Microsoft sees all the big companies creating original video content and they want to get in on the fun. They have decided to create a new movie studio, but they don’t know anything about creating movies. I am charged with exploring what types of films are currently doing the best at the box office.I must then translate those findings into actionable insights that the head of Microsoft's new movie studio can use to help decide what type of films to create.

In this project description, we will cover:
- Project Overview: the project goal, audience, and dataset
- Deliverables: the specific items you are required to produce for this project
- Grading: how your project will be scored
- Getting Started: guidance for how to begin your first project
This is a really new thing Microsoft is doing and the main thing data analysis is here to do is:
- bring out the types of films that are currently performing in box-office.
- Translate the findings from the performing films into actionable insights that the head of Microsoft's new movie studio can use to help decide what type of films to create.
- Bring out any new findings that would boost the content creation as a start.
Tentatively this will be judged a success if:
- By bringing out the types of films currently performing in box office makes Microsoft have a snippet of what they will start with in content creation.
In the folder zippedData are movie datasets from:
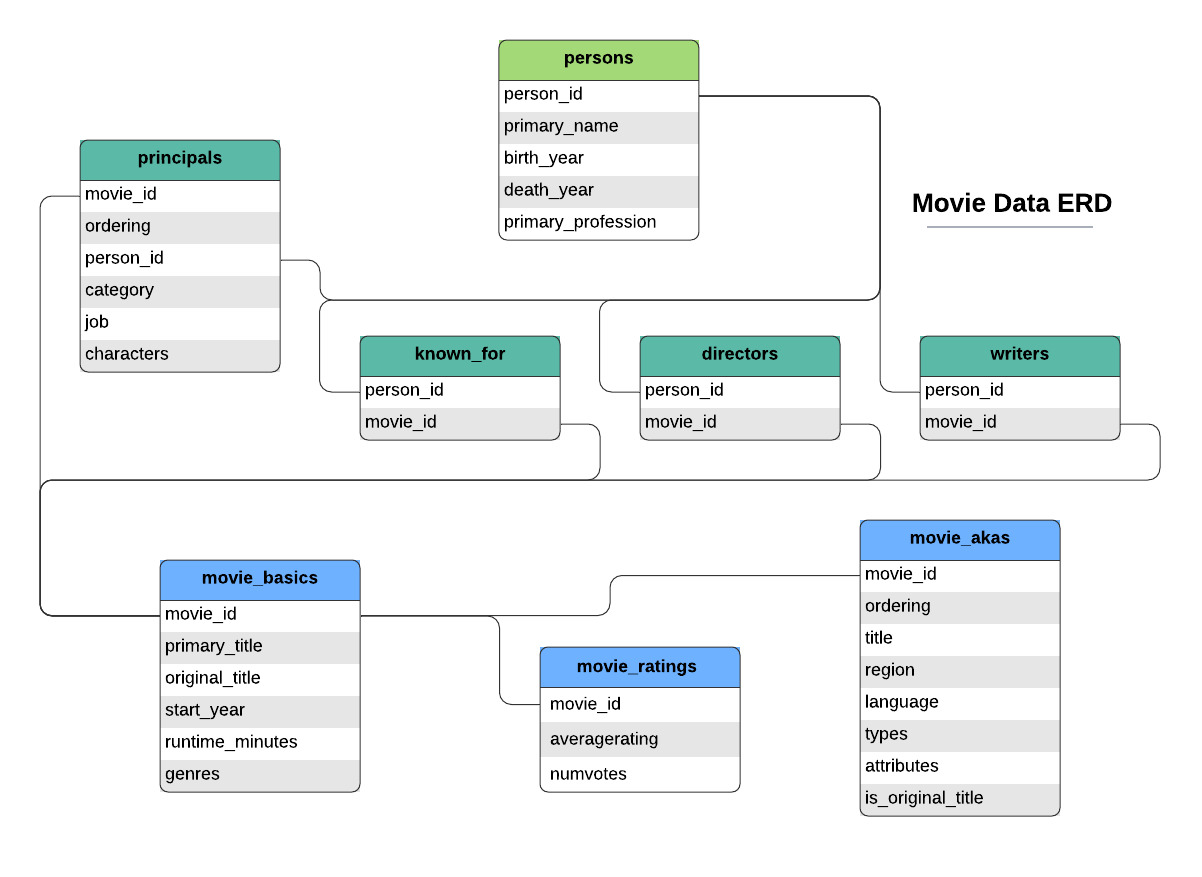
Note that the above diagram shows ONLY the IMDB data.
I decided to use the data from:
This data was collected from the bom.movies_gross dataset. The program Box Office Mojo by imdbpro contains the movies that we are to use in this data.
2.Data Description
This dataset has the columns; title,studio,Domestic_gross,foreign_gross and year.
I did a preview to check for the missing values in this dataset:
- studio - 5 values
- domestic_gross - 28 values
- foreign_gross - 1350 values
The studio column was mostly focused on so that we can get the most popular studios
I collected this data from the numbers dataset. This dataset shows us the top performing movies in terms of the gross that is produced and the production budget.
2.Data Description
This dataset contains the columns;
- id
- release date
- movie
- production budget
- domestic gross
- worldwide gross
I did a preview of the dataset to find missing values and there were no missing values.
This data was collected from the IMDB dataset. The program IMDB contains the movies that we are to use in analysis. The movies have been placed in structured tables in relation to each other.
This dataset has 8 tables:
- movie_basics
- directors
- known_for
- movie_akas
- movie_ratings
- persons
- principals
- writers
I joined the movie_basics and movie ratings tables in order to have a good overview of the average rating and the genre.
I used the studio, domestic gross and foreign gross columns as they are relevant to the study. The other columns will be used to look out for correlation.
I used the movie, production budget, domestic gross and worldwide gross as they are really needed to have a good analysis. The other columns will be used to look out for correlation.
I Decided to merge the movie basics and movie ratings table, so that I may know the genres and their specific ratings. This is much critical to the study. The other tables will be used for correlation.
The first step was to check for the data types of each column. This is to make sure the relevant columns have the appropriate data types for analysis. Then to check for the missing values to avoid later problems. I found out that the studio, domestic gross and foreign gross columns have missing values. The foreign gross column was in string format yet it represents currency so I had to coerce it to numeric before beginning to remove the missing values. I then decided to change the missing values into a percentage so that I can easily find out their impact on the data. The foreign gross column had a higher percentage, followed by the domestic gross then the studio column. The domestic gross column had few null values dropping the null values would not be appropriate, but filling the null values with the median would make more sense. The studio column had also few null values and because it is a string it was suitable to fill the missing values with “missing” would be appropriate so that we just know that a certain row had no studio. We have almost half of the dataset with missing values and they are from the foreign gross column, it will be wise if we drop the rows with the missing values from our dataset. The last step was to confirm that there are no null values after the data cleaning procedure. Having done the missing values successfully, the second step was to check for the outliers as they may really affect my analysis. The domestic gross column had 180 outliers while the foreign gross column had 260 outliers. The total outliers in the whole dataset were 2032, removing the outliers would really affect the dataset as most of the rows will be removed, the proper decision here was to retain the outliers.
The columns were then checked to see if they were of the appropriate types / dtypes. The production budget, domestic gross and foreign gross columns were in string format yet we need them in numeric form to enable numeric calculations. The three columns were then converted to numeric form to enable calculations. After this, missing values in the datasets were checked for and were found to be none. The data was also found to be consistent there being no duplicated data although the dataset had 5782 outliers. Removing these outliers would really affect the outliers and hence deciding to retain the outliers was the most suitable decision.
I merged two tables movie ratings and movie basics. The first thing done was to rename the columns in the merged table (merge imdb) to make them uniform and readable. The columns were then checked to see if they were of the appropriate types / dtypes. After this, missing values in the datasets were checked for and two columns runtime minutes and genres had missing values. I then found the shape of the merge imdb table. I replaced the values in the genres column with “missing” because it is a categorical data. I dropped the missing values in the runtime minutes’ column because it is not part of what I will use for the analysis. The data was also found to be consistent there being no duplicated data. One of the worrying things was the number of outliers, the whole dataset had a total of 66236 outliers. This meant I could not remove them as they would have a huge impact on the analysis.
(a). Numerical
The missing values in the studio column were replaced with “missing” to simply show that a certain row had no studio. The domestic gross column missing values were replaced with the median while the foreign gross column rows that had missing values were dropped. There were a lot of outliers, domestic_gross(180) and foreign_gross(26) columns. These are too many to remove as this will affect the accuracy of the data analysis, and the result could be inconclusive and/or incorrect. The outliers suggest that the data could possibly be data that does not have a normal distribution.
(b). Categorical
The studio column is the category of interest. By finding the count we get to know the most popular studios. Universal studios, Fox studios and WB studios are the top three studios
(a)Numerical
Actually the essence of this dataset is the gross income and the production budget. The production budget column had 431 outliers, the domestic gross column had 463 outliers and the worldwide gross had 604 outliers. Removing these outliers would really impact the analysis, so the option was to change the numeric columns in string to integer to enable calculations. I then used the movie and gross column to know how the much money the movies produce both locally and worldwide. In the domestic gross, we had Star Wars, avatar and black panther giving the highest domestic gross while in the worldwide gross we had Avatar, Titanic and Star Wars leading. I added a new column gross income to give us the gross from domestic gross and foreign gross. Comparing the movie and its production budget was also a relevant idea just to help us take various precautions.
(b)Categorical
This dataset was mainly focused on numeric data rather than categorical data. The only categorical data here was the movie column which was directly related to the numerical columns.
The most important data that was being analyzed from here was categorical data, the focus was on the movie basics and movie rating tables which I merged to get one table merge imdb that could give an overview of a genre and its average rating. Having had a lot of outliers in some columns like number of votes it would be really difficult to use them in the analysis as this would also largely impact the question of study. The genre that was being produced the most was Drama, Documentary and comedy. Also worth noting was that the top 10 genres being produced had an element of drama in them example; comedy-drama, drama-romance. I also tried to sort the average rating in order to find the top genres being watched and it was worth noting that the top genre was documentary, comedy, drama, adventure and crime also had some elements although Documentary is the genre with a high rating. Most of the genres also had an average runtime minutes of 90.0 minutes about 1 hr. 30 minutes which is of much importance to Microsoft. Most genres were also averaging a rating of 6 meaning Microsoft should take note of this.