In this assignment you will create a highly scalable web search engine.
Due Date: Sunday, 9 May
Learning Objectives:
- Learn to work with a moderate large software project
- Learn to parallelize data analysis work off the database
- Learn to work with WARC files and the multi-petabyte common crawl dataset
- Increase familiarity with indexes and rollup tables for speeding up queries
-
Fork this github repo, and clone your fork onto the lambda server
-
Ensure that you'll have enough free disk space by:
- bring down any running docker containers
- run the command
$ docker system prune
In this first task, you will bring up all the docker containers and verify that everything works.
There are three docker-compose files in this repo:
docker-compose.ymldefines the database and pg_bouncer servicesdocker-compose.override.ymldefines the development flask web appdocker-compose.prod.ymldefines the production flask web app served by nginx
Your tasks are to:
-
Modify the
docker-compose.override.ymlfile so that the port exposed by the flask service is different. -
Run the script
scripts/create_passwords.shto generate a new production password for the database. -
Build and bring up the docker containers.
-
Enable ssh port forwarding so that your local computer can connect to the running flask app.
-
Use firefox on your local computer to connect to the running flask webpage. If you've done the previous steps correctly, all the buttons on the webpage should work without giving you any error messages, but there won't be any data displayed when you search.
-
Run the script
$ sh scripts/check_web_endpoints.shto perform automated checks that the system is running correctly. All tests should report
[pass].
There are two services for loading data:
downloader_warcloads an entire WARC file into the database; typically, this will be about 100,000 urls from many different hosts.downloader_hostsearches the all WARC entries in either the common crawl or internet archive that match a particular pattern, and adds all of them into the database
We'll start with the downloader_warc service.
There are two important files in this service:
services/downloader_warc/downloader_warc.pycontains the python code that actually does the insertiondownloader_warc.shis a bash script that starts up a new docker container connected to the database, then runs thedownloader_warc.pyfile inside that container
Next follow these steps:
- Visit https://commoncrawl.org/the-data/get-started/
- Find the url of a WARC file.
On the common crawl website, the paths to WARC files are referenced from the Amazon S3 bucket.
In order to get a valid HTTP url, you'll need to prepend
https://commoncrawl.s3.amazonaws.com/to the front of the path. - Then, run the command
where
$ ./download_warc.sh $URL$URLis the url to your selected WARC file. - Run the command
to verify that the docker container is running.
$ docker ps - Repeat these steps to download at least 5 different WARC files, each from different years. Each of these downloads will spawn its own docker container and can happen in parallel.
You can verify that your system is working with the following tasks. (Note that they are listed in order of how soon you will start seeing results for them.)
- Running
docker logson yourdownload_warccontainers. - Run the query
in psql.
SELECT count(*) FROM metahtml; - Visit your webpage in firefox and verify that search terms are now getting returned.
The download_warc service above downloads many urls quickly, but they are mostly low-quality urls.
For example, most URLs do not include the date they were published, and so their contents will not be reflected in the ngrams graph.
In this task, you will implement and run the download_host service for downloading high quality urls.
-
The file
services/downloader_host/downloader_host.pyhas 3FIXMEstatements. You will have to complete the code in these statements to make the python script correctly insert WARC records into the database.HINT: The code will require that you use functions from the cdx_toolkit library. You can find the documentation here. You can also reference the
download_warcservice for hints, since this service accomplishes a similar task. -
Run the query
SELECT * FROM metahtml_test_summary_host;to display all of the hosts for which the metahtml library has test cases proving it is able to extract publication dates. Note that the command above lists the hosts in key syntax form, and you'll have to convert the host into standard form.
-
Select 5 hostnames from the list above, then run the command
$ ./downloader_host.sh "$HOST/*"to insert the urls from these 5 hostnames.
Since everyone seems pretty overworked right now, I've done this step for you.
There are two steps:
- create indexes for the fast text search
- create materialized views for the
count(*)queries
-
Edit this README file with the results of the following queries in psql. The results of these queries will be used to determine if you've completed the previous steps correctly.
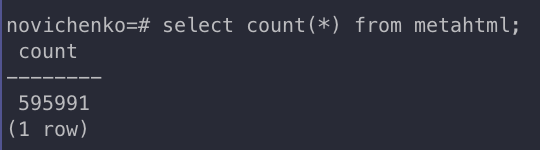
- This query shows the total number of webpages loaded:
select count(*) from metahtml;
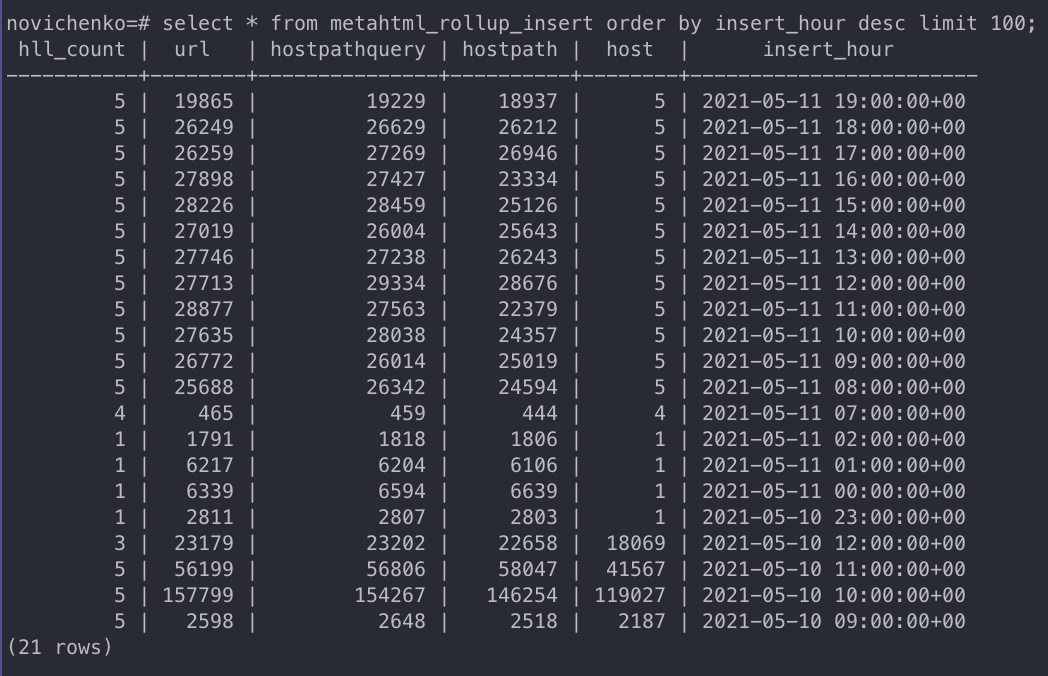
- This query shows the number of webpages loaded / hour:
select * from metahtml_rollup_insert order by insert_hour desc limit 100;
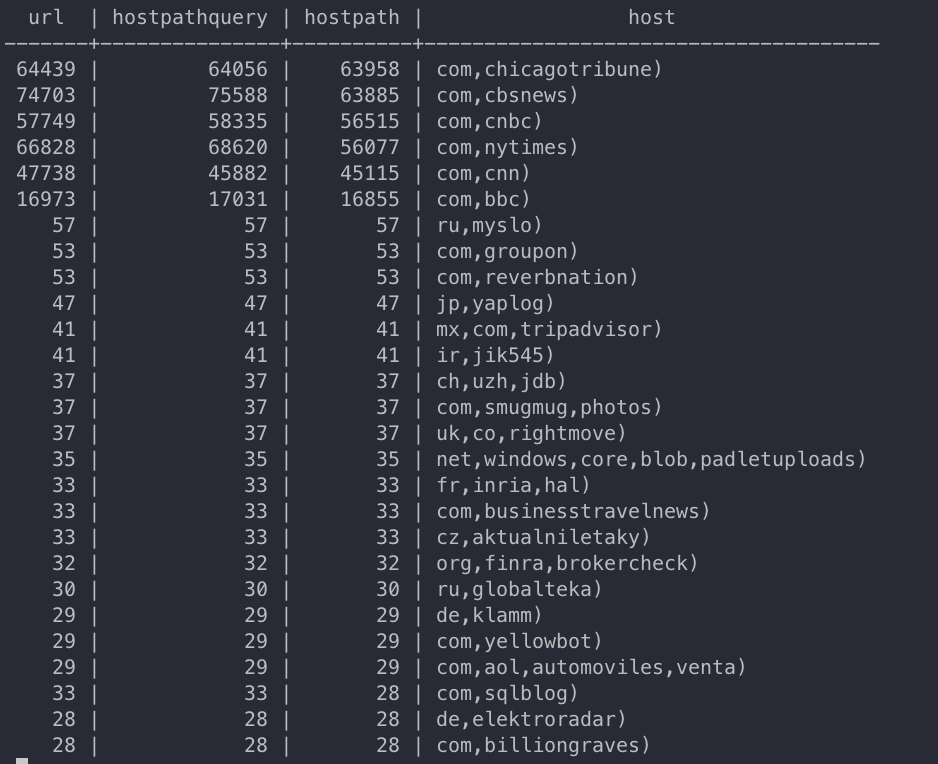
- This query shows the hostnames that you have downloaded the most webpages from:
select * from metahtml_rollup_host order by hostpath desc limit 100;
- This query shows the total number of webpages loaded:
-
Take a screenshot of an interesting search result. Add the screenshot to your git repo, and modify the
<img>tag below to point to the screenshot.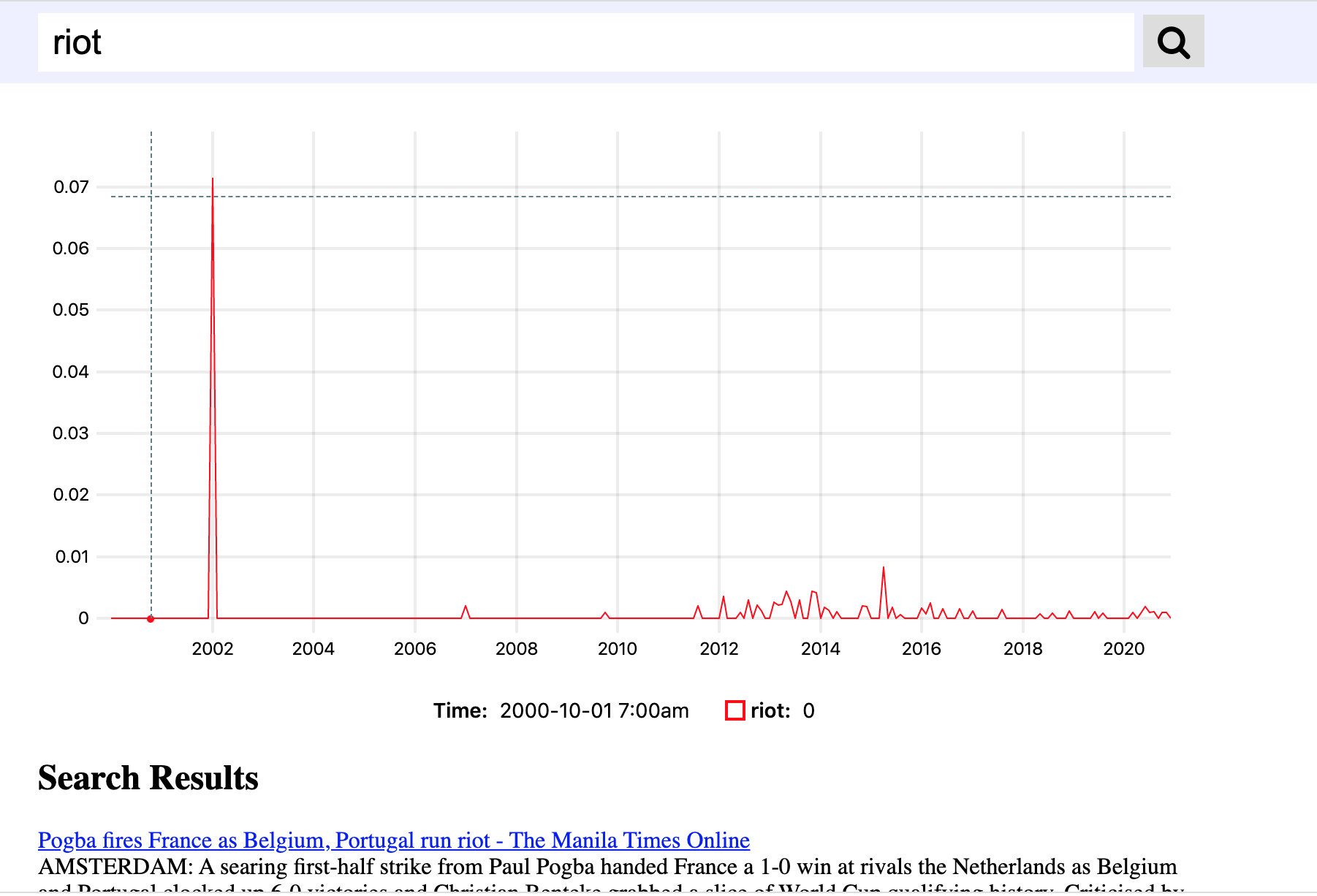
-
Commit and push your changes to github.
-
Submit the link to your github repo in sakai.



