slack
- IDE
- Colab
- Jupyter Lab (ver 2.2)
- Analysis Library
- Pandas (ver 1.1)
- Numpy (ver 1.19)
- Sklearn (ver 0.22)
- Matplotlib (ver 3.2)
- Seaborn (ver 0.11)
- 웨이퍼 식각 공정의 센서 데이터 분석을 통해 불량품이 자주 발생하는 하위 공정을 찾아냄
- Machine Learning을 이용한 시계열 데이터의 Anomaly Detection
- 생산공정 중 양품/불량품에 큰 영향을 미치는 저수율 요인을 찾아내는 것을 목표로 함
프로젝트 배경 설명📌(펼치기)
- TFT(박막트랜지스터)의 회로 패턴을 만들기 위해 웨이퍼의 필요한 부분만 남기고 불필요한 부분은 깎아내는 공정
- 반도체 8대 공정 중 4번째 공정으로, 공정 중 불량율이 발생할 확률이 높아 반도체 수율에 가장 큰 영향을 미침
- 반도체 공정의 각 프로세서에서 레시피(온도,압력,가공 시간 등)대로 작업이 이루어지지 않아서 저수율 웨이퍼가 발생함
- 공정 중 저수율 요인을 찾아내면 해당 프로세서의 집중적인 관리를 통해 고수율 웨이퍼의 생산효율을 극대화 할 수 있음
- 최적의 Etching 공정 레시피를 제공하고자 함
-
데이터 : 840 columns * 8145 rows, 시계열 센서 데이터
-
데이터 탐색(EDA) 및 전처리
-
평가지표 선정
-
PCA 분석을 통한 이상치 탐지 개수 선정
-
Machine Learning을 이용한 Classification 수행
-
XGBoost, Random Forest, SVM 이용
-
각 모델의 트리구조를 시각화하고 Gini 계수 탐색을 통한 Anomaly Detection
-
데이터 시각화를 통한 분석 내용 표현
-
웨이퍼 식각공정 후 테스트 단계에서 센서 측정 데이터를 분석하여 웨이퍼 저수율 요인을 찾고자 함
-
테스트 과정에서 웨이퍼 상태의 반도체 칩의 불량여부를 선별 가능함
-
저수율 요인을 찾아 설계상의 문제점이나 제조상의 문제점을 발견해 수정 가능함
프로젝트 상세 수행내용📌(펼치기)
- 데이터 : 디스플레이 Etching 공정의 센서데이터 (csv 파일)
- 840 컬럼 x 8145개 행의 int, float 타입 데이터임
- 반도체 식각 공정은 여러 단계로 구성되어 있으며, 각 단계는 사람이 검수함
- 따라서 각 피처는 휴먼에러를 포함하고 있을 수 있음
- 각 단계에는 센서가 배치되어 있으며, 이 센서는 1초 마다 값을 측정함
- 센서 측정값을 1시간 단위로 평균 내어 저장한 csv 파일을 분석 대상으로 함
- 결측치 처리
- 분산 0인 데이터 제거
- 생산라인 L, R 구분하여 한 쪽 라인 제거
- 피처 간 상관계수가 큰 피처 제거
- VIF > 30 이상의 피처 제거 (최종 모델링 작업에서는 생략함)
데이터 전처리 상세내용📌(펼치기)
- 전체 값이 없는 컬럼 삭제
- 7개 컬럼은 전체 8145개의 행이 모두 결측치임
- 데이터가 없으므로 삭제함
- 그 외 결측치 처리
- 남은 결측치는 ffill로 처리함
- 이 데이터는 센서 데이터의 1시간 단위 평균 값이므로 전체 컬럼에 대한 평균보다는 이전 행의 값으로 결측치를 처리하는 것이 적절함
- 분산이 0인 데이터를 제거하는 이유?
- 어떤 피처의 분산이 0이라는 것은 그 피처의 데이터가 모든 행에 대해 거의 변하지 않은 것을 의미함
- 어떤 경우에도 같은 값을 내는 컬럼이 불량률에 영향을 주고 있다고 보기 어려움
- 수행 방법
- 방법1 : sklearn의 VarianceThreshold 사용
- 방법2 : var() 사용
- 결과
-
피처 이름에 L, R가 반복하여 등장함
- 피처 이름을 비교해본 결과 L, R은 좌, 우 생산라인일 것으로 생각됨
-
생산라인 L, R 구분하여 한 쪽 라인 제거하는 이유?
- L, R이 동일한 공정을 수행하는 별개 라인이라면,
- 두 라인의 데이터를 모두 사용하는 것은 동일한 데이터가 최종 분류 모델에 중복하여 영향력을 주게 됨
- 이 프로젝트는 공정의 특성에 따라 발생하는 저수율 요인을 찾고자 함
- 따라서 L, R 라인에 속하는 공정이 동일한 공정이라면 L, R에 따른 차이가 발생해서는 안 됨
-
수행 방법 (1) L, R 이름 분류
- 피처 이름에 L, R이 표시된 피처를 분류함
- LR, L_R 등 구분이 어려운 이름은 우선 제외함
- L, R 을 분류함
- 그 외 분류되지 않은 피처는 공통 생산라인으로 간주함
- 라인별 피처 개수 확인
- L 피처 : 95개
- R 피처 : 91개
- L 피처와 R 피처의 개수가 약간 차이남
(2) L, R이 동일한 공정을 수행하는 별개 라인인지 확인
- 각 라인의 피처 이름을 비교
- L, R의 피처 이름을 비교하여 어느 한 쪽에 포함되지 않은 독특한 피처가 있는지 확인함
- 이름 비교 결과 L 피처와 R 피처 이름 패턴은 매우 유사함
- L, R 상관계수 히트맵 확인
- L, R 라인 각각의 상관계수를 히트맵으로 시각화함
- L, R 라인 각 히트맵은 매우 유사한 패턴을 보임
- 이는 L, R라인에 속한 피처 간에 유사한 상관관계가 있음을 의미함
- 결론
- L, R에 속한 각 피처의 유사한 이름, 피처간 상관계수의 패턴으로 보아
- L, R은 동일한 공정을 수행하는 별개 생산라인으로 판단하는 것이 타당함
(3) 피처 수가 적은 Right 라인의 피처를 제외하여 모델링 수행함
- 피처 이름에 L, R이 표시된 피처를 분류함
- 상관계수 : 피처가 서로 종속된 정도를 나타낸 값. 강한 상관관계에 있는 경우 큰 값을 나타냄
- 상관계수가 큰 피처를 제거하는 이유?
- 두 피처가 강한 상관관계에 있다는 것은, 하나의 피처 값이 다른 피처의 값에 큰 영향을 주고있음을 의미함
- 두 피처는 동일한 원인에 기인하여 변하는 것으로 추측할 수 있음
- 이를 제거하지 않고 두면 사실상 같은 의미인 데이터가 모델링에 여러 번 반영됨
- 사실상 종속관계에 있는 피처들이 모델링에 크게 기여하는 것과 같음
- 모델링에 영향을 미치는 원인들이 모두 비슷한 중요도로 반영되게 하려면 종속성이 낮은 피처들만을 이용하여 모델을 만드는 것이 타당함
- 여기서는 피처 간 상관계수의 절대값이 0.9 이상인 경우를 종속된 것으로 봄
-
VIF : Variation Inflation Factor, 분산팽창요인
- 다중회귀분석 시 종속변수 Y를 제외하고 독립변수(피처)에 대해서만 판단함
- 피처 사이에 회귀분석을 실시하여 결정계수(R2)가 높으면 다중공선성의 문제가 발생할 가능성이 높음
- 피처의 특정 조합에서 회귀선의 설명력(결정계수)이 높으면 VIF 값이 커짐
-
이 데이터의 경우 컬럼 수가 많아서 VIF 기준을 30 정도로 잡아야 함
-
VIF를 이용해서 컬럼을 제거하는 방법:
- (1) VIF 계산
- (2) VIF가 가장 큰 피처를 제외하고 다시 VIF 계산
- (3-1) 가장 큰 VIF가
- 이전의 VIF보다 커지거나,
- 무한으로 발산하는 경우에는
- 제외했던 컬럼을 다시 포함하고 2순위의 컬럼을 제외하여 (1), (2) 반복
- (3-2) 가장 큰 VIF를 확인한 결과 이전의 VIF보다 작고, 30 이상이면 (1), (2) 반복
-
순차적으로 진행되는 작업으로 수행 시간이 오래 걸리는 작업임
-
최종 모델링에서 제외한 이유 ?
- 위와 같은 방법으로 피처를 제거한 결과, 남은 피처가 모델을 충분히 설명하지 못하는 것 같음
-
대안
- RFE를 이용하여 중요 피처를 추출함
- 수행 목표 및 방법
- 프로젝트 목표인 중요 피처 도출을 위해 모델링 후 반복 작업함
- 수행 내용
- PCA 수행
- 레이블 기준 설정
- RFE 클래스를 이용한 중요 피처 선정
분류 모델링을 위한 데이터 변환 상세내용📌(펼치기)
- PCA 수행을 통해 중요 피처를 몇 개 추출하는 것이 적절한지 조사함
- n_components를 전체 피처 개수로 설정하여 PCA를 수행함
- 이 경우 주성분과 피처는 1:1 대응하므로, 데이터를 잘 설명할 수 있는 주성분 수가 곧 중요 피처 개수임
- 방법1 : Elbow Point 확인
- 피처 - 설명변수 그래프를 그려서 Elbow Point를 확인함
- 또는 설명변수가 급감하는 때의 주성분 인덱스를 찾음
- 이 방법을 사용하면 최소한의 주성분 개수로 전체 데이터의 경향을 설명할 수 있음
- 방법2 : 설명변수 비율의 누적합 확인
- 설명변수 비율의 누적합이 0.90일 때의 주성분 개수로 선택할 수 있음
- 이 경우 전체 데이터의 90%를 설명하기 위해 필요한 주성분 개수를 구하는 것과 같음
- 불량품/양품 나누는 기준 선택
- 기준 1 : 데이터 값 상위 5% 기준으로 불량품을 구분한 경우, 불균형한 트리가 생성됨

- 기준 2 : 양품/불량품 데이터 개수가 비슷해지도록 한 경우, 균형 잡힌 트리가 생성됨

- PCA 수행 결과로 나온 중요 피처 개수를 참고하여 RFE를 수행함
- RFE
- recursive feature elimination (재귀적 피처 제거)
- 모델에 가장 영향을 적게 미치는 일부 피처를 제외하고 다시 모델 학습을 수행함
- 위 작업을 반복하여 최종적으로는 중요한 피처만으로 학습한 모델을 반환함
- 피처 제외 기준 : 회귀 모델에서는 coef, 분류 모델에서는 feature_importance를 기준으로 함
- 이용한 클래스 : sklearn.feature_selection.RFE
- 단일 모델 학습 방식
- 단일 알고리즘으로 하나의 모델을 이용하여 분류함
- 해당 알고리즘 : SVM, Decision Tree
- Ensemble 모델 학습 방식
-
(1) Voting
- 여러 알고리즘으로 모델을 생성하고 분류 결과를 비교하여 가장 좋은 모델을 선정하는 방법
- voting 유형
- hard voting : voting 결과를 1, 0으로 리턴
- soft voting : voting 결과를 확률로 리턴
-
(2) Bagging
- 한 가지 알고리즘으로 여러 개의 모델 생성하여 병렬 학습함
- 각 모델은 데이터 샘플링을 달리하여 비교함
- 해당 알고리즘 : Random Forest
-
(3) Boosting
- 여러 모델이 순차적으로 학습함
- 이전 모델이 잘못 분류한 데이터에 가중치를 부여하고 다음 모델 훈련에 적용함
- 해당 알고리즘 : Ada Boost, GBM, XGBoost, LightBoost
-
(4) Stacking
- 이전 모델 훈련 결과로 나온 예측값으로 다음 모델(메타모델)을 훈련함
-
- 이 데이터에서는 극소수의 불량품을 판정하지 못하는 것을 피해야 함
- 양품은 고객에게 배송되고, 불량품은 재검수 해보는 상황에서
- 불량품을 양품으로 판정한 경우, 재검수가 이뤄지지 않고 불량품이 고객에게 배송됨
- 브랜드 신뢰도가 하락하는 등 치명적인 문제가 발생함
- 따라서 재현율(recall)이 적절한 평가지표임
- FP가 높고, FN이 낮은지 중점적으로 살펴야 함
평가지표 배경지식📌(펼치기)
- 정확도(accuracy) : TN + TP / 전체
- 정밀도(precision) : TP / (FP + TP)
- Pos로 예측한 것 중 실제 Pos였던 것
- 양성예측도
- Pos 예측 성능을 더 정밀하게 측정하기 위한 평가지표
- FP를 낮추는 데 초점
- 재현율(recall) : TP / (FN + TP)
- 실제 Pos인 것 중 실제 Pos였던 것
- 민감도, TPR(True Positive Rate)
- Pos를 Neg로 판단하면 치명적인 경우 사용
- FN을 낮추는 데 초점
- F1 Score
- 정밀도와 재현율의 조화평균
- 두 평가지표를 적절히 고려하는 경우에 사용함
- 2pr/(p+r)
- ROC 곡선
- 이진분류의 예측 성능 측정에 사용함
- FP비율 - TP비율(recall) 곡선
- (작성예정)🐥
-
다른 분류 모델에 피해 recall 지표가 가장 우수한 XGBoost를 기준으로 이상치를 탐색함
-
PCA 분석에 따르면 24개의 피처로 데이터의 90%를 설명할 수 있음
-
Feature Importance 상위 24개의 피처 확인함
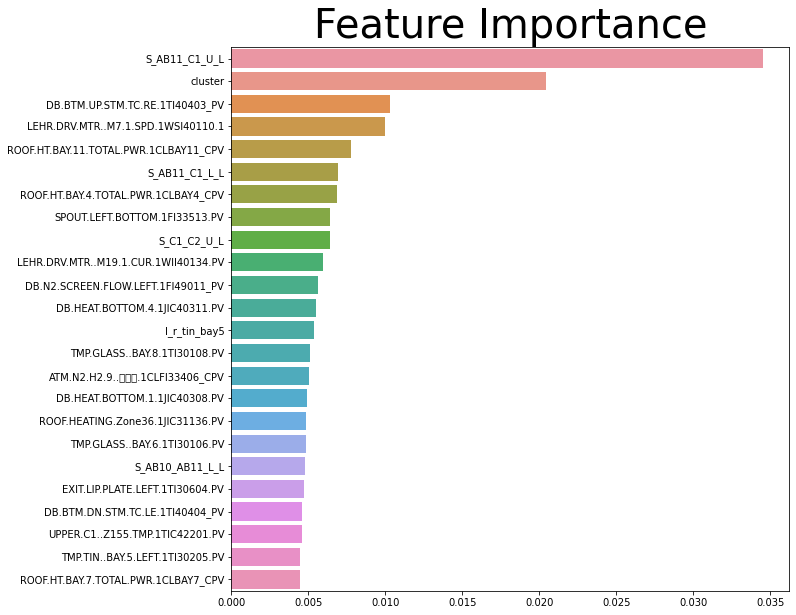
-
해당 피처로 Decision Tree를 그려서 트리구조 및 Gini계수 확인
-
위의 두 단계를 거쳐 선택한 피처들과 레이블의 관계 시각화
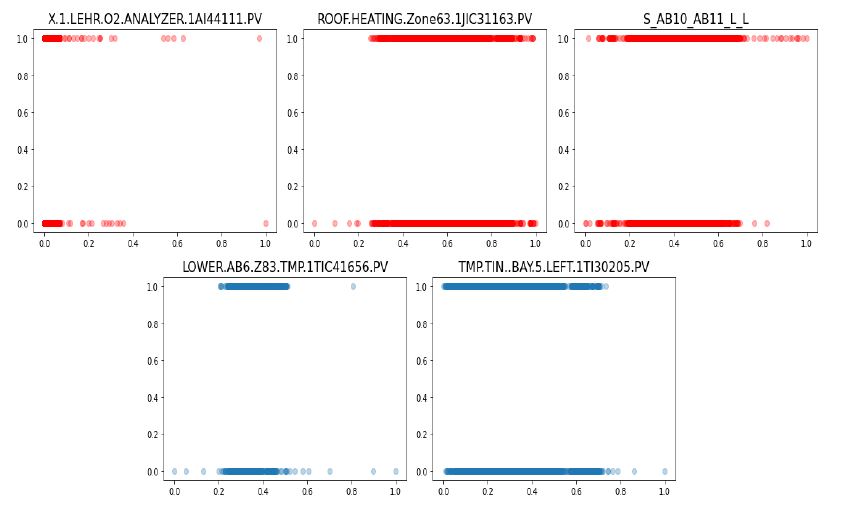



-
피처 조건에 따른 불량률 판단기준 확립하고 불량품을 검출하는 분류 모델을 수립하여, 불량품에 영향을 주는 피처 5 개 검출함
-
데이터 분석 결과를 생산시스템에 적용하면 다음과 같은 측면에서 현장운영이 수월해질 것으로 기대됨
- 수율안정화
- 현장관리 수준향상
- 지속적으로 불량요인을 발생시키는 피처 데이터를 축척함으로써 지도학습 모델을 이용한 불량탐지 자동 검출 시스템을 구축할 수 있음