[TOC]
Python的一些数值类型: 整型,布尔类型,浮点型, e记法
>>> type(5)
<class 'int'>
>>>
>>> type(True)
<class 'bool'>
>>>
>>> type(False)
<class 'bool'>
>>>
>>> True + False
1
>>> type(True+False)
<class 'int'>
>>>
>>> 0.0000000001
1e-10
>>>
>>> 1.5e10
15000000000.0
>>>
>>> type(1.5e10)
<class 'float'>
>>>
>>> type(0.000000000001)
<class 'float'>
- BIF 函数: int(), str(), float()
- 浮点数转成整数,不是四舍五入,而是直接向下去整
>>> a = '520'
>>> b = int(a)
>>> b
520
>>>
>>>
>>> b = int('小甲鱼')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '小甲鱼'
>>> a = 5.99
>>> b = str(a)
>>> b
'5.99'
>>> b = int(a)
>>> b
5
- type(), 返回值True,False
- 函数 isinstance( __ obj, __class_or_tuple), 返回值True,False
- 字符串模块 str.isdigital(), 返回值True,False
- 在 Python 中,int 表示整型,那你还记得 bool、float 和 str 分别表示什么吗?
- 你知道为什么布尔类型(bool)的 True 和 False 分别用 1 和 0 来代替吗?
- 使用 int() 将小数转换为整数,结果是向上取整还是向下取整呢?
- 我们人类思维是习惯于“四舍五入”法,你有什么办法使得 int() 按照“四舍五入”的方式取整吗?
- 取得一个变量的类型,视频中介绍可以使用 type() 和 isinstance(),你更倾向于使用哪个?
- Python3 可以给变量命名中文名,知道为什么吗?
- 【该题针对零基础的鱼油】你觉得这个系列教学有难度吗?
-
针对视频中小甲鱼提到的小漏洞,再次改进我们的小游戏:当用户输入错误类型的时候,及时提醒用户重新输入,防止程序崩溃。
如果你尝试过以下做法,请举下小手:
temp = input("不妨猜一下小甲鱼现在心里想的是哪个数字:") # 这种想法是因为type(1)会返回<class 'int'>,如果type(temp)返回结果一致说明输入是整数。 while type(temp) != type(1): print("抱歉,输入不合法,", end='') temp = input("请输入一个整数:")
或者可能这样:
temp = input("不妨猜一下小甲鱼现在心里想的是哪个数字:") # not操作符的作用是将布尔类型的结果翻转:即取反的意思,not True == Flase while not isinstance(temp, int): print("抱歉,输入不合法,", end='') temp = input("请输入一个整数:")
以上方法的思路是正确的,不过似乎忽略了一点儿:就是input()的返回值始终是字符串,所以type(temp)永远是<class 'str'> ! 其实有蛮多的做法可以实现的,不过就目前我们学习过的内容来看,还不足够。 所以,在让大家动手完成这道题之前,小甲鱼介绍一点新东西给大家!
s为字符串
s.isalnum() 所有字符都是数字或者字母,为真返回 Ture,否则返回 False
s.isalpha() 所有字符都是字母,为真返回 Ture,否则返回 False
s.isdigit() 所有字符都是数字,为真返回 Ture,否则返回 False
s.islower() 所有字符都是小写,为真返回 Ture,否则返回 False
s.isupper() 所有字符都是大写,为真返回 Ture,否则返回 False
好了,文字教程就到这里,大家赶紧趁热打铁,改造我们的小游戏吧!
# Design the game, guess a number, try maximum 3 times import random print("This is the game program") secret = random.randint(1, 10) guess = 0 count = 3 while count > 0 and guess != secret: temp = input("please input a number:") ## 判断输入格式是否正确 while not temp.isdigit(): temp = input("your input is not a number, please input again, please input a correct number:") guess = int(temp) if guess > secret: print("your guess number is big, input a smaller one") else: print("your input number is small, input a bigger one") count = count - 1 if guess == secret: print('your guess is exactly right!! Congrats!') else: print('You already tried three times, game over!')
-
写一个程序,判断给定年份是否为闰年。(注意:请使用已学过的 BIF 进行灵活运用)
这样定义闰年的:能被4整除但不能被100整除,或者能被400整除都是闰年。
# 判断闰年 # 能被4整除但不能被100整除,或者能被400整除都是闰年。 temp = input('清输入一个年份:') while not temp.isdigit(): temp = input('输入的不是年份,清重新输入:') year = int(temp) # 采用取余数的方法 if (year % 4 == 0) and (year % 100 != 0): print('%d 是闰年' % year) else: if year % 400 == 0: print('%d 是闰年' % year) else: print('%d 不是闰年' % year)
-
请写下这一节课你学习到的内容:格式不限,回忆并复述是加强记忆的好方式!
参考知识点总结内容
>>> a = b = c = d = 10
>>> a += 1
>>> b -= 3
>>> c *= 10
>>> d /= 8
>>> a
11
>>> b
7
>>> c
100
>>> d
1.25
-
幂运算: **
-
地板除法://
python3.0
/总是执行真除法,不管操作数的类型,都返回浮点数结果(即使能整除,如4/2==2.0); //执行Floor除法,会截断余数直接返回一个整数,如果有任何一个操作数是浮点数则返回浮点数(如4//2==2,3//2==1, 4.0//2==2.0)
总之:在python3.0中,/为真除法,不会截断,且结果无论能否整除都是浮点数;//为地板除法,会对除法的结果进行取整返回,至于返回的结果是否是浮点数取决于操作数中有无浮点数,如两个操作数都是整数那么就直接返回一个取整后的整数,如果操作数中有浮点数则返回结果是浮点数。
python2.0
/表示传统除法,如果两个操作数都是整数的话执行截断除法,否则执行浮点除法,//执行Floor除法,同3.0
-
先乘除后加减,遇到括号先算括号
>>> -3 * 2 + 5 / -2 -4 -12.5 -
比较操作符优先级大于逻辑操作符
>>> 3 < 4 and 4 < 5 True -
加括号让代码可读性更高
>>> (3 < 4 ) and ( 4 < 5 ) True -
幂预算操作符比起左侧运算符优先级高,比其右侧操作符优先级低
>>> - 3 ** 2 -9 >>> -(3 ** 2) -9 >>> 3 ** -2 0.1111111111111111 >>> 3 ** (-2) 0.1111111111111111
- and
- or
- not
not or and 的优先级是不同的:not > and > or
逻辑操作符有个有趣的特性:在不需要求值的时候不进行操作。这么说可能比较“高深”,举个例子,表达式 x and y,需要 x 和 y 两个变量同时为真(True)的时候,结果才为真。因此,如果当 x 变量得知是假(False)的时候,表达式就会立刻返回 False,而不用去管 y 变量的值。 这种行为被称为短路逻辑(short-circuit logic)或者惰性求值(lazy evaluation),这种行为同样也应用与 or 操作符
首先,and’、‘or’和‘not’的优先级是not>and>or
其次,逻辑操作符and 和or 也称作短路操作符(short-circuitlogic)或者惰性求值(lazy evaluation):
它们的参数从左向右解析,一旦结果可以确定就停止。
and :x and y 返回的结果是决定表达式结果的值。如果 x 为真,则 y 决定结果,返回 y ;如果 x 为假,x 决定了结果为假,返回 x。
由于是短路操作符,是因为and运算符必须所有的运算数都是true才会把所有的运算数都解析,并且返回最后一个变量,
>>> 3 and 4
4
>>> 4 and 3
3
>>> 0 and 3
0
>>> 3 and 0
0
or : x or y 逻辑(or),即只要有一个是true,即停止解析运算数,返回最近为true的变量,
>>> 3 or 4
3
>>> 4 or 3
4
>>> 3 or 0
3
>>> 0 or 3
3
not : 返回表达式结果的“相反的值”。如果表达式结果为真,则返回false;如果表达式结果为假,则返回true。
>>> not 3
False
>>> not 0
True

-
Python 的 floor 除法现在使用 “//” 实现,那 3.0 // 2.0 您目测会显示什么内容呢?
1.0; 有任何一个操作数是浮点数则返回结果为浮点数
-
a < b < c 事实上是等于?
a < b and b < c
-
不使用 IDLE,你可以轻松说出 5 ** -2 的值吗?
0.04
-
如何简单判断一个数是奇数还是偶数?
a % 2 == 0 ; a % 2 == 1
-
请用最快速度说出答案:not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9
not or and 的优先级是不同的:not > and > or
>>> not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9 4 >>> >>> (not 1) or (0 and 1) or (3 and 4) or (5 and 6) or (7 and 8 and 9) 4 -
还记得我们上节课那个求闰年的作业吗?如果还没有学到“求余”操作,还记得用什么方法可以“委曲求全”代替“%”的功能呢?
# 判断闰年 # 能被4整除但不能被100整除,或者能被400整除都是闰年。 temp = input('清输入一个年份:') while not temp.isdigit(): temp = input('输入的不是年份,清重新输入:') year = int(temp) if (year/4 == int(year/4)) and (year/100 != int(year/100)): print('%d 是闰年' % year) else: if year/400 == int(year/400): print('%d 是闰年' % year) else: print('%d 不是闰年' % year)
-
请写一个程序打印出 0~100 所有的奇数。
# 打印出 0~100 所有的奇 number = 0 while number <= 100: if number % 2 == 1: print(number) number += 1
-
我们说过现在的 Python 可以计算很大很大的数据,但是......真正的大数据计算可是要靠刚刚的硬件滴,不妨写一个小代码,让你的计算机为之崩溃?
-
爱因斯坦曾出过这样一道有趣的数学题:有一个长阶梯,若每步上2阶,最后剩1阶;若每步上3阶,最后剩2阶;若每步上5阶,最后剩4阶;若每步上6阶,最后剩5阶;只有每步上7阶,最后刚好一阶也不剩。 (小甲鱼温馨提示:步子太大真的容易扯着蛋~~~)
题目:请编程求解该阶梯至少有多少阶?
119 级
# 爱因斯坦曾出过这样一道有趣的数学题:有一个长阶梯,若每步上2阶,最后剩1阶;若每步上3阶,最后剩2阶;若每步上5阶,最后剩4阶;若每步上6阶,最后剩5阶;只有每步上7阶,最后刚好一阶也不剩。 # 设定初始值为7级台阶 stage = 7 # 算出的符合条件的结果,当为1 的时候,表示第一个算出的,也是至少有多少级台阶 result = 0 while stage > 0 and result != 1: if (stage % 7 == 0) and (stage % 2 == 1) and (stage % 5 == 4) and (stage % 6 == 5): print('至少有 %d 级台阶' % stage) result = 1 stage += 7
- 判断: 该不该做某事; if... else; if...elif....else
- 循环: 持续的做某事; while 循环,for 循环
按照100分制,90分以上成绩为A, 80到90为B,60到80为C,60以下为D,写一个程序,当用户输入分数,自动转换为ABCD的形式打印。
-
程序-1
score = int(input('请输入一个分数:')) if 100 >= score >= 90: print('A') if 90 > score >= 80: print('B') if 80 > score >= 60: print('C') if 60 > score >= 0: print('D') if score < 0 or score > 100: print('输入错误!')
-
程序-2
score = int(input('请输入一个分数:')) if 100 >= score >= 90: print('A') else: if 90 > score >= 80: print('B') else: if 80 > score >= 60: print('C') else: if 60 > score >= 0: print('D') else: print('输入错误!')
-
程序-3
score = int(input('请输入一个分数:')) if 100 >= score >= 90: print('A') elif 90 > score >= 80: print('B') elif 80 > score >= 60: print('C') elif 60 > score >= 0: print('D') else: print('输入错误!')
-
应该考虑程序的高效性; if and elif....; 程序-1 所有的if 每次都要执行一遍,效率低下; 程序-3 体现了python的简洁和可读性好
-
Python 可以有效避免“悬挂” else
-
什么是“悬挂else”
-
我们举个例子,初学C语言的朋友可能很容易被以下代码欺骗:C 语言采用就近if。。。else 匹配原则
if ( hi > 2 ) if ( hi > 7 ) printf( "好棒!好棒!" ); else print( "切~" );
-
Python 采用强制规定锁进原则,否则程序无法跑起来,给程序猿自己决定if-else 搭配
-
-
条件表达式(三元操作符)
有了这个三元操作符的条件表达式,你可以使用一条语句来完成以下的条件判断和赋值操作:
x, y = 4, 5 if x > y: small = x else: small = y # 这个例子可以改进为 small = x if x < y else y
-
断言 (assert)
assert 这个关键字我们称之为断言,当这个关键字后面的条件为假的时候,程序自动崩溃并抛出AssertionError的异常。
举个例子:
>>> assert 3 > 4 Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError
一般来说我们可以用它再程序中置入检查点,当需要确保程序中的某个条件一定为真才能让程序正常工作的话,assert 关键字就非常有用了
-
if not (money < 100): 上边这行代码相当于?
if money >= 100
-
assert 的作用是什么?
在程序中置入检查点,当需要确保程序中的某个条件一定为真才能让程序正常工作的话,assert 关键字就非常有用
-
假设有 x = 1,y = 2,z = 3,请问如何快速将三个变量的值互相交换?
x, y, z = z, y, x
-
猜猜 (x < y and [x] or [y])[0] 实现什么样的功能?
三元运算的功能, 相当于 = [x] if x < y else [y]
-
你听说过成员资格运算符吗?
in 运算符
-
视频中小甲鱼使用 if elif else 在大多数情况下效率要比全部使用 if 要高,但根据一般的统计规律,一个班的成绩一般服从正态分布,也就是说平均成绩一般集中在 70~80 分之间,因此根据统计规律,我们还可以改进下程序以提高效率
题目备忘:按照100分制,90分以上成绩为A,80到90为B,60到80为C,60以下为D,写一个程序,当用户输入分数,自动转换为ABCD的形式打印。
score = int(input('请输入一个分数:'))
if 80 > score >= 60:
print('C')
elif 90 > score >= 80:
print('B')
elif 60 > score >= 0:
print('D')
elif 100 >= score >= 90:
print('A')
else:
print('输入错误!')-
Python 的作者在很长一段时间不肯加入三元操作符就是怕跟C语言一样搞出国际乱码大赛,蛋疼的复杂度让初学者望而生畏,不过,如果你一旦搞清楚了三元操作符的使用技巧,或许一些比较复杂的问题反而迎刃而解。 请将以下代码修改为三元操作符实现:
x, y, z = 6, 5, 4 if x < y: small = x if z < small: small = z elif y < z: small = y else: small = z
可以改为:
small = x if (x < y and z >= x) else (y if y < z else z)- 请写下这一节课你学习到的内容:格式不限,回忆并复述是加强记忆的好方式!
虽然说pytohn 是由C 语言编写而来,但是他的for 循环跟C 语言循环不太一样,python的for 循环会自动捕获iteration 异常并且结束循环,因此显得更为智能和强大
- range()
- 语法:range(start, stop[, step=1])
- 这个BIF 有三个参数,其中用中括号括起来的两个表示的参数是可选的
- step=1 表示第三个参数的值默认是1
- range这个BIF的作用是生成一个从start 参数的值开始到stop 参数的值结束的数字序列
- break 用来终止这一层的循环,跳出
- continue 用来终止本轮循环,开始下一轮循环
- Break 和 Continue 都只能影响一层
-
下面的循环会打印多少次"I Love FishC"?
for i in range(0, 10, 2): print('I Love FishC')
5次
-
下面的循环会打印多少次"I Love FishC"?
for i in 5: print('I Love FishC')
0次, "TypeError: 'int' object is not iterable"
-
回顾一下 break 和 continue 在循环中起到的作用?
Break 是终止循环,跳出循环体; Continue 是结束本次循环,立即开始下次循环
-
请谈下你对列表的理解?
列表本质上是一个可迭代器
-
请问 range(10) 生成哪些数?
0,1,2, 3, 4,5 ,6,7 ,8, 9
-
目测以下程序会打印什么?
while True: while True: break print(1) print(2) break print(3)
2
3
-
什么情况下我们要使循环永远为真?
保证循环体的内容一定要执行的情况下
-
【学会提高代码的效率】你的觉得以下代码效率方面怎样?有没有办法可以大幅度改进(仍然使用while)?
i = 0 string = 'ILoveFishC.com' while i < len(string)): print(i) i += 1
# 修改后的程序,避免每次循环都要run 一次len() 函数 string = 'ILoveFishC.com' count = len(string) i = 0 while i < count: print(i) i += 1
-
设计一个验证用户密码程序,用户只有三次机会输入错误,不过如果用户输入的内容中包含**"*"**则不计算在内。
# 设计一个验证用户密码程序,用户只有三次机会输入错误,不过如果用户输入的内容中包含**"\*"**则不计算在内。 password = "novirus" count = 0 while True: if count <= 2: userInputPass = input('please input the password:') if userInputPass == password: print('your password input is correct! Congrats!') break else: if '*' not in userInputPass: count += 1 print('your password input is incorrect, please input again!') else: print('you already input 3 times, the password input is frozen!') break
# 优化一下上述程序 password = "novirus" count = 3 while True: if count > 0: userInputPass = input('please input the password:') if userInputPass == password: print('your password input is correct! Congrats!') break elif '*' not in userInputPass: count -= 1 print('your password input is incorrect, you have %d tries left' % count) else: print('your password input is incorrect, you have %d tries left' % count) continue else: print('you already input 3 times, the password input is frozen!') break
## 进一步优化 password = "novirus" count = 3 while count: userInputPass = input('please input the password:') if userInputPass == password: print('your password input is correct! Congrats!') break elif '*' in userInputPass: print('your password input is incorrect, you have %d tries left' % count ) continue else: print('your password input is incorrect, you have %d tries left' % (count-1)) count -= 1
-
编写一个程序,求 100~999 之间的所有水仙花数。
如果一个 3 位数等于其各位数字的立方和,则称这个数为水仙花数。例如:153 = 1^3 + 5^3 + 3^3,因此 153 就是一个水仙花数。
# 1. 编写一个程序,求 100~999 之间的所有水仙花数。
#
# > 如果一个 3 位数等于其各位数字的立方和,则称这个数为水仙花数。例如:153 = 1^3 + 5^3 + 3^3,因此 153 就是一个水仙花数。
for number in range(100, 1000):
hundreds = number // 100
tens = (number // 10) % 10
single = number % 10
if number == hundreds ** 3 + tens ** 3 + single ** 3:
print(number, end=' ')# 另外一种方法,通过字符串和整型的互相转换
for number in range(100, 1000):
numstr = str(number)
if number == int(numstr[0])**3 + int(numstr[1])**3 + int(numstr[2])**3:
print(number, end=' ')- 三色球问题
有红、黄、蓝三种颜色的求,其中红球 3 个,黄球 3 个,蓝球 6 个。先将这 12 个球混合放在一个盒子中,从中任意摸出 8 个球,编程计算摸出球的各种颜色搭配。
# 3. 三色球问题
#
# > 有红、黄、蓝三种颜色的求,其中红球 3 个,黄球 3 个,蓝球 6 个。先将这 12 个球混合放在一个盒子中,从中任意摸出 8 个球,编程计算摸出球的各种颜色搭配。
# x + y + z = 8
# x is red, y is yellow, z is blue
for x in range(0, 4):
for y in range(0, 4):
for z in range(2, 7):
if x + y + z == 8:
print('totally we can have %d red, %d yellow, %d blue' % (x, y, z))- 请写下这一节课你学习到的内容:格式不限,回忆并复述是加强记忆的好方式!
- 创建一个普通列表
- 创建一个混合列表
- 创建一个空列表
>>> member = ['小布丁', '小甲鱼']
>>>
>>> member
['小布丁', '小甲鱼']
>>> type(member)
<class 'list'>
>>>
>>>
>>> number = [1, 2, 3, 4]
>>>
>>> number
[1, 2, 3, 4]
>>>
>>>
>>> mix = [1, '小甲鱼', 3.14, [1, 2, 3] ]
>>>
>>> mix
[1, '小甲鱼', 3.14, [1, 2, 3]]
>>>
>>>
>>> empty = []
>>>
>>> empty
[]-
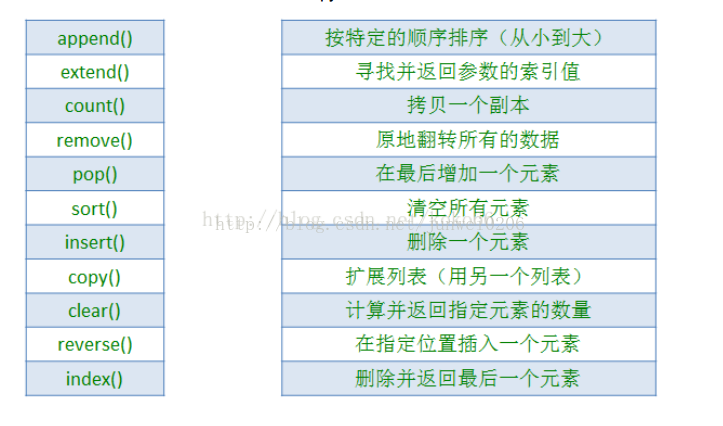
append()
>>> member.append('福禄娃娃') >>> >>> member ['小布丁', '小甲鱼', '福禄娃娃'] >>> >>> len(member) 3 -
extend()
>>> member.extend(['竹林小溪', 'crybaby']) >>> >>> member ['小布丁', '小甲鱼', '福禄娃娃', '竹林小溪', 'crybaby'] >>> >>> len(member) 5 -
insert()
>>> member.insert(0, '牡丹') >>> >>> member ['牡丹', '小布丁', '小甲鱼', '福禄娃娃', '竹林小溪', 'crybaby'] >>> >>> len(member) 6
append() 和 extend() 只有一个参数,默认都是添加到列表的末尾
extend() 是用一个列表追加另一个列表,所以参数是一个列表
insert() 第一个参数是插入位置
-
列表都可以存放一些什么东西?
整数,浮点数,字符串,对象
-
向列表增加元素有哪些方法?
append(), extend(), insert()
-
append() 方法和 extend() 方法都是向列表的末尾增加元素,请问他们有什么区别?
extend() 的参数是列表
-
member.append(['竹林小溪', 'Crazy迷恋']) 和 member.extend(['竹林小溪', 'Crazy迷恋']) 实现的效果一样吗?
不一样,append 增加的是一个元素:1个列表对象; extend 增加的是2个元素:列表中的2个元素
-
有列表 name = ['F', 'i', 'h', 'C'],如果小甲鱼想要在元素 'i' 和 'h' 之间插入元素 's',应该使用什么方法来插入?
name.insert(2, 's')
- 自己动手试试看,并分析在这种情况下,向列表添加数据应当采用哪种方法比较好?
假设给定以下列表:
member = ['小甲鱼', '黑夜', '迷途', '怡静', '秋舞斜阳']
要求将列表修改为:
member = ['小甲鱼', 88, '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88]
方法一:使用 insert() 和 append() 方法修改列表。
方法二:重新创建一个同名字的列表覆盖。
# 方法一
member = ['小甲鱼', '黑夜', '迷途', '怡静', '秋舞斜阳']
index = 1
member.insert(1, 88)
member.insert(3, 90)
member.insert(5, 85)
member.insert(7, 90)
member.append(88)
print(member)# 方法二:
member = ['小甲鱼', '黑夜', '迷途', '怡静', '秋舞斜阳']
number = [88, 90, 85, 90, 88]
new = []
index = 0
while index < len(member):
new.extend([member[index], number[index]])
index += 1
member = new
print(member)- 利用 for 循环打印上边 member 列表中的每个内容,如图:
![member = ['小甲鱼', 88, '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88]](https://img-blog.csdnimg.cn/20200330223209818.png)
member = ['小甲鱼', 88, '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88]
for i in member:
print(i)- 上一题打印的样式不是很好,能不能修改一下代码打印成下图的样式呢?【请至少使用两种方法实现】

# 上一题打印的样式不是很好,能不能修改一下代码打印成下图的样式呢?【请至少使用两种方法实现】
# 方法一
member = ['小甲鱼', 88, '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88]
lenth = len(member)
for i in range(0, lenth, 2):
print(member[i], member[i+1])# 方法二
member = ['小甲鱼', 88, '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88]
for each in range(len(member)):
if each % 2 == 0:
print(member[each], member[each+1])通过索引值index 获取单个元素,从0开始
>>> member = ['小甲鱼', 88, '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88]
>>> member[0]
'小甲鱼'
>>>
>>> member[1]
88
>>>
# 交换数组元素
>>> temp = member[0]
>>>
>>> member[0] = member[1]
>>>
>>> member[1] = temp
>>>
>>> member
[88, '小甲鱼', '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88]-
remove() ; 参数是具体的存在于列表中的元素值,不需要知道位置
>>> member.remove('小甲鱼') >>> >>> member [88, '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88] >>> >>> member.remove('小甲鱼') Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: list.remove(x): x not in list
-
del
- del <列表名字>;del member , 会删除整个列表
- del <列表元素>; del member[0], 删除某个特定的列表元素
>>> member [88, '黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88] >>> >>> >>> del member[0] >>> >>> member ['黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88] >>> >>> >>> del member >>> >>> member Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'member' is not defined
-
pop()
- 列表是通过栈存储数据的,可以通过pop 来弹栈数据
- 不加任何参数,默认从列表中取出最后一个元素,并且弹出来
- 可以加上参数index,弹出具体某个元素
>>> member = ['黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88] >>> member ['黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳', 88] >>> member.pop() 88 >>> >>> member ['黑夜', 90, '迷途', 85, '怡静', 90, '秋舞斜阳'] >>> name = member.pop() >>> >>> name '秋舞斜阳' >>> >>> member ['黑夜', 90, '迷途', 85, '怡静', 90] >>> member.pop(1) 90 >>> >>> member ['黑夜', '迷途', 85, '怡静', 90]
-
利用索引可以每次获取一个元素;但是如果需要每次获取多个元素,需要采用列表分片
-
利用列表分片,得到一个列表的拷贝,返回值是列表
-
列表分片操作,原列表不会有任何改变
>>> member ['黑夜', '迷途', 85, '怡静', 90] >>> member[1:3] ['迷途', 85] >>> >>> member ['黑夜', '迷途', 85, '怡静', 90] >>> member[:3] ['黑夜', '迷途', 85] >>> >>> member[1:] ['迷途', 85, '怡静', 90] >>> >>> member[:] ['黑夜', '迷途', 85, '怡静', 90]
-
下边的列表分片操作会打印什么内容? list1 = [1, 3, 2, 9, 7, 8] list1[2:5]
[2, 9, 7]
-
请问 list1[0] 和 list1[0:1] 一样吗?
不一样,list1[0] 是一个元素:1, list[0:1] 是一个列表:[1]
-
如果你每次想从列表的末尾取出一个元素,并将这个元素插入到列表的最前边,你会怎么做?
list.insert(0, list.pop())
-
有些鱼油比较调皮,他说我想试试 list1[-3:-1] 会不会报错,怎么知道一试居然显示 [9, 7],这是怎么回事呢?
Python 列表逆向切片,从右至左
-
在进行分片的时候,我们知道分片的开始和结束位置需要进行指定,但其实还有另外一个隐藏的设置:步长。 list1[0:6:2]
-
简洁分片操作: list1[::2]
-
步长不能为0,会报错 list1 = [1, 3, 2, 9, 7, 8] list1 = [ : : 0 ]
-
步长可以是负数,改变方向(从尾部开始向左走) list1[::-2]
>>> list1[0:6:2] [1, 2, 7] >>> >>> list1[::2] [1, 2, 7] >>> >>> list=[::0] File "<stdin>", line 1 list=[::0] ^ SyntaxError: invalid syntax >>> >>> list1[::-2] [8, 9, 3]
-
-
课堂上小甲鱼说可以利用分片完成列表的拷贝 list2 = list1[:],那事实上可不可以直接写成 list2 = list1 更加简洁呢?
不能,list2 = list1 并没有拷贝数据存储在内存中,而是给同一份内存数据加上了一个新的标签:list2
list1 = [1, 3, 2, 9, 7, 8]
list2 = list1[:]
list2
[1, 3, 2, 9, 7, 8]
list3 = list1
list3
[1, 3, 2, 9, 7, 8]
list1.sort()
list1
[1, 2, 3, 7, 8, 9]
list2
[1, 3, 2, 9, 7, 8]
list3
[1, 2, 3, 7, 8, 9] 6.请写下这一节课你学习到的内容:格式不限,回忆并复述是加强记忆的好方式
-
比较操作符
列表比较,当有多个元素的时候,默认从第0个元素开始比较
>>> list1 = [123] >>> list2 = [234] >>> list1 > list2 False >>> >>> list1 = [123, 456] >>> list2 = [234, 123] >>> >>> list1 > list2 False
-
逻辑操作符
>>> list3 = [123, 456] >>> >>> (list1 < list2) and (list1 == list3) True -
连接操作符
类似于extend(),但是不建议使用 + 来扩展或添加列表元素,建议使用insert,append,extend
>>> list4 = list1 + list2 >>> list4 [123, 456, 234, 123] -
重复操作符
>>> list3 * 3 [123, 456, 123, 456, 123, 456] >>> >>> list3 *= 3 >>> list3 [123, 456, 123, 456, 123, 456] >>> >>> >>> >>> list3 *= 5 >>> list3 [123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456] -
成员关系操作符
- 列表中的列表的操作
>>> 123 in list3 True >>> 'xiaojiayu' not in list3 True >>> 123 not in list3 False >>> >>> list5 = [123, ['xiaojiayu', 'mudan'], 456] >>> 'xiaojiayu' in list5 False >>> 'xiaojiayu' in list5[1] True >>> >>> list5[1][1] 'mudan'
>>> dir(list)
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']-
reverse(): 将整个列表反转
>>> list3.reverse() >>> list3 [456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123, 456, 123] -
sort(): 用指定的方式,对成员排序,默认是从小到大
>>> list6 = [4, 2, 3, 5, 9, 8, 10] >>> list6.sort() >>> >>> list6 [2, 3, 4, 5, 8, 9, 10] >>> >>> list6.sort(reverse=True) >>> list6 [10, 9, 8, 5, 4, 3, 2] -
count(): 计算一个元素在列表中出现的次数
>>> list3.count(123) 15 -
index(): 返回参数在列表中的位置
>>> list3.index(123) 0 >>> >>> list3.index(123, 3, 7) 4
- 请问如何将下边这个列表的'小甲鱼'修改为'小鱿鱼'?
list1 = [1, [1, 2, ['小甲鱼']], 3, 5, 8, 13, 18]
list1[1][2][0] = '小鱿鱼'
-
要对一个列表进行顺序排序,请问使用什么方法?
list.sort()
-
要对一个列表进行逆序排序,请问使用什么方法?
list.sort(reverse=true) 或者: list.sort() list.reverse() -
列表还有两个内置方法没给大家介绍,不过聪明的你应该可以自己摸索使用的门道吧:copy() 和 clear()
>>> list7 = list6.copy()
>>>
>>>
>>>
>>> list7
[4, 2, 3, 5, 9, 8, 10]
>>>
>>>
>>> list6.sort()
>>> list6
[2, 3, 4, 5, 8, 9, 10]
>>> list7
[4, 2, 3, 5, 9, 8, 10]
>>> list7.clear()
>>>
>>> list7
[]
- 你有听说过列表推导式或列表解析吗? 没听过?!没关系,我们现场来学习一下吧,看表达式:
>>> [ i*i for i in range(10) ]
>>> [i*i for i in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
你觉得会打印什么内容?
居然分别打印了0到9各个数的平方,然后还放在列表里边了有木有?!
列表推导式(List comprehensions)也叫列表解析,灵感取自函数式编程语言 Haskell。Ta 是一个非常有用和灵活的工具,可以用来动态的创建列表,语法如: [有关A的表达式 for A in B]
例如
>>> list1 = [x**2 for x in range(10)]
>>> list1
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
相当于
list1 = []
for x in range(10):
list1.append(x**2)
问题:请先在 IDLE 中获得下边列表的结果,并按照上方例子把列表推导式还原出来。
list1 = [(x, y) for x in range(10) for y in range(10) if x%2==0 if y%2!=0]
>>> for x in range(10):
... for y in range(10):
... if x%2==0 and y%2!=0:
... list1.append((x, y))
...
>>> list1
[(0, 1), (0, 3), (0, 5), (0, 7), (0, 9), (2, 1), (2, 3), (2, 5), (2, 7), (2, 9), (4, 1), (4, 3), (4, 5), (4, 7), (4, 9), (6, 1), (6, 3), (6, 5), (6, 7), (6, 9), (8, 1), (8, 3), (8, 5), (8, 7), (8, 9)]- 活学活用:请使用列表推导式补充被小甲鱼不小心涂掉的部分

list3=[y + ":" + x[2:] for x in list1 for y in list2 if x[0] == y[0]]-
由于和列表是近亲关系,所以元组和列表在实际使用上是非常相似的。
-
元组可以切片,但是元组是不可改变的,不能随意插入修改元素
>>> tuple1 = (1, 2, 3, 4, 5, 6, 7, 8) >>> type(tuple1) <class 'tuple'> >>> >>> >>> tuple1 (1, 2, 3, 4, 5, 6, 7, 8) >>> >>> tuple1[1] 2 >>> >>> tuple1[5:] (6, 7, 8) >>> >>> tuple2 = tuple1[:] >>> >>> tuple2 (1, 2, 3, 4, 5, 6, 7, 8) >>> >>> tuple1[1] = 3 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> -
主要讨论以下知识点:
-
创建和访问一个元组; 逗号是定义一个元组的关键,而不是小括号
>>> temp = (1) >>> temp 1 >>> >>> type(temp) <class 'int'> >>> >>> temp2 = 2, 3, 4 >>> >>> temp2 (2, 3, 4) >>> >>> type(temp2) <class 'tuple'> >>> >>> temp = () >>> type(temp) <class 'tuple'> >>> temp () >>> >>> temp = (1, ) >>> type(temp) <class 'tuple'> >>> >>> temp (1,) >>> >>> temp = 1, >>> temp (1,) >>> type(temp) <class 'tuple'> -
更新和删除一个元组
通过连接符来修改一个元组,注意修改完之后,原来的元组还在内存中,过一会python 会检查是否还有标签(变量名)指向它,如果没有,会从内存中回收它
>>> temp = ('小甲鱼', '小布丁', '迷途', '黑夜') >>> temp ('小甲鱼', '小布丁', '迷途', '黑夜') >>> >>> temp = temp[:2] + ('怡静', ) + temp[2:] >>> >>> temp ('小甲鱼', '小布丁', '怡静', '迷途', '黑夜')如果要强行回收资源,可以使用del 语法
>>> del temp >>> >>> temp Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'temp' is not defined
-
-
列表的操作符和元组一样
-
请用一句话描述什么是列表?再用一句话描述什么是元组?
列表:一个大仓库,你可以随时往里边添加和删除任何东西。
元组:封闭的列表,一旦定义,就不可改变(不能添加、删除或修改)
-
什么情况下你需要使用元组而不是列表?
当我们希望内容不被轻易改写的时候,我们使用元组(把权力关进牢笼)。 当我们需要频繁修改数据,我们使用列表。
-
当元组和列表掉下水,你会救谁?
如果是我,我会救列表,因为列表提供了比元组更丰富的内置方法,这相当大的提高了编程的灵活性。
回头来看下元组,元组固然安全,但元组一定创建就无法修改(除非通过新建一个元组来间接修改,但这就带来了消耗),而我们人是经常摇摆不定的,所以元组只有在特殊的情况才用到,平时还是列表用的多。 综上所述,小甲鱼会救列表(列表是美眉)
-
请将下图左边列表的内置方法与右边的注释连线,并圈出元组可以使用的方法。
元组只能使用2个方法:count()和index()
-
创建一个元组,什么情况下逗号和小括号必须同时存在,缺一不可?
在通过拼接符创建元组的时候
-
x, y, z = 1, 2, 3 请问x, y, z是元组吗?
所有的多对象的、逗号分隔的、没有明确用符号定义的这些集合默认的类型都是元组
>>> x, y, z = 1, 2, 3 >>> >>> type(x) <class 'int'> >>> >>> h = x, y, z >>> type(h) <class 'tuple'> -
请写出以下情景中应该使用列表还是元组来保存数据:
- 游戏中角色的属性: 列表
- 你的身份证信息: 元组
- 论坛的会员: 列表
- 团队合作开发程序,传递给一个你并不了解具体实现的函数的参数:元组
- 航天火箭各个组件的具体配置参数: 元组
- NASA系统中记录已经发现的行星数据: 列表
-
上节课我们通过课后作业的形式学习到了“列表推导式”,那请问如果我把中括号改为小括号,会不会得到“元组推导式”呢?
不能,因为元组不能向列表一样迭代更新
- 字符串, 列表,元组 都属于序列类型,很多用法非常类似
- 字符串更像元组,一旦被定义,就不能修改。非要“修改”的话,可以参考元组的方式,采用拼接符“+” 的方式,注意旧的字符串还在,并没有改变
- 字符串和列表,元组一样可以索引,切片操作
- 字符串和列表,元组一样,使用比较操作符,逻辑操作符,成员关系操作符,连接操作符,重复操作符
{filename: }
字符串的方法不会改变原来的字符串,一般都是返回一个新的字符串
| capitalize() | 把字符串的第一个字符改为大写 |
|---|---|
| casefold() | 把整个字符串的所有字符改为小写 |
| center(width) | 将字符串居中,并使用空格填充至长度 width 的新字符串 |
| count(sub[, start[, end]]) | 返回 sub 在字符串里边出现的次数,start 和 end 参数表示范围,可选。 |
| encode(encoding=‘utf-8’, errors=‘strict’) | 以 encoding 指定的编码格式对字符串进行编码。 |
| endswith(sub[, start[, end]]) | 检查字符串是否以 sub 子字符串结束,如果是返回 True,否则返回 False。start 和 end 参数表示范围,可选。 |
| expandtabs([tabsize=8]) | 把字符串中的 tab 符号(\t)转换为空格,如不指定参数,默认的空格数是 tabsize=8。 |
| find(sub[, start[, end]]) | 检测 sub 是否包含在字符串中,如果有则返回索引值,否则返回 -1,start 和 end 参数表示范围,可选。 |
| index(sub[, start[, end]]) | 跟 find 方法一样,不过如果 sub 不在 string 中会产生一个异常。 |
| isalnum() | 如果字符串至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False。 |
| isalpha() | 如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。 |
| isdecimal() | 如果字符串只包含十进制数字则返回 True,否则返回 False。 |
| isdigit() | 如果字符串只包含数字则返回 True,否则返回 False。 |
| islower() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回 True,否则返回 False。 |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True,否则返回 False。 |
| isspace() | 如果字符串中只包含空格,则返回 True,否则返回 False。 |
| istitle() | 如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回 True,否则返回 False。 |
| isupper() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回 True,否则返回 False。 |
| join(sub) | 以字符串作为分隔符,插入到 sub 中所有的字符之间。 |
| ljust(width) | 返回一个左对齐的字符串,并使用空格填充至长度为 width 的新字符串。 |
| lower() | 转换字符串中所有大写字符为小写。 |
| lstrip() | 去掉字符串左边的所有空格 |
| partition(sub) | 找到子字符串 sub,把字符串分成一个 3 元组 (pre_sub, sub, fol_sub),如果字符串中不包含 sub 则返回 (‘原字符串’, ‘’, ‘’) |
| replace(old, new[, count]) | 把字符串中的 old 子字符串替换成 new 子字符串,如果 count 指定,则替换不超过 count 次。 |
| rfind(sub[, start[, end]]) | 类似于 find() 方法,不过是从右边开始查找。 |
| rindex(sub[, start[, end]]) | 类似于 index() 方法,不过是从右边开始。 |
| rjust(width) | 返回一个右对齐的字符串,并使用空格填充至长度为 width 的新字符串。 |
| rpartition(sub) | 类似于 partition() 方法,不过是从右边开始查找。 |
| rstrip() | 删除字符串末尾的空格。 |
| split(sep=None, maxsplit=-1) | 不带参数默认是以空格为分隔符切片字符串,如果 maxsplit 参数有设置,则仅分隔 maxsplit 个子字符串,返回切片后的子字符串拼接的列表。 |
| splitlines(([keepends])) | 在输出结果里是否去掉换行符,默认为 False,不包含换行符;如果为 True,则保留换行符。。 |
| startswith(prefix[, start[, end]]) | 检查字符串是否以 prefix 开头,是则返回 True,否则返回 False。start 和 end 参数可以指定范围检查,可选。 |
| strip([chars]) | 删除字符串前边和后边所有的空格,chars 参数可以定制删除的字符,可选。 |
| swapcase() | 翻转字符串中的大小写。 |
| title() | 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。 |
| translate(table) | 根据 table 的规则(可以由 str.maketrans(‘a’, ‘b’) 定制)转换字符串中的字符。 |
| upper() | 转换字符串中的所有小写字符为大写。 |
| zfill(width) | 返回长度为 width 的字符串,原字符串右对齐,前边用 0 填充。 |
>>> str1.capitalize()
'Abdc'
>>> str1
'abdc'
>>> str1.center(2)
'abdc'
>>> str1
'abdc'
>>> str1.center(12)
' abdc '
>>> str1.casefold()
'abdc'
>>> str2 = 'DAXDIExiaoyang'
>>>
>>> str2.count('xi')
1
>>> str2.endswith('ng')
True
>>>
>>> str3 = 'I\tlove\tFishC.com!'
>>> str3.expandtabs()
'I love FishC.com!'
>>> str3
'I\tlove\tFishC.com!'
>>> print(str3)
I love FishC.com!
>>> str3 = 'I\tlove\tFishC.com!'
>>>
>>> print(str3)
I love FishC.com!
>>> str3.expandtabs(tabsize=18)
'I love FishC.com!'
>>> str3.find('efc')
-1
>>>
>>> str3.find('com')
13
>>> str3.index('efc')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
>>> str4 = 'FishC'
>>>
>>> str4.join('12345')
'1FishC2FishC3FishC4FishC5'
>>> str5 = ' i love you '
>>> str5.lstrip()
'i love you '
>>> str5
' i love you '
>>> str5.rstrip()
' i love you'
>>>
>>> str6 = 'l love fish'
>>> str6.partition('ov')
('l l', 'ov', 'e fish')
>>>
>>> str6
'l love fish'
>>> str6.replace('fish', 'felix')
'l love felix'
>>> str6
'l love fish'
>>> str6.split()
['l', 'love', 'fish']
>>> str6.split('i')
['l love f', 'sh']
>>> str6.startswith('I')
False
>>> str6.startswith('i')
False
>>> str6.startswith('1')
False
>>> str6
'l love fish'
>>> str6.startswith('l')
True
>>> str7 = ' aaaasssss '
>>> str7.strip()
'aaaasssss'
>>> str7 = str7.strip()
>>> str7
'aaaasssss'
>>> str7.strip('s')
'aaaa'
>>> str7.swapcase()
'AAAASSSSS'
>>>
>>> str7.title()
'Aaaasssss'
-
还记得如何定义一个跨越多行的字符串吗(请至少写出两种实现的方法)?
方法一: >>> str1 = '''待我长发及腰,将军归来可好? 此身君子意逍遥,怎料山河萧萧。 天光乍破遇,暮雪白头老。 寒剑默听奔雷,长枪独守空壕。 醉卧沙场君莫笑,一夜吹彻画角。 江南晚来客,红绳结发梢。''' 方法二: >>> str2 = '待卿长发及腰,我必凯旋回朝。\ 昔日纵马任逍遥,俱是少年英豪。\ 东都霞色好,西湖烟波渺。\ 执枪血战八方,誓守山河多娇。\ 应有得胜归来日,与卿共度良宵。\ 盼携手终老,愿与子同袍。' 方法三: >>> str3 = ('待卿长发及腰,我必凯旋回朝。' '昔日纵马任逍遥,俱是少年英豪。' '东都霞色好,西湖烟波渺。' '执枪血战八方,誓守山河多娇。' '应有得胜归来日,与卿共度良宵。' '盼携手终老,愿与子同袍。') -
三引号字符串通常我们用于做什么使用?
注释
-
file1 = open('C:\windows\temp\readme.txt', 'r') 表示以只读方式打开“C:\windows\temp\readme.txt”这个文本文件,但事实上这个语句会报错,知道为什么吗?你会如何修改?
文件名中包含默认的制表符:\t, \r... 需要指定用原始字符读取文件名,'r' 置于整个字符串的前面
>>> file1 = open(r'C:\windows\temp\readme.txt', 'r') -
有字符串:
str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'请问如何提取出子字符串:'www.fishc.com'
# 使用split() 方法可以以‘/’ 切片字符串,返回一个列表 str1.split('/')[2] 或者 # 使用partition() 方法可以直接截取,返回一个元组 str1.partition('www.fishc.com')[1] -
如果使用负数作为索引值进行分片操作,按照第三题的要求你能够正确目测出结果吗?
str1.split('/')[-3] -
还是第三题那个字符串,请问下边语句会显示什么内容?
>> str1[20:-36]
'fishc'
-
据说只有智商高于150的鱼油才能解开这个字符串(还原为有意义的字符串):
str1 = 'i2sl54ovvvb4e3bferi32s56h;$c43.sfc67o0cm99'
>>> str1[::3] 'ilovefishc.com'
- 请写一个密码安全性检查的脚本代码:check.py
密码安全性检查代码
低级密码要求:
- 密码由单纯的数字或字母组成
- 密码长度小于等于8位
中级密码要求:
- 密码必须由数字、字母或特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)任意两种组合 *
- 密码长度不能低于8位
高级密码要求:
密码必须由数字、字母及特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)三种组合
密码只能由字母开头
密码长度不能低于16位
程序演示:
specialchar = "~!@#$%^&*()_=-/,.?<>;:[]{}|\\"
while True:
alphaflag, digitflag, specharflag = 0, 0, 0
passstr = input('Please input your password: ')
# 设置标记位
for each in passstr:
if each.isalpha():
alphaflag = 1
elif each.isdigit():
digitflag = 1
elif each in specialchar:
specharflag = 1
else:
continue
if passstr[0].isalpha() and len(passstr) >= 16 and alphaflag+digitflag+specharflag == 3:
print('The password is strong!')
break
elif len(passstr) >= 8 and alphaflag+digitflag+specharflag >= 2:
print('The password is medium!')
break
elif len(passstr) < 8 and (passstr.isdigit() or passstr.isalpha()):
print('The password is weak!')
break
else:
print('The password does not meet requirement, please input again!')-
位置参数格式化
-
关键字参数格式化
-
混合位置和关键字参数格式化
- 位置参数必须在关键字参数之前
>>> "{0} love {1}.{2}".format("I", "flish", "com") 'I love flish.com' >>> >>> "{a} love {b}.{c}".format(a="I", b="flish", c="com") 'I love flish.com' >>> >>> "{0} love {b}.{c}".format("I", b="flish", c="com") 'I love flish.com' >>> >>> >>> "{a} love {b}.{0}".format(a="I", b="flish", "com") File "<stdin>", line 1 "{a} love {b}.{0}".format(a="I", b="flish", "com") ^ SyntaxError: positional argument follows keyword argument -
两个特殊的例子
-
如果要想打印格式化符号:花括号,该怎么办呢? 其实类似于加一个反斜杠避免转义字符,可以用花括号把花括号括起来
>>> print('\\') \ >>> >>> print('{{0}}'.format('不打印')) {0} >>> '{{0}}'.format('不打印') '{0}'
-
为什么下面的这个output 是27.7GB,而不是27.658GB呢?
位置参数0 后面的冒号:表示格式化符号的开始,后面接的‘.1f’ 就是格式化符号,‘.1’ 表示四舍五入,‘f’ 表示定点数
>>> '{0:.1f}{1}'.format(27.658,'GB') '27.7GB'
-
-
字符串格式化符号含义
符 号 说 明 %c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %b 格式化无符号二进制数 %o 格式化无符号八进制数 %x 格式化无符号十六进制数 %X 格式化无符号十六进制数(大写) %f 格式化定点数,可指定小数点后的精度 %e 用科学计数法格式化定点数 %E 作用同%e,用科学计数法格式化定点数 %g 根据值的大小决定使用%f活%e %G 作用同%g,根据值的大小决定使用%f或者%E >>> '%c' % 97 'a' >>> '%c %c %c' % (97, 98, 99) 'a b c' >>> >>> >>> '%s' % 'I love fishC' 'I love fishC' >>> >>> '%d + %d = %d' %(4, 5 , 4+5) '4 + 5 = 9' >>> >>> '%o' %10 '12' >>> >>> '%x' %10 'a' >>> '%X' %10 'A' >>> >>> >>> '%X' %160 'A0' >>> >>> '%f' % 27.658 '27.658000' >>> >>> >>> '%e' % 27.658 '2.765800e+01' >>> '%E' % 27.658 '2.765800E+01' >>> >>> '%g' % 27.658 '27.658' >>> '%g' % 27.65843824837284738274832784732 '27.6584' >>> '%g' % 2765843824837284738274832784732 '2.76584e+30'
-
格式化操作符辅助指令
符 号 说 明 m.n m是显示的最小总宽度,n是小数点后的位数 - 用于左对齐 + 在正数前面显示加号(+) # 在八进制数前面显示 '0o',在十六进制数前面显示 '0x' 或 '0X' 0 显示的数字前面填充 '0' 取代空格 >>> '%5.1f' %27.658 ' 27.7' >>> >>> '%.2e' %27.658 '2.77e+01' >>> >>> >>> '%10d' %5 ' 5' >>> '%-10d' %5 '5 ' >>> '%+10d' %5 ' +5' >>> '%+10d' %-5 ' -5' >>> >>> '%+-10d' %5 '+5 ' >>> >>> >>> '%#o' % 10 '0o12' >>> >>> '%#x' % 10 '0xa' >>> '%#X' % 10 '0XA' >>> >>> >>> >>> '%#d' % 10 '10' >>> '%010d' % 10 '0000000010' >>> '%-010d' % 10 '10 '
-
字符串转义字符含义
符 号 说 明 ' 单引号 " 双引号 \a 发出系统响铃声 \b 退格符 \n 换行符 \t 横向制表符(TAB) \v 纵向制表符 \r 回车符 \f 换页符 \o 八进制数代表的字符 \x 十六进制数代表的字符 \0 表示一个空字符 \ 反斜杠
-
根据说明填写相应的字符串格式化符号
符 号 说 明 %c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %o 格式化无符号八进制数 %x 格式化无符号十六进制数 %X 格式化无符号十六进制数(大写) %f 格式化定点数,可指定小数点后的精度 %e 用科学计数法格式化定点数 %E 根据值的大小决定使用%f或者%e %g 根据值的大小决定使用%F或者%E -
请问以下这行代码会打印什么内容?
>>>"{{1}}".format("不打印", "打印")
'{1}'
-
以下代码中,a, b, c是什么参数?
>>> "{a} love {b}.{c}".format(a="I", b="FishC", c="com") '
'I love FishC.com'
关键字参数
- 以下代码中,{0}, {1}, {2}是什么参数?
>>> "{0} love {1}.{2}".format("I", "FishC", "com")
'I love FishC.com'
位置参数
- 如果想要显示Pi = 3.14,format前边的字符串应该怎么填写呢?
''.format('Pi = ', 3.1415)
'{0}{1:.2f}'.format('Pi = ', 3.1415)
-
编写一个进制转换程序,程序演示如下(提示,十进制转换二进制可以用bin()这个BIF):
number = input('请输入一个整数(输入Q结束程序):')
while True:
if number == 'Q':
print('程序结束')
break
elif number.isdigit():
intnumber = int(number)
print('{0}{1:#x}'.format('十进制 -> 十六进制:', intnumber))
print('{0}{1:#o}'.format('十进制 -> 八进制:', intnumber))
print('{0}{1:#b}'.format('十进制 -> 二进制:', intnumber))
break
else:
number = input('输入错误,请重新输入一个整数(输入Q结束程序):')
continue-
列表,元组和字符串的共同点
- 都可以通过索引得到每一个元素
- 默认索引值总是从0开始
- 可以通过分片的方法得到一个范围内的元素的集合
- 有很多共同的操作符(重复操作符,拼接操作符,成员关系操作符)
-
常用BIF
-
list(), 把一个可迭代器转换成列表
-
tuple(), 把一个可迭代器转换成元组
-
str(), 把obj对象转换成字符串
-
len(), 返回长度
-
max(), 返回序列或者参数集合中的最大值
-
min(), 返回序列或者参数集合中的最小值
-
sum(iterable[, start=0]), 返回序列iterable 和可选参数start的总和
-
sorted(), 从小到大排序; list.sort()
-
reversed(), 返回迭代器对象;可以用list(迭代器对象)转换成列表
-
enumerate(), 生成由每个元素的index 值和元素值组成的元组; 返回迭代器对象;可以用list(迭代器对象)转换成列表
-
zip(a, b), 成双成对打包
>>> a = list() >>> a [] >>> >>> b = 'I love fishC.com' >>> b = list(b) >>> >>> b ['I', ' ', 'l', 'o', 'v', 'e', ' ', 'f', 'i', 's', 'h', 'C', '.', 'c', 'o', 'm'] >>> >>> >>> c = (1, 1, 2, 3, 5, 8, 13, 21, 34) >>> >>> c = list(c) >>> >>> c [1, 1, 2, 3, 5, 8, 13, 21, 34] >>> len(a) 0 >>> len(b) 16 >>> max(1, 2, 3, 4, 5) 5 >>> >>> max(b) 'v' >>> >>> b ['I', ' ', 'l', 'o', 'v', 'e', ' ', 'f', 'i', 's', 'h', 'C', '.', 'c', 'o', 'm'] >>> >>> numbers = [1, 18, 13, 0, -98, 34, 54, 76, 32] >>> max(numbers) 76 >>> min(numbers) -98 >>> chars = '123456789' >>> min(chars) '1' >>> >>> tuple1 = (1, 2, 3, 4, 5, 6, 7, 8, 9, 0) >>> >>> max(tuple1) 9 >>> tuple2 = (3.1, 2.3, 3.4) >>> sum(tuple2) 8.8 >>> >>> sum(numbers) 130 >>> sum(numbers, 8) 138 >>> chars '123456789' >>> sum(chars) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'int' and 'str' >>> sorted(numbers) [-98, 0, 1, 13, 18, 32, 34, 54, 76] >>> reversed(numbers) <list_reverseiterator object at 0x10495e2b0> >>> list(reversed(numbers)) [32, 76, 54, 34, -98, 0, 13, 18, 1] >>> >>> >>> enumerate(numbers) <enumerate object at 0x104a0e4c0> >>> >>> list(enumerate(numbers)) [(0, 1), (1, 18), (2, 13), (3, 0), (4, -98), (5, 34), (6, 54), (7, 76), (8, 32)] >>> >>> a = [1, 2, 3, 4, 5, 6, 7, 8] >>> b = [4, 5, 6, 7] >>> zip(a, b) <zip object at 0x104a0e400> >>> >>> list(zip(a, b)) [(1, 4), (2, 5), (3, 6), (4, 7)]
-
-
我们根据列表、元祖和字符串的共同特点,把它们三统称为什么?
序列
-
请问分别使用什么BIF,可以把一个可迭代对象转换为列表、元祖和字符串?
list([iterable])
tuple([iterable])
str(obj)
-
你还能复述出“迭代”的概念吗?
所谓迭代,是重复反馈过程的活动,其目的通常是为了接近并到达所需的目标或结果。每一次对过程的重复被称为一次“迭代”,而每一次迭代得到的结果会被用来作为下一次迭代的初始值。
-
你认为调用 max('I love FishC.com') 会返回什么值?为什么?
'v', 因为字符串在计算机中是以ASCII码的形式存储(ASCII对照表:http://bbs.fishc.com/thread-41199-1-1.html),参数中ASCII码值最大的是'v'对应的118
-
哎呀呀,现在的小屁孩太调皮了,邻居家的孩子淘气,把小甲鱼刚写好的代码画了个图案,麻烦各位鱼油恢复下啊,另外这家伙画的是神马吗?怎么那么眼熟啊!??

name = input("请输入待查找的用户名:")
score = [ ['迷途', 85], ['黑夜', 80], ['小布丁', 65], ['福禄娃娃', 95], ['怡静', 90]]
IsFind = False
for each in score:
if name == each[0]:
print(name + '的得分是:', each[1])
IsFind = True
break
if not IsFind:
print("查找的数据不存在!")-
猜想一下 min() 这个BIF的实现过程
list1 = [3, 2, 332, 41, 532, 6] minvalue = list1[0] for each in list1: if each < minvalue: minvalue = each print(minvalue) -
视频中我们说 sum() 这个BIF有个缺陷,就是如果参数里有字符串类型的话就会报错,请写出一个新的实现过程,自动“无视”参数里的字符串并返回正确的计算结果
for each in list1: if isinstance(each, str): list1.remove(each) print(list1, '\n', sum(list1))
>>> def MyFirstFunction():
... print('这是我创建的第一个函数')
... print('我表示很激动')
...
>>> MyFirstFunction()
这是我创建的第一个函数
我表示很激动
- 先定义函数
- 执行函数时候,就是调用函数,向上面回找,依次执行函数体的内容
- 如果Python 向上找函数的时候,没有找到相应的函数名的定义过程,会报错
- Python 函数支持多个参数,但是尽量不用太多
- 函数要写好注释
>>> def MySecondFunction(name):
... print(name + 'I love You!' )
...
>>>
>>> MySecondFunction()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: MySecondFunction() missing 1 required positional argument: 'name'
>>>
>>>
>>> MySecondFunction('小甲鱼')
小甲鱼I love You!
>>> def add(num1, num2):
... result = num1 + num2
... print(result)
...
>>>
>>> add(1, 2)
3- 采用关键字return
>>> def add(num1, num2):
... return (num1 + num2)
...
>>>
>>> add(1, 2)
3
-
你有听说过DRY吗?
DRY是程序员们公认的指导原则:Don't Repeat Yourself.
-
都是重复一段代码,为什么我要使用函数(而不使用简单的拷贝黏贴)呢?
- 维护效率高
- 提高代码效率
- 降低代码量
- 易于阅读
-
函数可以有多个参数吗?
可以有多个参数
-
创建函数使用什么关键字,要注意什么?
使用“def”关键字,要注意函数名后边要加上小括号“()”,然后小括号后边是冒号“:”,然后缩进部分均属于函数体的内容
-
请问这个函数有多少个参数?
def MyFun((x, y), (a, b)): return x * y - a * b
0,因为类似于这样的写法是错误的!我们分析下,函数的参数需要的是变量,而这里你试图用“元祖”的形式来传递是不可行的。
-
请问调用以下这个函数会打印什么内容?
def hello(): print('Hello World!') return print('Welcome To FishC.com!')
会打印‘Hello World!’。因为return会结束函数的执行。
-
编写一个函数power()模拟内建函数pow(),即power(x, y)为计算并返回x的y次幂的值。
def power(x, y): if y == 0: return 1 elif y > 0: if y == 1: return x else: result = x for i in range(y-1): result *= x return result else: if y == -1: return 1/x else: result = x for i in range((-y-1)): result *= x return 1/result print(power(2, -2))
-
编写一个函数,利用欧几里得算法(脑补链接)求最大公约数,例如gcd(x, y)返回值为参数x和参数y的最大公约数。
def gcder(a, b): flag = a % b result = b while flag != 0: flag = a % b result = b a = b b = flag return result print(gcder(121, 11))
-
编写一个将十进制转换为二进制的函数,要求采用“除2取余”(脑补链接)的方式,结果与调用bin()一样返回字符串形式。
def biner(x): binarylist = [] while x != 0: flag = str(x % 2) binarylist.insert(0, flag) x = x // 2 # 将列表或元组转换成字符串的方法:''.join(object) return ''.join(binarylist) print(biner(4))
\>>> def MySecondFunction(name):函数定义过程中的name是叫形参, # 因为它只是一个形式,表示占据一个位置\>>> MySecondFunction('小甲鱼'):传递进来的小甲鱼叫做实参,因为它是具体的参数值
-
系统默认特殊属性:
.__doc__ -
利用函数文档,对函数的内容,参数,意义以及返回值有一个介绍,让别人可以理解使用
>>> def MyFirstFunction(name): ... '函数定义过程中的name是叫形参' ... #因为它只是一个形式,表示占据一个参数位置 ... print('传递进来的' + name + '叫做实参,因为它是具体的参数值!') ... >>> >>> MyFirstFunction('小甲鱼') 传递进来的小甲鱼叫做实参,因为它是具体的参数值! >>> >>> MyFirstFunction.__doc__ '函数定义过程中的name是叫形参' >>> >>> >>> print.__doc__ "print(value, ..., sep=' ', end='\\n', file=sys.stdout, flush=False)\n\nPrints the values to a stream, or to sys.stdout by default.\nOptional keyword arguments:\nfile: a file-like object (stream); defaults to the current sys.stdout.\nsep: string inserted between values, default a space.\nend: string appended after the last value, default a newline.\nflush: whether to forcibly flush the stream." >>>
-
利用关键字匹配参数,可以避免搞不清楚顺序按照位置匹配引起的问题
>>> def SaySome(name, words): ... print(name + '->' + words) ... >>> SaySome('小甲鱼', '让编程改变世界') 小甲鱼->让编程改变世界 >>> >>> SaySome('让编程改变世界', '小甲') 让编程改变世界->小甲 >>> SaySome(words='让编程改变世界', name='小甲鱼') 小甲鱼->让编程改变世界
-
在参数定义的过程中,为形参赋初始值
>>> def SaySome(name='小甲鱼', words='让编程改变世界'): ... print(name + '->' + words) ... >>> >>> >>> SaySome() 小甲鱼->让编程改变世界 >>> >>> >>> SaySome('默默') 默默->让编程改变世界 >>> >>> SaySome('默默', '你好') 默默->你
-
可变参数,原因是函数的作者有时候也搞不清楚到底需要多少个参数
-
在参数前面加上*号即可
-
Python 把标识为收集参数的参数用一个元组打包起来
>>> def test(*params): ... print('参数的长度是', len(params)) ... print('第二个参数是', params[1]) ... >>> >>> >>> test(1, '小鲫鱼', 3, 5, 7) 参数的长度是 5 第二个参数是 小鲫鱼
-
如果除了收集参数,还有其他定制参数,需要使用关键字参数来定制,不然会报错
>>> def test(*params, exp): ... print('参数的长度是', len(params), exp) ... print('第二个参数是', params[1]) ... >>> >>> >>> test(1, '小鲫鱼', 3, 5, 7) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() missing 1 required keyword-only argument: 'exp' >>> >>> >>> test(1, '小鲫鱼', 3, 5, 7, exp=8) 参数的长度是 5 8 第二个参数是 小鲫鱼
-
请问以下哪个是形参哪个是实参?
def MyFun(x): return x ** 3 y = 3 print(MyFun(y))
x 是形参,y 是实参;形参指的是函数定义过程中,小括号里面的参数;实参指的是函数调用过程中传递进去的参数
-
函数文档和直接用“#”为函数写注释有什么不同
函数文档会保存在内置函数:
__doc__,可以通过help()或者.__doc__来查看 -
使用关键字参数,可以有效避免什么问题的出现呢?
可以避免忘记参数位置导致传入的实参不匹配的问题
-
使用help(print)查看print()这个BIF有哪些默认参数?分别起到什么作用?
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) -
默认参数和关键字参数表面最大的区别是什么
默认参数会默认指定一个值,如果没有传入任何实参的时候,会使用默认值
-
编写一个符合以下要求的函数:
a. 计算打印所有参数的和乘以基数(base=3)的结果
b. 如果参数中最后一个参数为(base=5),则设定基数为5,基数不参与求和计算
# 编写一个符合以下要求的函数: # a. 计算打印所有参数的和乘以基数(base=3)的结果 # b. 如果参数中最后一个参数为(base=5),则设定基数为5,基数不参与求和计算 def practice1(*pram, base=3): return sum(pram)*base print(practice1(1, 3, 4)) print(practice1(1, 3, 4, base=5))
-
寻找水仙花数
题目要求:如果一个3位数等于其各位数字的立方和,则称这个数为水仙花数。例如153 = 1^3+5^3+3^3,因此153是一个水仙花数。编写一个程序,找出所有的水仙花数。
# 寻找水仙花数 # 题目要求:如果一个3位数等于其各位数字的立方和,则称这个数为水仙花数。例如153 = 1^3+5^3+3^3,因此153是一个水仙花数。编写一个程序,找出所有的水仙花数。 def narcissistic(): for i in range(100, 1000): x = i // 100 y = (i // 10) % 10 z = i % 10 if i == pow(x, 3) + pow(y, 3) + pow(z, 3): print('narcissistic number: %d' % i) narcissistic()
-
编写一个函数 findstr(),该函数统计一个长度为 2 的子字符串在另一个字符串中出现的次数。例如:假定输入的字符串为“You cannot improve your past, but you can improve your future. Once time is wasted, life is wasted.”,子字符串为“im”,函数执行后打印“子字母串在目标字符串**出现 3 次”。
# 编写一个函数 findstr(),该函数统计一个长度为 2 的子字符串在另一个字符串中出现的次数。 # 例如:假定输入的字符串为 # “You cannot improve your past, but you can improve your future. Once time is wasted, life is wasted.”, # 子字符串为“im”,函数执行后打印“子字母串在目标字符串**出现 3 次”。 def findstr(x, y): a = y[0] b = y[1] count = 0 xlen = len(x) for i in range(xlen): if x[i] == a and x[i+1] == b: count += 1 print(count) findstr('You cannot improve your past, but you can improve your future. Once time is wasted, life is wasted.', 'im')
-
函数是有返回值的
-
过程是简单的,特殊的,没有返回值的
-
Python 只有函数,没有过程。Python的所有函数都是有返回的,有返回值就返回值,没有返回值就返回None
>>> def hello(): ... print('hello, fishC!') ... >>> temp = hello() hello, fishC! >>> >>> temp >>> >>> type(temp) <class 'NoneType'>
-
Python 动态确定类型,不需要提前定义
-
Python是没有变量的,只有名字
-
Python 是可以返回多个返回值的
>>> def back(): ... return[1, '小甲鱼', 3.14] ... >>> back() [1, '小甲鱼', 3.14] >>> >>> >>> >>> def back(): ... return 1, '小甲鱼', 3.14 ... >>> back() (1, '小甲鱼', 3.14)
-
局部变量: 作用域范围在函数内,在外面调用会出错;Python 在调用函数时,利用栈来存储函数所需要的代码和局部变量,当执行完函数,函数的栈会自动清空,所以函数执行完之后再试图访问函数体内的变量会出错
def discounts(price, rate): final_price = price * rate return final_price old_price = float(input('请输入原价:')) rate = float(input('请输入折扣率:')) new_price = discounts(old_price, rate) print('打折扣价格是:', new_price) # 试图打印局部变量:final_price 会报错 print('试图打印局部变量final_price', final_price)
请输入原价:12 请输入折扣率:0.3 打折扣价格是: 3.5999999999999996 Traceback (most recent call last): File "/Users/felix_yang/PycharmProjects/learningpython/19/test01.py", line 15, in <module> print('试图打印局部变量final_price', final_price) NameError: name 'final_price' is not defined
-
全局变量:拥有更大的作用域,他们的作用域是整个代码段。那如果在函数体内部访问全局变量是不是可以呢?
def discounts(price, rate): final_price = price * rate # 试图打印全局变量: old_price 不会报错 print('试图打印全局变量old_price', old_price) return final_price old_price = float(input('请输入原价:')) rate = float(input('请输入折扣率:')) new_price = discounts(old_price, rate) print('打折扣价格是:', new_price)
请输入原价:12 请输入折扣率:0.4 试图打印全局变量old_price 12.0 打折扣价格是: 4.800000000000001
不要试图在函数内不修改全局变量,因为那样的话,python 会试图在函数内部创建一个名字一样的局部变量存储在函数的栈当中
-
下边程序会输出什么?
def next(): print('我在next()函数里...') pre() def pre(): print('我在pre()函数里...') next()
我在next()函数里...
我在pre()函数里...
-
请问以下这个函数有返回值吗?
def hello(): print('Hello FishC!')
有,返回值是none
-
请问Python的return语句可以返回多个不同类型的值吗?
可以,可以return 列表,或者元组,把不同类型的值放到列表/元组中返回
-
请目测以下程序会打印什么内容?
def fun(var): var = 1314 print(var, end = '') var = 520 fun(var) print(var)
1314520
第一个打印出来的是函数体内的局部变量(名字也叫var),第二个打印出来的是定义在函数之外的全局变量var
-
目测以下程序会打印什么内容?
var = 'Hi' def fun1(): global var var = ' Baby ' return fun2(var) def fun2(var): var += 'I love you' fun3(var) return var def fun3(var): var = ' 小甲鱼 ' print(fun1())Baby I love you
-
编写一个函数,判断传入的字符串参数是否为“回文联”
# 编写一个函数,判断传入的字符串参数是否为“回文联” # list的reverse()方法是返回None的,只会对列表内的元素逆序排序。而string的reserved()方法是会返回逆序后的字符串的 def check(var): list1 = list(var) list2 = list1[:] list2.reverse() if list1 == list2: print('传入的参数 %s 是:回文联' % var) else: print('传入的参数 %s 不是:回文联' % var) check('1234321')
-
编写一个函数,分别统计传入字符串参数(可能不止一个参数)的英文字母、空格、数字和其它字符的个数。
# 编写一个函数,分别统计传入字符串参数(可能不止一个参数)的英文字母、空格、数字和其它字符的个数。 # 单个参数的情况 def count_str(var): str_count = 0 space_count = 0 number_count = 0 other_count = 0 for i in var: if i.isdigit(): number_count += 1 elif i.isalpha(): str_count += 1 elif i.isspace(): space_count += 1 else: other_count += 1 print('英文字母个数是:%d' % str_count) print('数字个数是:%d' % number_count) print('空格个数是:%d' % space_count) print('其他字符个数是:%d' % other_count) count_str('12d99 safe')
# 编写一个函数,分别统计传入字符串参数(可能不止一个参数)的英文字母、空格、数字和其它字符的个数。 # 多个参数的情况 def count_str(*param): var_number = len(param) for i in range(var_number): str_count = 0 space_count = 0 number_count = 0 other_count = 0 for each in param[i]: if each.isdigit(): number_count += 1 elif each.isalpha(): str_count += 1 elif each.isspace(): space_count += 1 else: other_count += 1 print('第 %d 个参数有 %d 英文字母,%d 数字, %d 空格, %d 其他字符' % (i, str_count, number_count, space_count, other_count)) count_str('1fe', '1ssssf sfe')
-
上节课提到不要试图去修改全局变量,python 会使用shadowing 的机制防止全局变量被修改
>>> count = 5 >>> def MyFun(): ... count = 10 ... print(count) ... >>> MyFun() 10 >>> print(count) 5
-
如果非要修改,可以使用global 关键字,把想要变成全局变量的局部变量变成全局变量
>>> def MyFun(): ... global count ... count = 10 ... print(count) ... >>> MyFun() 10 >>> >>> print(count) 10
-
python 是支持函数嵌套的,先看一个例子。注意嵌套里面的函数无法在外面调用。
>>> def fun1(): ... print('fun1 is being called') ... def fun2(): ... print('fun2 is being called') ... fun2() ... >>> fun1() fun1 is being called fun2 is being called
-
闭包是一种编程范式;其他的编程范式有:面向对象编程,面向过程编程,这些都是对代码的抽象和概括,使得代码的可用性和重用性变高
-
如果在一个内部函数里,对在外部作用域的变量(不是全局作用域的变量)进行引用,那么这个内部函数就是一个闭包
>>> def FunX(x): ... def FunY(y): ... return x * y ... return FunY ... >>> i = FunX(8) >>> i <function FunX.<locals>.FunY at 0x103343040> >>> >>> >>> type(i) <class 'function'> >>> >>> i(5) 40 >>> >>> FunX(8)(5) 40 >>> >>> FunY(5) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'FunY' is not defined
-
因为闭包的概念是由内嵌函数演变而来, 所以也不能从外部函数的外面调用内部函数
-
在内部函数中只能对外部作用域的变量进行引用,不能修改,如果修改的话,这个变量同样会被shadowing,python 会在内部函数创建一个同名的内部作用域变量。以下例子显示了新建的内部作用域变量由于未被事先定义而报错
>>> def Fun1(): ... x = 5 ... def Fun2(): ... x *= x ... return x ... return Fun2() ... >>> >>> Fun1() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 6, in Fun1 File "<stdin>", line 4, in Fun2 UnboundLocalError: local variable 'x' referenced before assignment
-
有没有解决的办法呢?Python3 之前没有解决办法,只有通过容器类型来解决,比如列表,因为不会存储在栈里面,不会报错
>>> def Fun1(): ... x = [5] ... def Fun2(): ... x[0] *= x[0] ... return x[0] ... return Fun2() ... >>> >>> Fun1() 25
-
Python3 开始,可以通过nonlocal 关键字来解决,类似于global 关键字
>>> def Fun1(): ... x = 5 ... def Fun2(): ... nonlocal x ... x *= x ... return x ... return Fun2() ... >>> >>> Fun1() 25
-
-
闭包的实际应用,主要是用来封装变量。即把变量隐藏起来,不让外面拿到和修改。
闭包就是能够读取其他函数内部变量的函数,说白了闭包就是个函数,只不过是处于其他函数内部而已。 由于在python中,只有函数内部的子函数才能读取局部变量,所以说,闭包可以简单理解成“定义在一个函数内部的函数“。 所以,在本质上,闭包是将函数内部和函数外部连接起来的桥梁。 知乎大神说:闭包是指在 JavaScript 中,内部函数总是可以访问其所在的外部函数中声明的参数和变量,即使在其外部函数被返回(寿命终结)了之后。 二:用途是什么? 1.访问函数内部的变量 2.防止函数内部的变量执行完城后,被销毁,使其一直保存在内存中。
-
如果希望在函数中修改全局变量的值,应该使用什么关键字?
global
-
在嵌套函数中,如果希望在内部函数修改外部函数的局部变量,应该是用什么关键字?
nonlocal
-
Python的函数可以嵌套,但是要注意访问的作用域问题,请问以下代码存在什么问题呢?
def outside(): print('I am outside!') def inside(): print('I am inside!') inside()
不能直接访问嵌套内函数,只能访问outside()
-
请问为什么代码A没有报错,但是代码B却报错了?应该如何修改?
代码A:
1 def outside(): 2 var = 5 3 def inside(): 4 var = 3 5 print(var ) 6 inside() 7 outside()
代码B:
1 def outside(): 2 var = 5 3 def inside(): 4 print(var ) 5 var = 3 6 inside() 7 outside()
在内部函数中只能对外部作用域的变量进行引用,不能修改,如果修改的话,这个变量同样会被shadowing,python 会在内部函数创建一个同名的内部作用域变量。代码B 新建的内部作用域变量var 由于未被事先定义而被打印:print(var) 而报错。而代码A 已经事先定义: var=3,所以不会报错
-
请问如何访问FunIn()呢?
1 def funOut(): 2 def funIn(): 3 print("宾果!恭喜成功访问到啦~") 4 return funIn()
funOut()
-
请问如何访问FunIn()呢?
1 def funOut(): 2 def funIn(): 3 print("宾果!恭喜成功访问到啦~") 4 return funIn
funOut()()
或者
a = funOut()
a()
-
以下是“闭包”的一个例子,请你目测下会打印什么内容?
1 def funX(): 2 x=5 3 def funY(): 4 nonlocal x 5 x+=1 6 return x 7 return funY 8 a=funX() 9 print(a()) 10 print(a()) 11 print(a())6
7
8
大家可能会迷惑,这。。。怎么跟全局变量一样了?局部变量x不是应该再每次调用的时候都重新初始化了吗?!
其实大家自己看看就明白了,当a = funX(),只要a变量没有被重新赋值,funX()就没有被释放,也就是说局部变量x就没有被重新初始化。
所以当全局变量不适用的时候,可以考虑使用闭包更稳定和安全
-
统计下边这个长字符串中各个字符出现的次数并找到小甲鱼送给大家的一句话
def count_str(x): temp_list = [] temp_number = [] lenth = len(x) def show(): for i in range(lenth): current_char = x[i] if current_char not in temp_list: temp_list.append(current_char) temp_number.append(x.count(current_char)) final_list = list(zip(temp_list, temp_number)) print(final_list) # print('字符 %s 的数量是:%d' % (current, number)) return show() count_str(string1)
[('%', 6104), ('$', 6046), ('@', 6157), ('_', 6112), ('^', 6030), ('#', 6115), (')', 6186), ('&', 6043), ('!', 6079), ('+', 6066), (']', 6152), ('*', 6034), ('}', 6105), ('[', 6108), ('(', 6154), ('{', 6046), ('\n', 1219), ('G', 1), ('O', 2), ('D', 1), ('L', 1), ('U', 1), ('C', 1), ('K', 1)]GOODLUCK
-
请用已经学过的知识编写程序,找出小甲鱼藏在下边这个长字符串中的密码,密码的埋藏点符合以下规律:
- 每位密码为单个小写字母
- 每位密码的左右两边均有且只有三个大写字母
def find_pass(x): str_length = len(x) - 9 pass_list = '' def show_pass(): # 指定pass_list 为nonlocal,因为需要从闭包函数里面调用修改 nonlocal pass_list # 判断第一个password 字符,其实是从第4个字符开始: xxx[]xxxx,前后3个字符都是大写字母,第8个字符是小写 if x[:3].isupper() and x[4:7].isupper() and (x[3]+x[7]).islower() and x[:7].isalpha(): pass_list += x[3] # 每次截取9个字符放到temp_string,判断中间的一个字符和两头的字符是小写,前后3个字符为大写 for i in range(str_length): temp_string = x[i:i+9] temp_low = temp_string[0] + temp_string[4] + temp_string[-1] temp_up = temp_string[1:4] + temp_string[-4:-1] if temp_low.islower() and temp_up.isupper() and (temp_up + temp_string[4]).isalpha(): pass_list += temp_string[4] # 判断最后一个password 字符,其实是从倒数第4个字符开始: xxxx[]xxx,前后3个字符都是大写字母,倒数第8个字符是小写 if x[-7:-4].isupper() and x[-3:].isupper() and (x[-4]+x[-7]).islower() and x[-7:].isalpha(): pass_list += x[-4] print(pass_list) return show_pass() find_pass(string2)
-
Lambda 表达式用冒号分隔,冒号前面是参数,后面是函数体内容
-
先举一个例子 - 1 个参数
>>> def ds(x): ... return 2 * x + 1 ... >>> ds(5) 11 >>> >>> >>> >>> lambda x : 2 * x + 1 <function <lambda> at 0x1033431f0> >>> g = lambda x : 2 * x + 1 >>> >>> g(5) 11
-
再举一个例子 - 2个参数
>>> def add(x, y): ... return x + y ... >>> add(3, 4) 7 >>> >>> lambda x, y : x + y <function <lambda> at 0x103343310> >>> >>> g = lambda x, y : x + y >>> g(3, 4) 7
- Python写一些执行脚本的时候,使用lambda就可以省下定义函数的过程,比如说我们只是需要写个简单的脚本来管理服务器时间,我们就不需要专门定义一个函数然后再写调用,使用lambda可以使得代码更加精简。
- 对于一些比较抽象并且整个程序执行下来只需要调用一两次的函数,有时候给函数起个名字是比较头疼的问题,使用lambda就不需要考虑命名的问题了。
- 简化代码的可读性,由于普通屌丝函数阅读经常要跳到开头def 定义部分,使用lambda函数可以省去这样的步骤
-
filter() :
-
filter(function or None, iterable)
-
Return an iterator yielding those items of iterable for which function(item) is true. If function is None, return the items that are true. (如果第一个参数是函数,返回一个迭代器,返回iterable中function(item)为true的元素; 如果第一个参数是none,返回值为true的item)
举例:如果第一个参数为函数:
>>> def odd(x): ... return x % 2 ... >>> temp = range(10) >>> show = filter(odd, temp) >>> list(show) [1, 3, 5, 7, 9]
用lambda 实现
>>> show = filter(lambda x : x % 2, range(10)) >>> list(show) [1, 3, 5, 7, 9]
举例:如果第一个参数为None:
>>> filter(None, [1, 0, False, True]) <filter object at 0x103325730> >>> >>> list(filter(None, [1, 0, False, True])) [1, True]
-
-
map()
-
map(func, *iterables) 第一个参数是函数,后面的参数是一个或者多个序列
-
Make an iterator that computes the function using arguments from each of the iterables. Stops when the shortest iterable is exhausted. (使用每个可迭代对象的参数计算函数,来创建一个迭代器,当最短的可迭代对象耗尽时停止。)
举例:一个序列
>>> list(map(lambda x : x * 2, range(10))) [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
举例:多个序列
>>> list(map(lambda x, y : x * y, range(10), range(5))) [0, 1, 4, 9, 16]
-
-
请使用lambda表达式将下边函数转变为匿名函数?
def fun_A(x,y=3): return x*ylambda x, y=3 : x * y
-
请将下边的匿名函数转变为普通的屌丝函数?
lambda x: x if x % 2 else None
def ds(x): if x % 2: return x else: return None
-
感受一下使用匿名函数后给你的编程生活带来的变化?
不用为起函数名而烦恼了
-
你可以利用filter()和lambda表达式快速求出100以内所有3的倍数吗?
>>> list(filter(lambda x : not( x % 3 ), range(100))) [0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48, 51, 54, 57, 60, 63, 66, 69, 72, 75, 78, 81, 84, 87, 90, 93, 96, 99]
-
还记得列表推导式吗?完全可以使用列表推导式代替filter()和lambda组合,你可以做到吗?
>>> [ x for x in range(100) if x % 3 == 0 ] [0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48, 51, 54, 57, 60, 63, 66, 69, 72, 75, 78, 81, 84, 87, 90, 93, 96, 99]
-
还记得zip吗?使用zip会将两数以元祖的形式绑定在一块,例如:
>>> list(zip([1, 3, 5, 7, 9], [2, 4, 6, 8, 10])) [(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]但如果我希望打包的形式是灵活多变的列表而不是元祖(希望是[[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]这种形式),你能做到吗?(采用map和lambda表达式)
>>> list(map(lambda x, y : [x, y], [1, 3, 5, 7, 9], [2, 4, 6, 8, 10] )) [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
-
请目测以下表达式会打印什么?
def make_repeat(n): return lambda s: s * n double = make_repeat(2) print(double(8)) print(double('FishC'))
16 FishCFishC
递归其实就是函数调用自己
- 汉诺塔游戏: 使用递归会比迭代更好
- 树结构的定义: 使用递归定义结构体会比其他方法容易很多
- 谢尔宾斯基三角形:递归组成的图案
- 女神自拍
-
写一个求阶乘的函数
- 正整数阶乘指从1乘以2乘以3乘以4一直乘到所要求的数
- 例如所给的数是5,则阶乘式是1x2x3x4x5,得到的积是120,所以120就是5的阶乘
-
非递归版本范例:
def factorial(x): result = x for n in range(1, x): result *= n return result number = int(input('please input a number:')) final_result = factorial(number) print(final_result)
-
递归版本范例
def factorial(n): if n == 1: return 1 else: return n * factorial(n-1) number = int(input('please input a number:')) final_result = factorial(number) print(final_result)

-
递归在编程上的形式是如何表现的呢?
函数自己调用自己
def fun(): return fun()
不过这样是不行的,因为没有停止条件,IDLE会一直报错,直到你按下Ctlr + C。python3默认递归的深度是100层,可以通过以下代码修改:
>>> import sys >>> sys.setrecursionlimit(1000)
-
递归必须满足哪两个基本条件?
递和归,调用自身,有停止条件。
-
思考一下,按照递归的特性,在编程中有没有不得不使用递归的情况?
例如汉诺塔,目录索引(因为你不知道目录里是否还有目录),树结构的定义等
-
用递归去计算阶乘问题或斐波那契数列是很糟糕的算法,你知道为什么吗?
因为递归是函数调用自身,每一次调用都要进行压栈和出栈,需要很多时间和内存资源。
-
请聊一聊递归的优缺点(无需官方陈词,想到什么写什么就可以)
优点:可以使代码简洁;在解决一些问题,如汉诺塔问题时比较方便 缺点:使用上需要谨慎,因为会占用大量时间和资源;还有可能因为停止条件设置不合适而导致内存爆满。
-
拿手机拍一张“递归自拍照片”
拍这个的话需要两面镜子,那会是一个没有停止条件的递归,无限循环反射下去。
-
使用递归编写一个power()函数内建函数pow(),即power(x,y)为计算并返回x的y次幂的值。
# 使用递归编写一个power()函数内建函数pow(),即power(x,y)为计算并返回x的y次幂的值。 def power(x, y): if y == 1: return x elif y == 0: return 1 else: return x * power(x, y-1) print(power(2, 10))
-
使用递归编写一个函数,利用欧几里得算法求最大公约数,例如gcd(x,y)返回值为参数x和参数y的最大公约数。
# 使用递归编写一个函数,利用欧几里得算法求最大公约数,例如gcd(x,y)返回值为参数x和参数y的最大公约数。 def gcder(x, y): if x % y == 0: return y else: return gcder(y, x % y) print(gcder(9, 6))

-
递归算法 - 思路清晰,但是耗费资源
def fibonacci(n): if n == 1 or n == 2: return 1 elif n < 1: return -1 else: return fibonacci(n-1) + fibonacci(n-2) n = input('please input a number:') result = fibonacci(int(n)) if result != -1: print(result)
-
迭代算法
def fibonacci(n): n1 = 1 n2 = 1 if n < 1: print('The number is incorrect') elif n == 1 or n == 2: return 1 else: while (n-2) > 0: n3 = n1 + n2 n1 = n2 n2 = n3 n -= 1 return n3 n = int(input('please input a number:')) result = fibonacci(n) print(result)



In [1]: def hanoi(n, x, y, z):
...: if n == 1:
...: print(x, '--->', z)
...: else:
...: hanoi(n-1, x, z, y)
...: print(x, '--->', z)
...: hanoi(n-1, y, x, z)
...:
In [2]: n = int(input('please input the hanoi levels:'))
please input the hanoi levels:3
In [3]: hanoi(n, 'x', 'y', 'z')
x ---> z
x ---> y
z ---> y
x ---> z
y ---> x
y ---> z
x ---> z
-
使用递归编写一个十进制转换为二进制的函数(要求采用“取2取余”的方式,结果与调用bin()一样返回字符串形式) $$ b = f(x) = \left{ \begin{array}{lr} 1 & : x = 1\ f( x // 2) \Join x % 2 & : x > 1 \end{array} \right. $$
$$ \Join 表示拼接; 公式的意思是:如果十进制正整数 x 等于 1,那它对应的二进制 b 就是 1; 否则 x 大于 1,那它的二进制就是 d 整除 2 的商对应的二进制,拼接 x 整除 2 的余数。 $$ # 使用递归编写一个十进制转换为二进制的函数(要求采用“取2取余”的方式,结果与调用bin()一样返回字符串形式) def bin_recursion(n): if n == 1: return 1 else: return str(bin_recursion(n // 2)) + str(n % 2) print(bin_recursion(8))
-
写一个函数get_digits(n),将参数n分解出每个位的数字并按顺序存放到列表中。举例:get_digits(12345) ==> [1, 2, 3, 4, 5]
$$ b = f(x) = \left{ \begin{array}{lr} [ ] & : x = 0 \
[f( x // 10) , x % 10 ]& : x > 0 \end{array}\right. $$# 写一个函数get_digits(n),将参数n分解出每个位的数字并按顺序存放到列表中。举例:get_digits(12345) ==> [1, 2, 3, 4, 5] def get_digits(n): result = [] if n == 0: return [] else: result.extend(get_digits(n // 10)) result.append(n % 10) return result print(get_digits(12342321421321))
-
还记得求回文字符串那道题吗?现在让你使用递归的方式来求解,亲还能骄傲的说我可以吗
-
使用递归编程求解以下问题:
有5个人坐在一起,问第五个人多少岁?他说比第4个人大2岁。问第4个人岁数,他说比第3个人大2岁。问第三个人,又说比第2人大两岁。问第2个人,说比第一个人大两岁。最后问第一个人,他说是10岁。请问第五个人多大?
# 使用递归编程求解以下问题: # # 有5个人坐在一起,问第五个人多少岁?他说比第4个人大2岁。问第4个人岁数,他说比第3个人大2岁。问第三个人,又说比第2人大两岁。问第2个人,说比第一个人大两岁。最后问第一个人,他说是10岁。请问第五个人多大? def age(n): if n == 1: return 10 else: return age(n-1) + 2 print(age(5))
-
Python的字典,key-value,也称为HASH,关系数组
-
映射类型区别于序列类型,通过数组的形式进行存储的,通过索引进行存取
In [9]: brand = ['李宁', '耐克', '阿迪达斯', '鱼C 工作室'] In [10]: slogan = ['一切皆有可能', 'Just Do It', 'Impossible is nothing', '让编程改变世界'] In [11]: print('鱼C 工作室的口号是:', slogan[brand.index('鱼C 工作室')]) 鱼C 工作室的口号是: 让编程改变世界
-
创建和访问字典
In [12]: dict1 = {'李宁':'一切皆有可能', '耐克':'Just Do It', '阿迪达斯':'Impossible is nothing', '鱼C 工作室':'让编程改变世界'} In [13]: print('鱼C 工作室的口号是:', dict1['鱼C 工作室']) 鱼C 工作室的口号是: 让编程改变世界 In [14]: dict2 = {1:'one', 2:'two', 3:'three'} In [15]: dict2 Out[15]: {1: 'one', 2: 'two', 3: 'three'} In [16]: dict2[2] Out[16]: 'two' In [17]: dict3 = {} In [18]: dict3 Out[18]: {}
-
dict() 工厂函数 创建字典
工厂函数看上去有点像函数,实质上他们是类,当你调用他们时,实际上是生成了该类型的一个实例,就像工厂生产货物一样,常见的工厂函数有:list(), tuple(), dict(), int(), float()
In [19]: dict3 = dict((('F', 70), ('i', 105), ('h', 104), ('c', 67))) In [20]: dict3 Out[20]: {'F': 70, 'i': 105, 'h': 104, 'c': 67}
-
关键字参数创建字典
In [25]: dict4 = dict(李宁='一切皆有可能', 耐克='Just Do It') In [26]: dict4 Out[26]: {'李宁': '一切皆有可能', '耐克': 'Just Do It'}
-
直接给字典的键赋值,如果这个键不存在,会直接创建这个键
In [29]: dict4['阿迪达斯'] = 'Impossible is nothing' In [30]: dict4 Out[30]: {'李宁': '一切皆有可能', '耐克': 'Just Do It', '阿迪达斯': 'Impossible is nothing'}
-
clear() fromkeys() items() pop() setdefault() values()
copy() get() keys() popitem() update()
-
当你听到小伙伴们在谈论“映射”、“哈希”、“散列”或者“关系数组”的时候,事实上他们就是在讨论什么呢
字典
-
尝试一下将数据(‘F’: 70, ‘C’: 67, ‘h’: 104, ‘i’: 105, ‘s’: 115)创建为一个字典并访问键 ‘C’ 对应的值?
>>> dict1 = dict(F=70, C=67, h=104, i=105, s=115) >>> dict1 {'F': 70, 'C': 67, 'h': 104, 'i': 105, 's': 115} >>> dict1['C'] 67
-
用方括号(“[]”)括起来的数据我们叫列表,那么使用大括号(“{}”)括起来的数据我们就叫字典,对吗?
不对,用大括号括起来的数据还要形成有对应对象的映射关系(即 键 与 值 )才能构成字典。
-
你如何理解有些东西字典做得到,但“万能的”列表却难以实现(臣妾做不到T_T)?
列表本身的元素是只有与其所在位置的索引值有对应关系的,而元素与元素之间是无法产生相互映射关系的,并且列表与列表之间要表达映射关系只能通过索引值进行索引之后再提取进行对应,这样会变麻烦很多。所以字典的存在就弥补了这种繁琐过程的缺陷,字典本身内在的元素就通过键(key)与值(value)之间进行了映射关系,所以在调用的时候能很快通过键取得值,省去了列表与列表先索引再对应的过程。
-
下边这些代码,他们都在执行一样的操作吗?你看得出差别吗?
>>> a = dict(one=1,two=2,three=3) >>> b = {'one':1,'two':2,'three':3} >>> c = dict(zip(['one','two','three'],[1,2,3])) >>> d = dict([('two',2),('one',1),('three',3)]) >>> e = dict({'three':3,'one':1,'two':2})
A: 通过关键字定义,关键字不能加引号
B: 直接定义
C: 先用zip 生成一个具有映射关系的对象,每个元素就是一个元祖,包含键和值,然后用工厂函数dict 转换成字典
D: 把一个具有映射关系的列表,用工厂函数dict 转换成字典
E: 把一个具有映射关系的字典,用工厂函数dict 转换成字典
-
如图,你可以推测出打了马赛克部分的代码吗?
data.split(',')

-
尝试利用字典的特性编写一个通讯录程序吧,功能如图:

Version-1:
# 尝试利用字典的特性编写一个通讯录程序吧
address_book = {'小甲鱼': '020-88974563', 'Felix': '025-52680000'}
welcome_msg = '''
|--- 欢迎进入通讯录程序---|
|--- 1: 查询联系人资料---|
|--- 2: 插入新的联系人---|
|--- 3: 删除已有联系人---|
|--- 4: 退出通讯录程序---|
'''
bye_msg = '''
|--- 感谢使用通讯录程序---|
'''
def ad_search():
name = input('请输入联系人姓名:')
if name in address_book.keys():
print(address_book[name])
else:
print('输入的联系人不存在!')
def ad_insert():
name = input('请输入联系人姓名:')
if name in address_book.keys():
print('您输入的姓名在通讯录中已存在 --->> %s : %s' %(name, address_book[name]))
edit_check = input('是否修改用户资料(YES/NO)')
if edit_check == 'YES':
address_book[name] = input('请输入用户联系电话:')
else:
phone = input('请输入用户联系电话:')
address_book[name] = phone
def ad_delete():
name = input('请输入联系人姓名:')
if name in address_book.keys():
del_check = input('是否删除已有联系人: %s(YES/NO)' % name)
if del_check == 'YES':
del address_book[name]
else:
print('输入的联系人不存在!')
def address():
while True:
print(welcome_msg)
code = int(input('请输入相关的指令代码:'))
if code == 2:
ad_insert()
elif code == 1:
ad_search()
elif code == 3:
ad_delete()
elif code == 4:
print(bye_msg)
break
else:
print('输入有误,请重新输入代码')
if __name__ == '__main__':
address()Version-2: dict.pop() 删除字典键值, dict.setdefault() 修改字典:插入字典键值
# 尝试利用字典的特性编写一个通讯录程序吧
address_book = {'小甲鱼': '020-88974563', 'Felix': '025-52680000'}
welcome_msg = '''
|--- 欢迎进入通讯录程序---|
|--- 1: 查询联系人资料---|
|--- 2: 插入新的联系人---|
|--- 3: 删除已有联系人---|
|--- 4: 退出通讯录程序---|
'''
bye_msg = '''
|--- 感谢使用通讯录程序---|
'''
def ad_search():
name = input('请输入联系人姓名:')
if name in address_book.keys():
print(address_book[name])
else:
print('输入的联系人不存在!')
def ad_insert():
name = input('请输入联系人姓名:')
if name in address_book.keys():
print('您输入的姓名在通讯录中已存在 --->> %s : %s' %(name, address_book[name]))
edit_check = input('是否修改用户资料(YES/NO)')
if edit_check == 'YES':
address_book[name] = input('请输入用户联系电话:')
else:
# phone = input('请输入用户联系电话:')
# address_book[name] = phone
address_book.setdefault(name, input('请输入用户联系电话:'))
def ad_delete():
name = input('请输入联系人姓名:')
if name in address_book.keys():
del_check = input('是否删除已有联系人: %s(YES/NO)' % name)
if del_check == 'YES':
address_book.pop(name)
else:
print('输入的联系人不存在!')
def address():
while True:
print(welcome_msg)
code = int(input('请输入相关的指令代码:'))
if code == 2:
ad_insert()
elif code == 1:
ad_search()
elif code == 3:
ad_delete()
elif code == 4:
print(bye_msg)
break
else:
print('输入有误,请重新输入代码')
if __name__ == '__main__':
address()-
创建字典:fromkeys():
fromkeys(iterable, value=None, /) method of builtins.type instance; Create a new dictionary with keys from iterable and values set to value.
>>> dict1 = {} >>> dict1.fromkeys((1, 2, 3)) {1: None, 2: None, 3: None} >>> >>> >>> dict1.fromkeys((1, 2, 3), 'number') {1: 'number', 2: 'number', 3: 'number'}
注意这个内置函数不能修改已有的字典,它每次都会生成一个新的字典;比如尝试修改1和3 的键值,但是只会生成一个新的字典
>>> dict1.fromkeys((1, 3), '数字') {1: '数字', 3: '数字'}
-
访问字典:keys(), values(), items()
-
查找字典:判断键的成员资格:get(), in/not in 判断
-
get() :
get(self, key, default=None, /) Return the value for key if key is in the dictionary, else default.
-
-
清空字典:clear(), 或者del dict(key=)不推荐直接赋值空字典{} 的方式来清空,因为有数据泄漏风险
-
浅拷贝字典:copy(), 拷贝意味着生成一个新字典,与赋值是不同的。
-
删除/弹出对应的键值:pop()
-
删除/弹出字典键值 - 默认最后一个:popitem()
-
修改字典:追加:setdefault() :和get() 类似,但是setdefault 找不到对应的值的时候,会自动添加,随机添加到某个位置,因为字典不存在顺序
-
修改字典:用字典去更新另外一个字典:update(), 类似于列表的extend()
-
Python的字典是否支持一键(Key)多值(Value)?
不支持,除非这个值是元祖和列表括起来的
-
在字典中,如果试图为一个不存在的键(Key)赋值会怎样?
会创建这个key and value
-
成员资格操作符(in和not in)可以检查一个元素是否存在序列中,当然也可以用来检查一个键(Key)是否存在字典中,那么请问哪种的检查效率更高些?为什么?
字典效率更高,因为是直接查找到相应的Key; 而序列是从第一个元素开始遍历
-
Python对键(Key)和值(Value)有没有类型限制?
没有
-
请目测下边代码执行后,字典dict1的内容是什么?
>>> dict1.fromkeys((1, 2, 3), ('one', 'two', 'three')) >>> dict1.fromkeys((1, 3), '数字')(1:('one', 'two', 'three'), 2:('one', 'two', 'three'), 3:('one', 'two', 'three') ) (1:'数字', 3:'数字' ) -
如果你需要将字典dict1 = {1: 'one', 2: 'two', 3: 'three'}拷贝到dict2,你应该怎么做?
dict2 = dict1.copy()
-
尝试编写一个用户登录程序(这次尝试将功能封装成函数),程序实现如图
# 尝试编写一个用户登录程序(这次尝试将功能封装成函数),程序实现如图
log_user = {}
welcome_msg = '''
|---新建用户:N/n---|
|---登陆账号:E/e---|
|---退出程序:Q/q---|
'''
register_msg = '''
注册成功,赶紧试试登陆吧!
'''
logon_msg = '''
欢迎进入xxoo系统,请点击右上方的x结束程序!
'''
quit_msg = '''
已成功退出系统!
'''
def logon():
name = input('请输入用户名:')
while name not in log_user.keys():
name = input('您输入的用户名不存在,请重新输入:')
passwd = input('请输入密码:')
count = 3
while log_user[name] != passwd:
count -= 1
if count > 0:
passwd = input('密码错误,请重新输入')
else:
print('密码输入错误3次,退出程序')
break
print(logon_msg)
def create():
name = input('请输入用户名:')
while name in log_user.keys():
name = input('此用户已经被使用,请重新输入:')
log_user.setdefault(name, input('请输入密码:'))
print(register_msg)
def logon_main():
while True:
print(welcome_msg, end='')
code = input('|---请输入指令代码:')
if code == 'N' or code == 'n':
create()
elif code == 'E' or code == 'e':
logon()
elif code == 'Q' or code == 'q':
print(quit_msg)
break
if __name__ == '__main__':
logon_main()
-
集合是字典的“表亲”, type = set, 用花括号括起一堆没有映射关系的元素
>>> num = {} >>> type(num) <class 'dict'> >>> >>> >>> num2 = {1, 2, 3, 4} >>> type(num2) <class 'set'> -
集合的元素是唯一,会自动过滤掉重复的元素
>>> num2 = {1, 2, 3, 4, 5, 4, 3, 2, 1} >>> >>> num2 {1, 2, 3, 4, 5} -
集合的元素是无序的,无法通过索引操作元素
>>> num2[2] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'set' object is not subscriptable -
创建集合
-
直接把一堆元素用花括号括起来
-
使用set() 工厂函数, 可以传入序列参数
>>> set1 = set([1, 2, 3, 4, 5, 5]) >>> set1 {1, 2, 3, 4, 5}
-
-
一个例子
要求:去掉列表中重复的元素 [0, 1, 2, 3, 4, 5, 5, 3, 1]
>>> list1 = [0, 1, 2, 3, 4, 5, 5, 3, 1] >>> >>> list2 = list(set(list1)) >>> list2 [0, 1, 2, 3, 4, 5]注意:set 函数得到的集合是无序的!!!
- add()
- remove()
-
不可变集合: 通过frozenset()
>>> num3 = frozenset([1, 23, 4, 4]) >>> num3 frozenset({1, 4, 23}) >>> >>> num3.add(0) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'
-
请问集合的唯一作用是什么呢?
确保集合中的元素具有唯一性
-
如果你希望创建的集合是不变的,应该怎么做?
frozenset()
-
请问如何确定一个集合里边有多少个元素?
len() 函数
-
请目测一下代码会打印什么内容?
>>> num_set = set([1,2,3,4,5]) >>> num_set[0]报错,集合是无序的,没有索引
-
请问set1 = {[1,2]}和set1 = set([1,2])执行的结果一样吗?
不一样,第一个会报错,第二个会生成一个集合
-
打开你的IDLE,输入set1 ={1,1.0},你发现了什么?
过滤掉相同的元素,得到{1}
-
请问如何给集合添加和删除元素?
add(), remove()
-
自学扩展:自己花点时间看下这个表格

-
文件的处理流程: 输入,处理, 输出
-
什么是文件:.exe, .txt, .ppt, .jpg, .mp4, .avi
-
打开文件:
打开模式 执行操作 'r' 以只读方式打开文件(默认) 'w' 以写入的方式打开文件,会覆盖已存在的文件 'x' 如果文件已存在,使用此模式打开将引发异常 'a' 以写入模式打开,如果文件存在,则在末尾追加写入 'b' 以二进制模式打开文件 't' 以文本模式打开(默认) '+' 可读写模式(可添加到其他模式中使用) 'U' 通用换行符支持 -
文件对象方法:
文件对象方法 执行操作 f.close() 关闭文件 f.read([size=-1]) 从文件读取size个字符,当未给定size或给定负值的时候,读取剩余的所有字符,然后作为字符串返回 f.readline([size=-1]) 从文件中读取并返回一行(包括行结束符),返回字符串,如果有size有定义则返回size个字符 f.write(str) 将字符串str写入文件 f.writelines(seq) 向文件写入字符串序列seq,seq应该是一个返回字符串的可迭代对象 f.seek(offset, from) 在文件中移动文件指针,从from(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offset个字节 f.tell() 返回当前在文件中的位置 f.truncate([size=file.tell()]) 截取文件到size个字节,默认是截取到文件指针当前位置 f.readlines() readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存。 -
f.read() 读一次,文件指针移动(类似于书签)一次;如果未指定size,会读取所有字符,指针移动到文件末尾;再次运行f.read(),就什么都读不出来了
>>> f = open('record.txt') >>> f.read() '小客服:小甲鱼?,今天有?客户问你有没有女朋友?\n小甲鱼:咦???\n小客服:我跟她说你有女朋友了!\n小甲鱼:。。。。。\n小客服:"她让你分手后考虑下她!然后我说您要买个优盘,我就帮您留意~\n小甲鱼:下次有人想调戏你我不阻止~\n小客服:滚!!!\n==========================================================\n小客服:小甲鱼,有个好评很好笑哈。\n小甲鱼:哦?\n小客服:"有了小甲小客服:嗯嗯,我看了你的微博丫~小甲鱼哟西~\n小客服:那个有条回复"左手拿著小甲魚,右手拿著打火機,哪裡不會點哪裡,?soeasy^...^"\n小甲鱼:T_T\n======================================鱼?,今天一?一个会员想找你\n小甲鱼:哦?什么事?\n小客服:他说你一个学生月薪已经超过12k了!?!\n小甲鱼:哪里的?\n小客服:上海的\n小甲鱼:那正常,哪家公司?\n小客服:他没说呀。\n小甲鱼:哦:滚!!!\n' >>> f.read() ''
-
f.tell() 可以查看当前文件指针位置
>>> f = open('record.txt') >>> f.read(5) '小客服:小' >>> >>> f.tell() 13
注意: 由于我实验里面的record.txt 是utf-8 编码,所以一个中文字符是3个字节;如果是gbk编码的话,一个中文字符是2个字节
-
f.seek(offset, from) 可以用来修改文件指针位置; f.readline() 打印一行
>>> f.seek(46,0) 46 >>> f.readline() '没有女朋友?\n'
-
可以直接迭代文件对象,来打印出文件的每一行
f = open('record.txt') for each_line in f: print(each_line, end='') f.close() -
f.write(str), f.writelines(seq, 比如list对象), 写入的类型都是字符串类型
>>> f = open('test.txt', 'w') >>> f.write('I love fishc') 12 >>> f.close() >>> f = open('test.txt', 'w') >>> list1 = ['I', 'live', 'fishc'] >>> list1 ['I', 'live', 'fishc'] >>> f.writelines(list1) >>> >>> f.close()
-
-
下边只有一种方式不能打开文件,请问是哪一种,为什么?
f = open('E:/test.txt','w') #A f = open('E:\test.txt','w') #B f = open('E://test.txt','w') #C f = open('E:\\test.txt','w') #D
B,没有对反斜杠进行转义, Windows在路径名中既可以接受斜线(/)也可以接受反斜线(\),不过如果使用反斜线作为路径名的分隔符的话,要注意使用双反斜线(\)进行转义,否则Python会将反斜线进行转义,例如(\n)看成一个换行符,(\t)看作一个制表符等
-
打开一个文件我们使用open()函数,通过设置文件的打开模式,决定打开的文件具有哪些性质,请问默认的打开模式是什么呢?
‘rt’,即可读,文本的模式打开
-
请问>>>open(‘E:\Test.bin’,‘xb’)是以什么样的模式打开文件的?
以“可写入以及二进制模式”打开文件“E:\Test.bin”。 这里要注意的是’x’和’w’均是以“可写入”的模式打开文件,但以’x’模式打开的时候,如果路径下已经存在相同的文件名,会抛出异常,而’w’模式的话会直接覆盖同名文件。 因此,'w’模式打开文件会比较危险,容易导致此前的内容遗失,因此使用’w’模式打开文件前先检查该文件名是否已经存在显得非常重要!
-
尽管python有所谓的“垃圾回收机制”,但对于打开了的文件,在不需要用到的时候我们仍然需要使用f.close()将文件对象“关闭”,这是为什么呢?
Python拥有垃圾收集机制,会在文件对象的引用计数降至零的时候自动关闭文件,所以在Python编程里,如果忘记关闭文件并不会造成内存泄漏那么危险。 但并不是说就可以不要关闭文件,如果你对文件进行了写入操作,那么你应该在完成写入之后进行关闭文件。因为Python可能会缓存你写入的数据,如果这中间断电了神马的,那些缓存的数据根本就不会写入到文件中。所以,为了安全起见,要养成使用完文件后立刻关闭的优雅习惯。
-
如何将一个文件对象(f)中的数据存放进列表中?
list(f)
-
如何迭代打印出文件对象(f)中的每一行数据?
for each_line in f: print(each_line)
-
文件对象的内置方法f.read([size=-1])作用是读取文件对象内容,size参数是可选的,那如果设置了size=10,例如f.read(10),将返回什么内容呢?
读取文件指针当前位置往后读10个字符
-
如何获得文件对象(f)当前文件指针的位置?
f.tell() -
还是视频中的那个演示文件(record.txt),请问为何f.seek(45,0)不会出错,但f.seek(46)就出错了呢?
>>> f.seek(46) 46 >>> f.readline() >Traceback (most recent call last): >File "<pyshell#18>", line 1, in <module> >f.readline()因为使用f.seek()定位的文件指针是按字节为单位进行计算的,演示文件(record.txt)是以GBK进行编码的,按照规则,一个汉字需要占用两个字节,f.seek(45)的位置位于字符“小”的开始位置,因此可以正常打印,而f.seek(46)的位置刚好位于字符“小”的中间位置,因此按照GBK编码的形式无法将其解码
-
尝试将某个文件(OpenMe.mp3)打印到屏幕上
f = open('OpenMe.mp3') for each_line in f: print(each_line, end='') f.close()
-
编写代码,将上一题中的文件(OpenMe.mp3)保存为新文件(OpenMe.txt)
f1 = open('OpenMe.mp3') f2 = open('OpenMe.txt', 'x') # 使用'x'打开更安全,避免使用‘w’打开覆盖已有的文件 f2.write(f1.read()) f1.close() f2.close()
任务:将文件(record.txt)中的数据进行分割,并按照以下规则保存起来。 1.小甲鱼的对话单独保存为boy_.txt的文件(去掉"小甲鱼:") 2.小客服的对话单独保存为girl_.txt的文件(去掉"小客服:") 3.文件中总共有三段对话,分别保存为boy_1.txt、boy_2.txt、boy_3.txt、gilr_1.txt、gilr_2.txt、gilr_3.txt 共6个文件。(提示:不同的对话已经使用"===="进行分割)
我的代码:
# 任务:将文件(record.txt)中的数据进行分割,并按照以下规则保存起来。
# 1.小甲鱼的对话单独保存为boy_*.txt的文件(去掉"小甲鱼:")
# 2.小客服的对话单独保存为girl_*.txt的文件(去掉"小客服:")
# 3.文件中总共有三段对话,分别保存为boy_1.txt、boy_2.txt、boy_3.txt、gilr_1.txt、gilr_2.txt、gilr_3.txt
# 共6个文件。(提示:不同的对话已经使用"===="进行分割)
f1 = open('../28/record.txt', 'rt')
count = 1
boy_list = []
girl_list = []
def generate_file(file_name, file_list):
f_file_name = open(file_name, 'x')
f_file_name.writelines(file_list)
f_file_name.close()
for each_line in f1:
temp_list = each_line.split(':')
if temp_list[0] == '小甲鱼':
boy_list.append(temp_list[1])
elif temp_list[0] == '小客服':
girl_list.append(temp_list[1])
if "====" in each_line:
file_name_boy = 'boy_' + str(count) + '.txt'
file_name_girl = 'girl_' + str(count) + '.txt'
generate_file(file_name_boy, boy_list)
generate_file(file_name_girl, girl_list)
boy_list = []
girl_list = []
count += 1
# 循环结束,写入最后一段内容
file_name_boy = 'boy_' + str(count) + '.txt'
file_name_girl = 'girl_' + str(count) + '.txt'
generate_file(file_name_boy, boy_list)
generate_file(file_name_girl, girl_list)
# 关闭原始文件
f1.close()-
编写一个程序,接受用户的输入并保存为新的文件,程序实现如图:
# 编写一个程序,接受用户的输入并保存为新的文件,程序实现如图 name = input('请输入文件名:') # lines = [] f = open(name, 'x') print('请输入内容【单独输入\':w\' 保存退出】:') while True: # 其实是循环等待每行输入,但是让input的输入提示符为空,效果是看起来一直没有打断的输入 content = input() if content != ':w': content += '\n' f.write(content) else: break f.close()
另一种实现:
# 编写一个程序,接受用户的输入并保存为新的文件,程序实现如图 name = input('请输入文件名:') f = open(name, 'x') print('请输入内容【单独输入\':w\' 保存退出】:') # 用内置函数iter实现等待输入, 让input()遇到回车键也能持续输入 txt = '' for line in iter(input, ':w'): txt += line + '\n' f.write(txt) f.close()
-
编写一个程序,比较用户输入的两个文件,如果不同,显示出所有不同处的行号与第一个不同字符的位置,程序实现如图:
# 编写一个程序,比较用户输入的两个文件,如果不同,显示出所有不同处的行号与第一个不同字符的位置,程序实现如图: name1 = input('请输入需要比较的头一个文件名:') name2 = input('请输入需要比较的另一个文件名:') name1_f = open(name1, 'rt') name2_f = open(name2, 'rt') name1_list = name1_f.readlines() name2_list = name2_f.readlines() name1_f.close() name2_f.close() diff_count = [] name1_len = len(name1_list) name2_len = len(name2_list) if name1_len >= name2_len: file_min_len = name2_len else: file_min_len = name1_len for i in range(file_min_len): if name1_list[i] != name2_list[i]: diff_count.append(i) print('两个文件共有【 %d 】处不同:' % len(diff_count)) for each in diff_count: print('第 %d 行不一样' % each)
另一种写法:
def cp_file(fname1, fname2): name1_f = open(fname1, 'rt') name2_f = open(fname2, 'rt') diff_row = [] count = 0 row_number = 1 for each_line in name1_f: if each_line != name2_f.readline(): count += 1 diff_row.append(row_number) row_number += 1 name2_f.close() name2_f.close() if count == 0: print('两个文件相同') else: print('两个文件共有【 %d 】处不同:' % count) for each in diff_row: print('第 %d 行不一样' % each) def cp_main(): name1 = input('请输入需要比较的头一个文件名:') name2 = input('请输入需要比较的另一个文件名:') cp_file(name1, name2) if __name__ == '__main__': cp_main()
-
编写一个程序,当用户输入文件名和行数(N)后,将该文件的前N行内容打印到屏幕上,程序实现如图:
# 编写一个程序,当用户输入文件名和行数(N)后,将该文件的前N行内容打印到屏幕上,程序实现如图: def show_file(name, rows): f_open = open(name, 'rt') for i in range(int(rows)): print(f_open.readline(), end='') f_open.close() f_name = input('请输入要打开的文件:') f_rows = input('请输入需要显示该文件前几行:') print('文件 %s 的前 %s 的内容如下:' % (f_name, f_rows)) if __name__ == '__main__': show_file(f_name, f_rows)
-
呃,不得不说我们的用户变得越来越刁钻了。要求在上一题的基础上扩展,用户可以随意输入需要显示的行数。(如输入13:21打印第13行到第21行,输入:21打印前21行,输入21:则打印从第21行开始到文件结尾所有内容)
# 呃,不得不说我们的用户变得越来越刁钻了。
# 要求在上一题的基础上扩展,用户可以随意输入需要显示的行数。
# (如输入13:21打印第13行到第21行,输入:21打印前21行,输入21:则打印从第21行开始到文件结尾所有内容)
def show_file(name, rows):
f_open = open(name, 'rt')
f_lines = f_open.readlines()
start_s, end_s = rows.split(':')
if start_s == '':
row_start = 0
row_start_msg = '开始'
else:
row_start = int(start_s)-1
row_start_msg = '第' + start_s + '行'
if end_s == '':
row_end = len(f_lines)
row_end_msg = '末尾'
else:
row_end = int(end_s)
row_end_msg = '第' + end_s + '行'
print('文件 %s 从 %s 到 %s 行的内容如下:' % (f_name, row_start_msg, row_end_msg))
for each_line in range(row_start, row_end):
print(f_lines[each_line], end='')
f_open.close()
f_name = input('请输入要打开的文件:')
f_rows = input('请输入需要显示的行数【格式如 13:21 或 :21 或 21:】:')
if __name__ == '__main__':
show_file(f_name, f_rows)-
编写一个程序,实现“全部替换”功能,程序实现如图:
# 编写一个程序,实现“全部替换”功能,程序实现如图: def file_replace(name, o_str, n_str): f_read = open(name, 'rt') f_content = f_read.read() f_read.close() count = f_content.count(o_str) if count == 0: print('没有找到需要替换的字符') else: print('文件 %s **有 %d 个 【%s】' %(name, count, o_str)) print('你确定要把所有【%s】的替换为【%s】吗' %(o_str, n_str)) answer = input('[YES/NO]:') if answer == 'YES': f_content = f_content.replace(o_str, n_str) f_write = open(name, 'w') f_write.write(f_content) f_write.close() f_name = input('请输入文件名:') old_str = input('请输入需要替换的单词或字符:') new_str = input('请输入新的单词或字符:') if __name__ == '__main__': file_replace(f_name, old_str, new_str)
-
模块:它是包含所有你定义的函数和变量的文件,后缀是py;模块可以被别的程序引入,以使用该模块的函数等功能
使用模块之前,需要先导入模块:import module
>>> secret = random.randint(1, 10) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'random' is not defined >>> >>> import random >>> secret = random.randint(1, 10) >>> secret 4
-
OS 模块:
我们所知道常用的操作系统有:windows,Mac OS, Linux, Unix等等,这些操作系统底层对于文件系统的访问工作原理是不一样的,因此你可能要针对不同的系统来考虑使用哪些文件系统模块。这样的做法是非常不友好且麻烦的,因为这样就意味着当你的程序运行环境一旦改变,你就要相应的去修改大量的代码来应付
有了OS 模块,我们不需要关心什么操作系统下使用什么模块,OS模块会帮你选择正确的模块并调用
- os模块中关于文件/目录常用的函数使用方法
函数名 使用方法 getcwd() 返回当前工作目录 chdir(path) 改变工作目录 listdir(path='.') 列举指定目录中的文件名('.'表示当前目录,'..'表示上一级目录) mkdir(path) 创建单层目录,如该目录已存在抛出异常 makedirs(path) 递归创建多层目录,如该目录已存在抛出异常,注意:'E:\a\b'和'E:\a\c'并不会冲突 remove(path) 删除文件 rmdir(path) 删除单层目录,如该目录非空则抛出异常 removedirs(path) 递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常 rename(old, new) 将文件old重命名为new system(command) 运行系统的shell命令 walk(top) 遍历top路径以下所有的子目录,返回一个三元组:(路径, [包含目录], [包含文件])【具体实现方案请看:第30讲课后作业^_^】 以下是支持路径操作中常用到的一些定义,支持所有平台 os.curdir 指代当前目录('.') os.pardir 指代上一级目录('..') os.sep 输出操作系统特定的路径分隔符(Win下为'\',Linux下为'/') os.linesep 当前平台使用的行终止符(Win下为'\r\n',Linux下为'\n') os.name 指代当前使用的操作系统(包括:'posix', 'nt', 'mac', 'os2', 'ce', 'java') >>> import os >>> os.getcwd() '/Users/felix' >>> os.chdir('/Users/felix/PycharmProjects/learningpython/30') >>> >>> >>> >>> os.listdir('.') [] >>> >>> >>> os.mkdir('A') >>> os.mkdir('B') >>> os.mkdir('./C/D') Traceback (most recent call last): File "<stdin>", line 1, in <module> FileNotFoundError: [Errno 2] No such file or directory: './C/D' >>> >>> os.listdir('.') ['A', 'B'] >>> >>> os.makedirs('./C/D') >>> os.listdir() ['A', 'C', 'B'] >>> os.remove os.remove( os.removedirs( >>> os.removedirs('C') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/Cellar/python@3.9/3.9.12_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/os.py", line 243, in removedirs rmdir(name) OSError: [Errno 66] Directory not empty: 'C' >>> >>> >>> os.removedirs('./C/D') >>> >>> os.listdir() ['A', 'B'] >>> os.rename('B', 'D') >>> os.listdir() ['A', 'D'] >>> os.system('ls -l') total 0 drwxr-xr-x 2 felix staff 64 May 24 08:57 A drwxr-xr-x 2 felix staff 64 May 24 08:58 D 0 >>> os.listdir(os.curdir) ['A', 'D'] >>> >>> os.listdir(os.pardir) ['03', '04', '05', '02', '20', '18', '29', '16', '28', '17', '10', '19', '26', 'test.py', 'README.md', '09', '30', '01', '06', '.git', '24', '23', '15', '14', '22', '.idea', '25'] >>> os.listdir(os.pardir+ '/29') ['05.py', 'task.py', 'example_2.py', '01_1.py', '04.py', 'boy_1.txt', 'boy_2.txt', 'boy_3.txt', '03.py', 'girl_1.txt', '02_1.py', 'girl_2.txt', 'p_02.py', 'input_nonstop.py', 'girl_3.txt'] >>> os.name 'posix'
-
OS.PATH 模块
- os.path模块中关于路径常用的函数使用方法
函数名 使用方法 basename(path) 去掉目录路径,单独返回文件名 dirname(path) 去掉文件名,单独返回目录路径 join(path1[, path2[, ...]]) 将path1, path2各部分组合成一个路径名 split(path) 分割文件名与路径,返回(f_path, f_name)元组。如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在 splitext(path) 分离文件名与扩展名,返回(f_name, f_extension)元组 getsize(file) 返回指定文件的尺寸,单位是字节 getatime(file) 返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) getctime(file) 返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) getmtime(file) 返回指定文件最新的修改时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) 以下为函数返回 True 或 False exists(path) 判断指定路径(目录或文件)是否存在 isabs(path) 判断指定路径是否为绝对路径 isdir(path) 判断指定路径是否存在且是一个目录 isfile(path) 判断指定路径是否存在且是一个文件 islink(path) 判断指定路径是否存在且是一个符号链接 ismount(path) 判断指定路径是否存在且是一个挂载点 samefile(path1, paht2) 判断path1和path2两个路径是否指向同一个文件 >>> import os.path >>> >>> os.path.basename(os.curdir + 'A/sexy.txt') 'sexy.txt' >>> >>> >>> os.path.dirname(os.curdir + 'A/sexy.txt') '.A' >>> >>> >>> >>> os.path.join('A', 'B', 'C') 'A/B/C' >>> os.path.join('.', 'A', 'B', 'C') './A/B/C' >>> os.path.split(os.curdir + 'A/sexy.txt') ('.A', 'sexy.txt') >>> os.path.getsize(os.pardir+ '/29/05.py') 926 >>> >>> os.path.getatime(os.pardir+ '/29/05.py') 1653282351.295187 >>> >>> os.path.getmtime(os.pardir+ '/29/05.py') 1653279681.7378166 >>> import time >>> time.gmtime(os.path.getmtime(os.pardir+ '/29/05.py')) time.struct_time(tm_year=2022, tm_mon=5, tm_mday=23, tm_hour=4, tm_min=21, tm_sec=21, tm_wday=0, tm_yday=143, tm_isdst=0) >>> time.localtime(os.path.getmtime(os.pardir+ '/29/05.py')) time.struct_time(tm_year=2022, tm_mon=5, tm_mday=23, tm_hour=12, tm_min=21, tm_sec=21, tm_wday=0, tm_yday=143, tm_isdst=0) >>> os.path.exists(os.curdir + '/A/sexy.txt') False >>> >>> os.path.exists(os.curdir + '/A') True >>> os.path.isabs(os.curdir + '/A') False >>> >>> os.path.isdir(os.curdir + '/A') True
-
编写一个程序,统计当前目录下每个文件类型的文件数,程序实现如图:
# 编写一个程序,统计当前目录下每个文件类型的文件数,程序实现如图: import os import os.path def count_ext(file_path): ext_dic = {} count = 0 dir_elements = os.listdir(file_path) for each in dir_elements: ext = os.path.splitext(each)[1] if ext not in ext_dic.keys(): ext_dic.setdefault(ext, 1) else: ext_dic[ext] += 1 for each_ext in ext_dic.keys(): if each_ext =='': print('文件夹:【 %s 】下共有类型为文件夹的文件 %d 个' % (file_path, ext_dic[each_ext])) else: print('文件夹:【 %s 】下共有类型为 [ %s ] 的文件 %d 个' % (file_path, each_ext, ext_dic[each_ext])) count_ext(os.path.curdir)
-
编写一个程序,计算当前文件夹下所有文件的大小,程序实现如图:
# 编写一个程序,计算当前文件夹下所有文件的大小,程序实现如图: import os import os.path def file_size(f_path): os.chdir(f_path) file_list = list(filter(lambda x: os.path.isfile(x), os.listdir(f_path))) for each_file in file_list: print(each_file + ' 【%d Bytes】 ' % os.path.getsize(each_file)) if __name__ == '__main__': file_size(input('please input the path:'))
-
编写一个程序,用户输入文件名以及开始搜索的路径,搜索该文件是否存在。如遇到文件夹,则进入文件夹继续搜索,程序实现如图:
# 编写一个程序,用户输入文件名以及开始搜索的路径,搜索该文件是否存在。如遇到文件夹,则进入文件夹继续搜索,程序实现如图 import os import os.path def search_file(path, file_name): os.chdir(path) temp_folder_name = list(filter(lambda x: os.path.isdir(x), os.listdir(path))) temp_file_name = list(filter(lambda x: os.path.isfile(x), os.listdir(path))) if file_name in temp_file_name: print(os.path.join(path, file_name)) if temp_folder_name: for sub_folder_name in temp_folder_name: search_file(os.path.join(path, sub_folder_name), file_name) if __name__ == '__main__': search_file(input('请输入待查找的初始目录:'), input('请输入需要查找的目标文件:'))
还可以通过os.walk() 来实现:
# 编写一个程序,用户输入文件名以及开始搜索的路径,搜索该文件是否存在。如遇到文件夹,则进入文件夹继续搜索,程序实现如图 import os import os.path def search_file(path, file_name): # os.walk() 返回的是一个三元组迭代器,有三元组参数,通过for 循环使用 for folder, sub_folders, sub_files in os.walk(path): if file_name in sub_files: print(os.path.join(folder, file_name)) if __name__ == '__main__': search_file(input('请输入待查找的初始目录:'), input('请输入需要查找的目标文件:'))
-
编写一个程序,用户输入开始搜索的路径,查找该路径下(包含子文件夹)所有的视频格式文件(要求查找mp4,rmvb,avi的格式即可),并创建一个文件(vedioList.txt)存放找到的文件的路径,程序实现如图:
# 编写一个程序,用户输入开始搜索的路径,查找该路径下(包含子文件夹)所有的视频格式文件(要求查找mp4,rmvb,avi的格式即可), # 并创建一个文件(vedioList.txt)存放找到的文件的路径,程序实现如图: import os import os.path file_list = [] def search_video(path, format_list=['.mp4', '.rmvb', '.avi']): os.chdir(path) temp_folder = list(filter(lambda x: os.path.isdir(x), os.listdir(path))) temp_file = list(filter(lambda x: (os.path.isfile(x) and os.path.splitext(x)[1] in format_list), os.listdir(path))) file_list.extend(os.path.join(path, each_file) for each_file in temp_file) if temp_folder: for sub_folder in temp_folder: search_video(os.path.join(path, sub_folder)) f_video_list = open('/Users/felix/PycharmProjects/learningpython/vedioList.txt', 'w') # 如果直接使f_video_list.writelines(file_list) 写入的文件内容没有换行 # f_video_list.writelines(file_list) for each_file_path in file_list: f_video_list.write(each_file_path) f_video_list.write('\n') f_video_list.close() if __name__ == '__main__': search_video(input('请输入待查找的初始目录:'))
-
编写一个程序,用户输入关键字,查找当前文件夹内(如果当前文件夹内包含文件夹,则进入文件夹继续搜索)所有含有该关键字的文本文件(.txt后缀),要求显示该文件所在的位置以及关键字在文件中的具体位置(第几行第几个字符),程序实现如图:
# 编写一个程序,用户输入关键字,查找当前文件夹内(如果当前文件夹内包含文件夹,则进入文件夹继续搜索)所有含有该关键字的文本文件(.txt后缀), # 要求显示该文件所在的位置以及关键字在文件中的具体位置(第几行第几个字符),程序实现如图 import os import os.path # 存放所有目录和子目录下的txt 文件,并且是绝对路径 sub_full_txt = [] file_row_keyword = {} def search_keyword(path, keyword): for folder, sub_folders, sub_files in os.walk(path): # 过滤出txt 文件 sub_files_txt = list(filter(lambda x: os.path.splitext(x)[1] == '.txt', sub_files)) # 转换成绝对路径的txt 文件 sub_full_txt.extend(os.path.join(folder, each_file) for each_file in sub_files_txt) for file_name in sub_full_txt: f_open = open(file_name, 'r', encoding='utf-8') f_lines = f_open.readlines() f_open.close() # 预先定义一个子字典存储行数和关键字位置关系信息 row_keyword = {} for row_number in range(len(f_lines)): f_keyword_index = [] start_flag = 0 f_keyword_number = f_lines[row_number].find(keyword, start_flag) while f_keyword_number >= 0: f_keyword_index.append(f_keyword_number) start_flag = f_keyword_number + 1 f_keyword_number = f_lines[row_number].find(keyword, start_flag) if f_keyword_number == -1: row_keyword.setdefault(row_number+1, f_keyword_index) if file_name in file_row_keyword.keys(): file_row_keyword[file_name] = row_keyword else: file_row_keyword.setdefault(file_name, row_keyword) # 函数返回一个字典,key=文件路径,value=(以行数为key,以位置信息列表为value 的字典),如下 # { # 'C:/Users/felix_yang/PycharmProjects/learningpython\\28\\record.txt': {5: [16], 6: [4]}, # 'C:/Users/felix_yang/PycharmProjects/learningpython\\29\\boy_1.txt': {3: [0]}, # 'C:/Users/felix_yang/PycharmProjects/learningpython\\29\\boy_2.txt': {3: [0]}, # 'C:/Users/felix_yang/PycharmProjects/learningpython\\29\\girl_1.txt': {3: [12, 23], 7: [12, 23]} # } return file_row_keyword if __name__ == '__main__': filename = input('请输入待查找的初始目录:') keyword = input('请输入需要查找的关键字:') search_keyword(filename, keyword) for file_key in file_row_keyword.keys(): print('============================================') print('在文件【%s】中找到关键字【%s】' % (file_key, keyword)) for rows in file_row_keyword[file_key].keys(): # 将字典存储的位置信息转换成字符串打印 key_str = [str(i) for i in file_row_keyword[file_key][rows]] print('关键字出现在第 %d 行,第 【 %s 】 位置' % (rows, ','.join(key_str)))
请输入待查找的初始目录:C:/Users/felix_yang/PycharmProjects/learningpython 请输入需要查找的关键字:小甲鱼 ============================================ 在文件【C:/Users/felix_yang/PycharmProjects/learningpython\28\record.txt】中找到关键字【小甲鱼】 关键字出现在第 1 行,第 【 4 】 位置 关键字出现在第 2 行,第 【 0 】 位置 关键字出现在第 4 行,第 【 0 】 位置 关键字出现在第 6 行,第 【 0 】 位置 关键字出现在第 8 行,第 【 0 】 位置 关键字出现在第 10 行,第 【 0 】 位置 关键字出现在第 13 行,第 【 4 】 位置 关键字出现在第 14 行,第 【 0 】 位置 关键字出现在第 15 行,第 【 7 】 位置 关键字出现在第 16 行,第 【 0 】 位置 关键字出现在第 17 行,第 【 16 】 位置 关键字出现在第 19 行,第 【 0 】 位置 关键字出现在第 21 行,第 【 4 】 位置 关键字出现在第 22 行,第 【 0 】 位置 关键字出现在第 24 行,第 【 0 】 位置 关键字出现在第 26 行,第 【 0 】 位置 关键字出现在第 28 行,第 【 0 】 位置 关键字出现在第 30 行,第 【 0 】 位置 ============================================ 在文件【C:/Users/felix_yang/PycharmProjects/learningpython\29\girl_1.txt】中找到关键字【小甲鱼】 关键字出现在第 1 行,第 【 0 】 位置 ============================================ 在文件【C:/Users/felix_yang/PycharmProjects/learningpython\29\girl_2.txt】中找到关键字【小甲鱼】 关键字出现在第 1 行,第 【 0 】 位置 关键字出现在第 2 行,第 【 3 】 位置 关键字出现在第 3 行,第 【 12 】 位置 ============================================ 在文件【C:/Users/felix_yang/PycharmProjects/learningpython\29\girl_3.txt】中找到关键字【小甲鱼】 关键字出现在第 1 行,第 【 0 】 位置 Process finished with exit code 0




我们之前学习了文件和文件系统,我们知道从一个文件里面去读取字符串是非常简单的,但是你如果要试图读取出数值的话,那么就要多费点周折了,因为无论你是使用read()方法还是readline()方法,都是返回一个字符串,如果我们希望从字符串中取出数值的话,我们会使用int()或float()函数,把类似于1,2,3或者3.14的字符串强制转换为整型或者浮点型数值,我们一直在讲保存文件,然而当你要保存的数据像列表,字典,集合甚至是类的实例这些更加复杂的数据类型的时候,你就会举手无措了,兴许你可能会把这些都转化为字符串,然后再写入到一个文本文件中保存起来,但是很快你就会发现,把这个过程反过来的时候,也就是从文本文件中恢复数据对象,即把一个字符串恢复成列表,字典,集合,类的实例的时候,你会发现这异常的困难,所幸的是,Python提供了一个标准的模块(pickle)使用这个模块,我们就可以轻松地将列表,字典,集合,类的实例这类复杂的类型转换为二进制文件了。这个模块就是我们要学习的pickle模块了。
-
令人惊叹的模块,几乎可以把所有的python 对象 转换成二进制的形式存储.
import pickle -
存取数据:pickling - pickle.dump(src_object, pickle_file_object)
-
读取数据:unpickling - pickle.load(pickle_file_object)
>>> import pickle >>> >>> my_list = [123, 1232, '小甲鱼'] >>> >>> pickle_file = open('my_list.pkl', 'wb') >>> pickle.dump(my_list, pickle_file) >>> pickle_file.close() >>> pickle_file = open('my_list.pkl', 'rb') >>> my_list2 = pickle.load(pickle_file) >>> my_list2 [123, 1232, '小甲鱼'] >>> pickle_file.close() -
可以把一些大数据“腌制成泡菜“ ,即保存成一个pkl 二进制文件,在代码中导入进行引用,使得代码更加简洁优雅
-
pickle的实质是什么?
pickle的实质就是利用一些算法将你的数据对象“腌制”成二进制文件,存储在磁盘上,当然也可以放在数据库或者通过网络传输到另一台计算机上。
-
使用pickle的什么方法存储数据?
pickle.dump(src_object, pickle_file_object); 第一个参数是待存储的数据对象,第二个参数是目标存储的文件对象,注意要先使用’wb’的模式open文件哦
-
使用pickle的什么方法读取数据?
pickle.load(pickle_file_object); 参数是目标存储的文件对象,注意要先使用’rb’的模式open文件哦
-
使用pickle能不能保存为”*.txt”类型的文件?
可以,不过打开后是乱码,因为是以二进制的模式写入的。
-
编写一个程序,这次要求使用pickle将文件( record.txt (1.1 KB, 下载次数: 3561) )里的对话按照以下要求腌制成不同文件(没错,是第29讲的内容小改,考考你自己能写出来吗?): ※小甲鱼的对话单独保存为boy_.txt的文件(去掉“小甲鱼:”) ※小客服的对话单独保存为girl_.txt的文件(去掉“小客服:”) ※文件中总共有三段对话,分别保存为boy_1.txt, girl_1.txt,boy_2.txt, girl_2.txt, boy_3.txt, gril_3.txt共6个文件(提示:文件中不同的对话间已经使用“==========”分割)
# 编写一个程序,这次要求使用pickle将文件( record.txt (1.1 KB, 下载次数: 3561) )里的对话按照以下要求腌制成不同文件(没错,是第29讲的内容小改,考考你自己能写出来吗?): # ※小甲鱼的对话单独保存为boy_*.txt的文件(去掉“小甲鱼:”) # ※小客服的对话单独保存为girl_*.txt的文件(去掉“小客服:”) # ※文件中总共有三段对话,分别保存为boy_1.txt, girl_1.txt,boy_2.txt, girl_2.txt, boy_3.txt, gril_3.txt共6个文件 # (提示:文件中不同的对话间已经使用“==========”分割) import pickle def extract(file_name): count = 0 boy_list = [] girl_list = [] record_file = open(file_name, 'r') for each_line in record_file: temp_list = each_line.split(':') if temp_list[0] == '小甲鱼': boy_list.append(temp_list[1]) elif temp_list[0] == '小客服': girl_list.append(temp_list[1]) if '========' in each_line: count += 1 pickle_file_boy = open('boy_%d.txt' % count, 'wb') pickle_file_girl = open('girl_%d.txt' % count, 'wb') pickle.dump(boy_list, pickle_file_boy) pickle.dump(girl_list, pickle_file_girl) pickle_file_boy.close() pickle_file_girl.close() boy_list = [] girl_list = [] count += 1 pickle_file_boy = open('boy_%d.txt' % count, 'wb') pickle_file_girl = open('girl_%d.txt' % count, 'wb') pickle.dump(boy_list, pickle_file_boy) pickle.dump(girl_list, pickle_file_girl) pickle_file_boy.close() pickle_file_girl.close() record_file.close() extract('record.txt')
| 异常 | 描述 |
|---|---|
| AssertionError | 断言语句(assert)失败 |
| AttributeError | 尝试访问未知的对象属性 |
| EOFError | 用户输入文件末尾标志EOF(Ctrl+d) |
| FloatingPointError | 浮点计算错误 |
| GeneratorExit | generator.close()方法被调用的时候 |
| ImportError | 导入模块失败的时候 |
| IndexError | 索引超出序列的范围 |
| KeyError | 字典中查找一个不存在的关键字 |
| KeyboardInterrupt | 用户输入中断键(Ctrl+c) |
| MemoryError | 内存溢出(可通过删除对象释放内存) |
| NameError | 尝试访问一个不存在的变量 |
| NotImplementedError | 尚未实现的方法 |
| OSError | 操作系统产生的异常(例如打开一个不存在的文件) |
| OverflowError | 数值运算超出最大限制 |
| ReferenceError | 弱引用(weak reference)试图访问一个已经被垃圾回收机制回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| StopIteration | 迭代器没有更多的值 |
| SyntaxError | Python的语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab和空格混合使用 |
| SystemError | Python编译器系统错误 |
| SystemExit | Python编译器进程被关闭 |
| TypeError | 不同类型间的无效操作 |
| UnboundLocalError | 访问一个未初始化的本地变量(NameError的子类) |
| UnicodeError | Unicode相关的错误(ValueError的子类) |
| UnicodeEncodeError | Unicode编码时的错误(UnicodeError的子类) |
| UnicodeDecodeError | Unicode解码时的错误(UnicodeError的子类) |
| UnicodeTranslateError | Unicode转换时的错误(UnicodeError的子类) |
| ValueError | 传入无效的参数 |
| ZeroDivisionError | 除数为零 |
- AssertionError
- AttributeError
- IndexError
- KeyError
- NameError
- SyntaxError
- TypeError
- ZeroDivisionError
>>> mylist = ['小甲鱼是帅哥']
>>> assert len(mylist) > 0
>>> mylist.pop()
'小甲鱼是帅哥'
>>> mylist
[]
>>>
>>> assert len(mylist) > 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
>>> mylist.fishc
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'fishc'
>>> my_list = [1, 2, 3]
>>>
>>> my_list[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
>>> my_dict = {'one':1, 'two':2}
>>>
>>> my_dict['one']
1
>>> my_dict['four']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'four'
>>>
>>>
>>> my_dict.get('four')
>>> mylist1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'mylist1' is not defined
>>> print 'I love FishC'
File "<stdin>", line 1
print 'I love FishC'
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print('I love FishC')?
>>> 1 + '1'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'
>>> 1/0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero-
结合你自身的编程经验,总结下异常处理机制的重要性?
由于环境的不确定性和用户操作的不可以预知性都可能导致程序出现各种问题,因此异常机制最重要的无非就是:增强程序的健壮性和用户体验,尽可能的捕获所有预知的异常并写好处理的代码,当异常出现的时候,程序自动消化并恢复正常(不至于崩溃)。|
-
请问以下代码是否会产生异常,如果会的话,请写出异常的名称
>>> my_list = [1, 2, 3, 4,,]
SyntaxError
-
请问以下代码是否会产生异常,如果会的话,请写出异常的名称
>>> my_list = [1, 2, 3, 4, 5] >>> print(my_list[len(my_list)])
IndexError
-
请问以下代码是否会产生异常,如果会的话,请写出异常的名称
>>> my_list = [3, 5, 1, 4, 2] >>> my_list.sorted()
列表的排序方法叫 list.sort(),sorted() 是BIF。因此会引发 AttributeError: ‘list’ object has no attribute ‘sorted’ 异常。
-
请问以下代码是否会产生异常,如果会的话,请写出异常的名称
>>> my_dict = {'host': 'http://bbs.fishc.com', 'port': '80'} >>> print(my_dict['server'])
KeyError
-
请问以下代码是否会产生异常,如果会的话,请写出异常的名称
def my_fun(x, y): print(x, y) my_fun(x=1, 2)
SyntaxError 如果使用关键字参数的话,需要两个参数均使用关键字参数 my_fun(x=1, y=2)
-
请问以下代码是否会产生异常,如果会的话,请写出异常的名称
f = open('C:\\test.txt', wb) f.write('I love FishC.com!\n') f.close()
NameError
注意 open() 第二个参数是字符串,应该 f = open(‘C:\test.txt’, ‘wb’) 。wb不加双引号 Python 还以为是变量名呢,往上一找,艾玛没找着……引发 NameError 异常。由于打开文件失败,接着下边一连串与 f 相关的均会报同样异常。
-
请问以下代码是否会产生异常,如果会的话,请写出异常的名称:
def my_fun1(): x = 5 def my_fun2(): x *= x return x return my_fun2() my_fun1()
闭包的知识大家还记得不? Python 认为在内部函数的 x 是局部变量的时候,外部函数的 x 就被屏蔽了起来,所以执行 x *= x 的时候,在右边根本就找不到局部变量 x 的值,因此报错。 在 Python3 之前没有直接的解决方案,只能间接地通过容器类型来存放,因为容器类型不是放在栈里,所以不会被“屏蔽”掉。容器类型这个词儿大家是不是似曾相识?我们之前介绍的字符串、列表、元祖,这些啥都可以往里的扔的就是容器类型啦。
def my_fun1(): x = [5] def my_fun2(): x[0] *= x[0] return x[0] return my_fun2() my_fun1()
但是到了 Python3 的世界里,又有了不少的改进,如果我们希望在内部函数里可以修改外部函数里的局部变量的值,那么也有一个关键字可以使用,就是 nonlocal:
def my_fun1(): x = 5 def my_fun2(): nonlocal x x *= x return x return my_fun2() my_fun1()
-
try-except 语句 : Try 语句一旦检测到异常,剩下的语句不会被执行
try: 检测范围 except Exceptions[as reason] 出现异常(exception)后的处理代码Example-1:
try: # OSError,尝试打开一个不存在的文件 f = open('我为什么是个文件.txt') print(f.read()) f.close() except OSError: print('文件出错啦@')
output:
文件出错啦@Example-2:
try: # OSError,尝试打开一个不存在的文件 f = open('我为什么是个文件.txt') print(f.read()) f.close() except OSError as reason: print('文件出错啦@ \n错误的原因是:' + str(reason))
output:
文件出错啦@ 错误的原因是:[Errno 2] No such file or directory: '我为什么是个文件.txt'Example-3:
try: #TypeError sum_umber = 1 + '1' # OSError,尝试打开一个不存在的文件 f = open('我为什么是个文件.txt') print(f.read()) f.close() except OSError as reason: print('文件出错啦@ \n错误的原因是:' + str(reason)) except TypeError as reason: print('类型出错啦@ \n错误的原因是:' + str(reason))
output:
类型出错啦@ 错误的原因是:unsupported operand type(s) for +: 'int' and 'str'注意由于检测到
sum_umber = 1 + '1'异常,会直接跳到except TypeError as reason, 主程序的剩余代码不会被执行Example-4: 直接用except,无论什么出错,都能cover到; 但是太笼统,实际中并不推荐 ,比如如果用户用
ctrl+c想中断关闭程序,会由于KeyboardInterrupt 异常被捕获而触发出错Error,反而导致程序不会中断关闭try: int('abc') sum_umber = 1 + '1' f = open('我为什么是个文件.txt') print(f.read()) f.close() except: print('出错啦@')
output:
出错啦@Example-5:
try: sum_umber = 1 + '1' f = open('我为什么是个文件.txt') print(f.read()) f.close() except (OSError, TypeError): print('文件出错啦@')
output:
出错啦@ -
try-finally 语句: 做收尾工作
try: 检测范围 except Exceptions[as reason]: 出现异常(Exception)后的处理代码 finally: 无论如何都会被执行的代码try: f = open('我为什么是个文件.txt', 'w') f.write('我存在了!') sum_umber = 1 + '1' except (OSError, TypeError): print('文件出错啦@') finally: f.close()
-
raise 语句触发异常
>>> 1/0 Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: division by zero >>> raise ZeroDivisionError Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError
-
我们使用什么方法来处理程序中出现的异常?
try-except-finally
-
一个 try 语句可以和多个 except 语句搭配吗?为什么?
可以,针对不同的errortype 可以使用不同的except的语句
-
你知道如何统一处理多类异常吗?
使用元祖:
except (OSError, TypeError): -
except 后边如果不带任何异常类,Python 会捕获所有(try 语句块内)的异常并统一处理,但小甲鱼却不建议这么做,你知道为什么吗?
太笼统,实际中并不推荐* ,比如如果用户用
ctrl+c想中断关闭程序,会由于KeyboardInterrupt 异常被捕获而触发出错Error,反而导致程序不会中断关闭 -
如果异常发生在成功打开文件后,Python 跳到 except 语句执行,并没有执行关闭文件的命令(用户写入文件的数据就可能没有保存起来),因此我们需要确保无论如何(就算出了异常退出)文件也要被关闭,我们应该怎么做呢?
使用finally 保证代码块一定会被执行; 如果 try 语句块中没有出现任何运行时错误,会跳过 except 语句块执行 finally 语句块的内容。
-
请恢复以下代码中马赛克挡住的内容,使得程序执行后可以按要求输出。
try: for i in range(3): for j in range(3): if i == 2: raise KeyboardInterrupt print(i, j) except KeyboardInterrupt: print('推出啦!')

-
还记得我们第一个小游戏吗?只要用户输入非整型数据,程序立刻就会蹦出不和谐的异常信息然后崩溃。请使用刚学的异常处理方法修改以下程序,提高用户体验。
import random secret = random.randint(1, 10) print('------------------我爱鱼C工作室------------------') temp = input("不妨猜一下小甲鱼现在心里想的是哪个数字:") try: guess = int(temp) except ValueError as reason: print('输入类型出错啦@ \n出错类型: %s' % str(reason)) guess = secret while guess != secret: temp = input("哎呀,猜错了,请重新输入吧:") guess = int(temp) if guess == secret: print("我草,你是小甲鱼心里的蛔虫吗?!") print("哼,猜中了也没有奖励!") else: if guess > secret: print("哥,大了大了~~~") else: print("嘿,小了,小了~~~") print("游戏结束,不玩啦^_^")
-
input() 函数有可能产生两类异常:EOFError(文件末尾endoffile,当用户按下组合键 Ctrl+d 产生)和 KeyboardInterrupt(取消输入,当用户按下组合键 Ctrl+c 产生),再次修改上边代码,捕获处理 input() 的两类异常,提高用户体验
import random secret = random.randint(1, 10) print('------------------我爱鱼C工作室------------------') try: temp = input("不妨猜一下小甲鱼现在心里想的是哪个数字:") guess = int(temp) except (KeyboardInterrupt, EOFError) as reason: print('用户中断 \n原因: %s' % str(reason)) guess = secret except ValueError as reason: print('输入类型出错啦@ \n出错类型: %s' % str(reason)) guess = secret while guess != secret: temp = input("哎呀,猜错了,请重新输入吧:") guess = int(temp) if guess == secret: print("我草,你是小甲鱼心里的蛔虫吗?!") print("哼,猜中了也没有奖励!") else: if guess > secret: print("哥,大了大了~~~") else: print("嘿,小了,小了~~~") print("游戏结束,不玩啦^_^")
-
尝试一个新的函数 int_input(),当用户输入整数的时候正常返回,否则提示出错并要求重新输入
# 尝试一个新的函数 int_input(),当用户输入整数的时候正常返回,否则提示出错并要求重新输入 def int_input(msg=''): flag = True try: number = input(msg) temp = int(number) except ValueError as reason: print('输入类型出错啦@ \n出错类型: %s' % str(reason)) flag = False while flag: if isinstance(temp, int): return temp break else: temp = input('error captured, please input again\n') print(int_input())
优化的程序:
def int_input(prompt=''): while True: try: int(input(prompt)) break except ValueError: print('出错,您输入的不是整数!') int_input('请输入一个整数:')
-
把文件关闭放在 finally 语句块中执行还是会出现问题,像下边这个代码,当前文件夹中并不存在"My_File.txt"这个文件,那么程序执行起来会发生什么事情呢?你有办法解决这个问题吗?
try: f = open('My_File.txt') # 当前文件夹中并不存在"My_File.txt"这个文件T_T print(f.read()) except OSError as reason: print('出错啦:' + str(reason)) finally: f.close()
try: f = open('My_File.txt') # 当前文件夹中并不存在"My_File.txt"这个文件T_T print(f.read()) except OSError as reason: print('出错啦:' + str(reason)) finally: if 'f' in locals(): # 如果文件对象变量存在当前局部变量符号表的话,说明打开成功 f.close()
-
要么怎样,要么不怎样
- if-else
-
干完了能怎样,干不完就别想怎样 ;
-
和for 语句或者while 语句搭配
def showMaxFactor(number): count = number // 2 while count > 1: if number % count == 0: print('%d 的最大约数是 %d' %(number, count)) break count -= 1 else: print('%d 是一个素数' % number) num = int(input('please input a number:')) showMaxFactor(num)
-
-
没有问题,那就干吧
-
和异常处理搭配
try: a = int(input('input a number:')) except ValueError: print('出错啦!') else: print(a)
-
-
一个例子
try: f = open('test.txt', 'w') for each_line in f: print(each_line) except OSError as reason: print('出错啦!' + str(reason)) finally: f.close()
使用with 改进之后:
try: with open('test.txt', 'w') as f: for each_line in f: print(each_line) except OSError as reason: print('出错啦!' + str(reason))
-
with 语句会monitor 打开的文件,会自动关闭,不需要再用
f.close()
-
在 Python 中,else 语句能跟哪些语句进行搭配?
if, while, for 和 try-except
-
请问以下例子中,循环中的 break 语句会跳过 else 语句吗?
def showMaxFactor(num): count = num // 2 while count > 1: if num % count == 0: print('%d最大的约数是%d' % (num, count)) break count -= 1 else: print('%d是素数!' % num) num = int(input('请输入一个数:')) showMaxFactor(num)
会,因为如果将 else 语句与循环语句(while 和 for 语句)进行搭配,那么只有在循环正常执行完成后才会执行 else 语句块的内容。
-
请目测以下代码会打印什么内容?
try: print('ABC') except: print('DEF') else: print('GHI') finally: print('JKL')
ABC
GHI
JKL
-
使用什么语句可以使你不必再担心文件打开后却忘了关闭的尴尬?
try: with open('data.txt', 'w') as f: for each_line in f: print(each_line) except OSError as reason: print('出错啦:' + str(reason))
使用with语句
-
使用 with 语句固然方便,但如果出现异常的话,文件还会自动正常关闭吗?
with 语句会自动处理文件的打开和关闭,如果中途出现异常,会执行清理代码,然后确保文件自动关闭。g
-
你可以换一种形式写出下边的伪代码吗?
with A() as a: with B() as b: suite
with A() as a, B() as b: suite
-
使用 with 语句改写以下代码,让 Python 去关心文件的打开与关闭吧。
def file_compare(file1, file2): f1 = open(file1) f2 = open(file2) count = 0 # 统计行数 differ = [] # 统计不一样的数量 for line1 in f1: line2 = f2.readline() count += 1 if line1 != line2: differ.append(count) f1.close() f2.close() return differ file1 = input('请输入需要比较的头一个文件名:') file2 = input('请输入需要比较的另一个文件名:') differ = file_compare(file1, file2) if len(differ) == 0: print('两个文件完全一样!') else: print('两个文件共有【%d】处不同:' % len(differ)) for each in differ: print('第 %d 行不一样' % each)
使用with 之后的代码:
def file_compare(file1, file2): # f1 = open(file1) # f2 = open(file2) with open(file1) as f1, open(file2) as f2: count = 0 # 统计行数 differ = [] # 统计不一样的数量 for line1 in f1: line2 = f2.readline() count += 1 if line1 != line2: differ.append(count) return differ file1 = input('请输入需要比较的头一个文件名:') file2 = input('请输入需要比较的另一个文件名:') differ = file_compare(file1, file2) if len(differ) == 0: print('两个文件完全一样!') else: print('两个文件共有【%d】处不同:' % len(differ)) for each in differ: print('第 %d 行不一样' % each)
-
你可以利用异常的原理,修改下面的代码使得更高效率的实现吗?
print('|--- 欢迎进入通讯录程序 ---|') print('|--- 1:查询联系人资料 ---|') print('|--- 2:插入新的联系人 ---|') print('|--- 3:删除已有联系人 ---|') print('|--- 4:退出通讯录程序 ---|') contacts = dict() while 1: instr = int(input('\n请输入相关的指令代码:')) if instr == 1: name = input('请输入联系人姓名:') if name in contacts: print(name + ' : ' + contacts[name]) else: print('您输入的姓名不再通讯录中!') if instr == 2: name = input('请输入联系人姓名:') if name in contacts: print('您输入的姓名在通讯录中已存在 -->> ', end='') print(name + ' : ' + contacts[name]) if input('是否修改用户资料(YES/NO):') == 'YES': contacts[name] = input('请输入用户联系电话:') else: contacts[name] = input('请输入用户联系电话:') if instr == 3: name = input('请输入联系人姓名:') if name in contacts: del(contacts[name]) # 也可以使用dict.pop() else: print('您输入的联系人不存在。') if instr == 4: break print('|--- 感谢使用通讯录程序 ---|')
使用条件语句的代码非常直观明了,但是效率不高。因为程序会两次访问字典的键,一次判断是否存在(例如
if name in contacts),一次获得值(例如print(name + ' : ' + contacts[name]))如果利用异常解决方案,我们可以简单避开每次需要使用 in 判断是否键存在字典中的操作。因为只要当键不存在字典中时,会触发 KeyError 异常,利用此特性我们可以修改代码如下:
print('|--- 欢迎进入通讯录程序 ---|') print('|--- 1:查询联系人资料 ---|') print('|--- 2:插入新的联系人 ---|') print('|--- 3:删除已有联系人 ---|') print('|--- 4:退出通讯录程序 ---|') contacts = dict() while 1: instr = int(input('\n请输入相关的指令代码:')) if instr == 1: name = input('请输入联系人姓名:') try: print(name + ' : ' + contacts[name]) except KeyError: print('您输入的姓名不再通讯录中!') if instr == 2: name = input('请输入联系人姓名:') try: print('您输入的姓名在通讯录中已存在 -->> ', end='') print(name + ' : ' + contacts[name]) if input('是否修改用户资料(YES/NO):') == 'YES': contacts[name] = input('请输入用户联系电话:') except KeyError: contacts[name] = input('请输入用户联系电话:') if instr == 3: name = input('请输入联系人姓名:') try: del (contacts[name]) # 也可以使用dict.pop() except KeyError: print('您输入的联系人不存在。') if instr == 4: break print('|--- 感谢使用通讯录程序 ---|')
-
导入easygui模块 - 3种方法; 推荐使用
import easygui as g>>> import easygui >>> >>> easygui.msgbox('hi') 'OK' >>> from easygui import * >>> >>> msgbox('hi') 'OK' >>> >>> import easygui as g >>> g.msgbox('hi') 'OK'
-
使用easygui
-
建议不要在IDLE上运行Easygui
-
一个简单的例子
import easygui as g import sys while 1: g.msgbox("嗨,欢迎进入第一个界面小游戏") msg = "请问你但愿在鱼C工做室学习到什么知识呢" title="小游戏互动" choices=["谈恋爱","编程","OOXX","琴棋书画"] choice=g.choicebox(msg,title,choices) #note that we convert choice to string,in case #the user cancelled the choice,and we got None g.msgbox("你的选择是:"+str(choice),"结果") msg="你但愿从新开始小游戏吗?" title=" 请选择" if g.ccbox(msg,title): #show a Contiue/Cancel dialog pass #user chose Contonue else: sys.exit(0) #user chose Cancel
-
-
安装 EasyGUI
官网:https://github.com/robertlugg/easygui
使用 pip 进行安装:
-
什么是 EasyGUI?
EasyGUI 是 Python 中一个非常简单的 GUI 编程模块,不同于其他的 GUI 生成器,它不是事件驱动的。相反,所有的 GUI 交互都是通过简单函数调用就可以实现。
EasyGUI 为用户提供了简单的 GUI 交互接口,不需要程序员知道任何有关 tkinter,框架,部件,回调或 lambda 的任何细节。
EasyGUI 可以很好地兼容 Python 2 和 3,并且不存在任何依赖关系。
EasyGUI 是运行在 Tkinter 上并拥有自身的事件循环,而 IDLE 也是 Tkinter 写的一个应用程序并也拥有自身的事件循环。因此当两者同时运行的时候,有可能会发生冲突,且带来不可预测的结果。因此如果你发现你的 EasyGUI 程序有这样的问题,请尝试在 IDLE 外去运行你的程序。
-
一个简单的例子
在 EasyGui 中,所有的 GUI 互动均是通过简单的函数调用,下边一个简单的例子告诉你 EasyGui 确实很 Easy!
1 import easygui as g 2 import sys 3 4 while 1: 5 g.msgbox("嗨,欢迎进入第一个界面小游戏^_^") 6 7 msg ="请问你希望在鱼C工作室学习到什么知识呢?" 8 title = "小游戏互动" 9 choices = ["谈恋爱", "编程", "OOXX", "琴棋书画"] 10 11 choice = g.choicebox(msg, title, choices) 12 13 # 注意,msgbox的参数是一个字符串 14 # 如果用户选择Cancel,该函数返回None 15 g.msgbox("你的选择是: " + str(choice), "结果") 16 17 msg = "你希望重新开始小游戏吗?" 18 title = "请选择" 19 20 # 弹出一个Continue/Cancel对话框 21 if g.ccbox(msg, title): 22 pass # 如果用户选择Continue 23 else: 24 sys.exit(0) # 如果用户选择Cancel
-
EasyGUI 的各种功能演示
要运行 EasyGUI 的演示程序,在命令行调用 EasyGUI 是这样的:
python easygui.py或者可以从 IDE(例如 IDLE, PythonWin, Wing, 等等)上调用:
>>> import easygui >>> easygui.egdemo()
成功调用后将可以尝试 EasyGUI 拥有的各种功能,并将结果打印至控制台。
-
导入 EasyGUI
为了使用 EasyGUI 这个模块,你应该先导入它。
最简单的导入语句是:
import easygui如果使用上面这种形式导入的话,那么你使用 EasyGUI 的函数的时候,必须在函数的前面加上前缀 easygui,像这样:
easygui.msgbox(...)另一种选择是导入整个 EasyGUI 包:
from easygui import *这使得我们更容易调用 EasyGUI 的函数,可以直接这样编写代码:
msgbox(...)第三种方案是使用类似下边的 import 语句:
import easygui as g这种方法还可以让你保持 EasyGUI 的命名空间,同时减少你的打字数量。
导入之后就可以这么调用 EasyGUI 的函数:
g.msgbox(...) -
使用 EasyGUI
一旦你的模块导入 EasyGUI,GUI 操作就是一个简单的调用 EasyGUI 函数的几个参数的问题了。
例如,使用 EasyGUI 来实现世界上最著名的打招呼:
import easygui as g g.msgbox("Hello, world!")
-
EasyGUI 函数的默认参数
对于所有对话框而言,前两个参数都是消息主体和对话框标题。
按照这个规律,在某种情况下,这可能不是理想的布局设计(比如当对话框在获取目录或文件名的时候会选择忽略消息参数),但保持这种一致性且贯穿于所有的窗口部件是更为得体的考虑! 绝大部分的 EasyGUI 函数都有默认参数,几乎所有的组件都会显示消息主体和对话框标题。
标题默认是空字符串,消息主体通常有一个简单的默认值。
这使得你可以尽可能少的去设置参数,比如 msgbox() 函数标题部分的参数是可选的,因此你调用 msgbox() 的时候只需要指定一个消息参数即可,例如:
>>> msgbox('我爱hale^_^')当然你也可以指定标题参数和消息参数,例如:
>>> msgbox('我爱hale^_^', 'AG自述')在各类按钮组件里,默认的消息是 “Shall I continue?”,所以你可以不带任何参数地去调用它们。
这里我们演示不带任何参数地去调用 ccbox(),当选择 “cancel” 或关闭窗口的时候返回一个布尔类型的值:
if ccbox(): pass # 用户选择继续 else: return # 用户选择取消这里return会报错SyntaxError: 'return' outside function
return关键字只能在def自定义函数里面使用,(在while循环中只能使用break关键字来结束循环!这里没有自定义函数,所以不能出现return这样的关键字!) -
使用关键字参数调用 EasyGUI 的函数
调用 EasyGUI 函数还可以使用关键字参数哦。
现在假设你需要使用一个按钮组件,但你不想指定标题参数(第二个参数),你仍可以使用关键字参数的方法指定 choices 参数(第三个参数),像这样:
>>> choices = ['愿意', '不愿意', '有钱的时候就愿意'] >>> reply = choicebox('你愿意购买资源打包支持小甲鱼吗?', choices = choices) -
使用按钮组件
根据需求,EasyGUI 在 buttonbox() 上建立了一系列的函数供调用。
8.1. msgbox()
msgbox(msg='(Your message goes here)', title=' ', ok_button='OK', image=None, root=None)
msgbox() 显示一个消息和提供一个 “OK” 按钮,你可以指定任意的消息和标题,你甚至可以重写 “OK” 按钮的内容。
重写 “OK” 按钮最简单的方法是使用关键字参数:
>>> msgbox("我一定要学会编程!", ok_button="加油!")8.2. ccbox()
ccbox(msg='Shall I continue?', title=' ', choices=('C[o]ntinue', 'C[a]ncel'), image=None, default_choice='C[o]ntinue', cancel_choice='C[a]ncel')
ccbox() 提供一个选择:“C[o]ntinue” 或者 “C[a]ncel”,并相应的返回 True 或者 False。
注意:“C[o]ntinue” 中的 [o] 表示快捷键,也就是说当用户在键盘上敲一下 o 字符,就相当于点击了 “C[o]ntinue” 按键。
8.3. ynbox()
ynbox(msg='Shall I continue?', title=' ', choices=('[]Yes', '[]No'), image=None, default_choice='[]Yes', cancel_choice='[]No')
跟 ccbox() 一样,只不过这里默认的 choices 参数值不同而已,[] 表示将键盘上的 F1 功能按键作为 “Yes” 的快捷键使用。
8.4. buttonbox()
buttonbox(msg='', title=' ', choices=('Button[1]', 'Button[2]', 'Button[3]'), image=None, images=None, default_choice=None, cancel_choice=None, callback=None, run=True)
可以使用 buttonbox() 定义自己的一组按钮,buttonbox() 会显示一组由你自定义的按钮。
当用户点击任意一个按钮的时候,buttonbox() 返回按钮的文本内容。
如果用户点击取消或者关闭窗口,那么会返回默认选项(第一个选项)。
请看例子:
8.5. indexbox()
indexbox(msg='Shall I continue?', title=' ', choices=('Yes', 'No'), image=None, default_choice='Yes', cancel_choice='No')
基本跟 buttonbox() 一样,区别就是当用户选择第一个按钮的时候返回序号 0, 选择第二个按钮的时候返回序号 1。
8.6. boolbox()
boolbox(msg='Shall I continue?', title=' ', choices=('[Y]es', '[N]o'), image=None, default_choice='Yes', cancel_choice='No')
如果第一个按钮被选中则返回 True,否则返回 False。
-
如何在 buttonbox 里边显示图片
当你调用一个 buttonbox 函数(例如 msgbox(), ynbox(), indexbox() 等等)的时候,你还可以为关键字参数 image 赋值,可以设置一个 .gif 格式的图像(PNG 格式的图像也是支持的哦^_^):
buttonbox('大家说我长得帅吗?', image='turtle.gif', choices=('帅', '不帅', '!@#$%'))这里Python3需要安装pillow库才可加载jpg等其他图像
-
为用户提供一系列选项
10.1. choicebox()
choicebox(msg='Pick an item', title='', choices=[], preselect=0, callback=None, run=True)
按钮组件方便提供用户一个简单的按钮选项,但如果有很多选项,或者选项的内容特别长的话,更好的策略是为它们提供一个可选择的列表。 choicebox() 为用户提供了一个可选择的列表,使用序列(元祖或列表)作为选项,这些选项会按照字母进行排序。
另外还可以使用键盘来选择其中一个选项(比较纠结,但一点儿都不重要):
- 例如当按下键盘上的 “g” 键,将会选中的第一个以 “g” 开头的选项。再次按下 “g” 键,则会选中下一个以 “g” 开头的选项。在选中最后一个以 “g” 开头的选项的时候,再次按下 “g” 键将重新回到在列表的开头的第一个以 “g” 开头的选项。
- 如果选项中没有以 “g” 开头的,则会选中字符排序在 “g” 之前(“f”)的那个字符开头的选项
- 如果选项中没有字符的排序在 “g” 之前的,那么在列表中第一个元素将会被选中。
10.2. multchoicebox()
multchoicebox(msg='Pick an item', title='', choices=[], preselect=0, callback=None, run=True)
multchoicebox() 函数也是提供一个可选择的列表,与 choicebox() 不同的是,multchoicebox() 支持用户选择 0 个,1 个或者同时选择多个选项。
multchoicebox() 函数也是使用序列(元祖或列表)作为选项,这些选项显示前会按照不区分大小写的方法排好序。

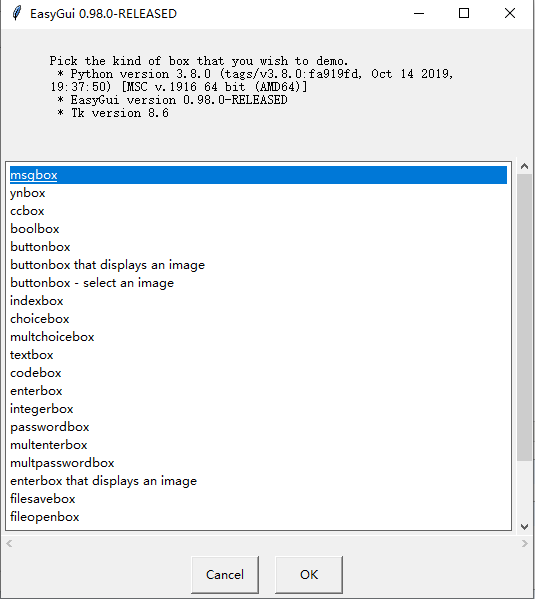
-
让用户输入消息
11.1. enterbox()
enterbox(msg='Enter something.', title=' ', default='', strip=True, image=None, root=None)
enterbox() 为用户提供一个最简单的输入框,返回值为用户输入的字符串。
默认返回的值会自动去除首尾的空格,如果需要保留首尾空格的话请设置参数 strip=False。
11.2. integerbox()
integerbox(msg='', title=' ', default=None, lowerbound=0, upperbound=99, image=None, root=None)
integerbox() 为用户提供一个简单的输入框,用户只能输入范围内(lowerbound 参数设置最小值,upperbound 参数设置最大值)的整型数值,否则会要求用户重新输入。
11.3 multenterbox()
multenterbox(msg='Fill in values for the fields.', title=' ', fields=[], values=[], callback=None, run=True)
multenterbox() 为用户提供多个简单的输入框,要注意以下几点:
- 如果用户输入的值比选项少的话,则返回列表中的值用空字符串填充用户未输入的选项。
- 如果用户输入的值比选项多的话,则返回的列表中的值将截断为选项的数量。
- 如果用户取消操作,则返回域中的列表的值或者 None 值。
实现如下图(源代码在第35讲的课后作业中^_^):

-
让用户输入密码
有时候可能需要让用户输入密码等敏感信息,那么界面看上去应该是这样的:******。
12.1. passwordbox()
passwordbox(msg='Enter your password.', title=' ', default='', image=None, root=None)
passwordbox() 跟 enterbox() 样式一样,不同的是用户输入的内容用星号(*)显示出来,该函数返回用户输入的字符串:
12.2 multpasswordbox()
multpasswordbox(msg='Fill in values for the fields.', title=' ', fields=(), values=(), callback=None, run=True)
multpasswordbox() 跟 multenterbox() 使用相同的接口,但当它显示的时候,最后一个输入框显示为密码的形式(*):
13. 显示文本
EasyGUI 还提供函数用于显示文本。
13.1 textbox()
textbox(msg='', title=' ', text='', codebox=False, callback=None, run=True)
textbox() 函数默认会以比例字体(参数 codebox=True 设置为等宽字体)来显示文本内容(自动换行),这个函数适合用于显示一般的书面文字。
注:text 参数设置可编辑文本区域的内容,可以是字符串、列表或者元祖类型。
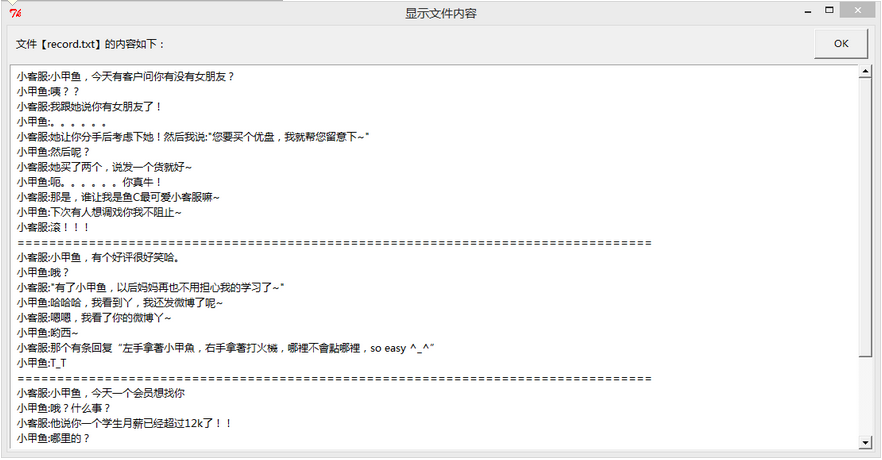
13.2 codebox()
codebox(msg='', title=' ', text='')
codebox() 以等宽字体显示文本内容(不自动换行),相当于 textbox(codebox=True)
注:等宽字体很丑的,但适合代码编写,不信你试试看@_@
14. 目录与文件
GUI 编程中一个常见的场景是要求用户输入目录及文件名,EasyGUI 提供了一些基本函数让用户来浏览文件系统,选择一个目录或文件。
14.1 diropenbox()
diropenbox(msg=None, title=None, default=None)
diropenbox() 函数用于提供一个对话框,返回用户选择的目录名(带完整路径哦),如果用户选择 “Cancel” 则返回 None。
default 参数用于设置默认的打开目录(请确保设置的目录已存在)。
14.2 fileopenbox()
fileopenbox(msg=None, title=None, default='*', filetypes=None, multiple=False)
fileopenbox() 函数用于提供一个对话框,返回用户选择的文件名(带完整路径哦),如果用户选择 “Cancel” 则返回 None。
关于 default 参数的设置方法:
- default 参数指定一个默认路径,通常包含一个或多个通配符。
- 如果设置了 default 参数,fileopenbox() 显示默认的文件路径和格式。
- default 默认的参数是 '*',即匹配所有格式的文件。
例如:
- default="c:/fishc/*.py" 即显示 C:\fishc 文件夹下所有的 Python 文件。
- default="c:/fishc/test*.py" 即显示 C:\fishc 文件夹下所有的名字以 test 开头的 Python 文件。
关于 filetypes 参数的设置方法:
- 可以是包含文件掩码的字符串列表,例如:filetypes = ["*.txt"]
- 可以是字符串列表,列表的最后一项字符串是文件类型的描述,例如:filetypes = [".css", [".htm", "*.html", "HTML files"]]
最后是 multiple 参数,如果为 True 则表示可以同时选择多个文件。
14.3 filesavebox()
filesavebox(msg=None, title=None, default='', filetypes=None)
filesavebox() 函数提供一个对话框,让用于选择文件需要保存的路径(带完整路径哦),如果用户选择 “Cancel” 则返回 None。
default 参数应该包含一个文件名(例如当前需要保存的文件名),当然也可以设置为空的,或者包含一个文件格式掩码的通配符。
filetypes 参数的设置方法请参考 fileopenbox() 函数。
15. 记住用户的设置
15.1 EgStore
GUI 编程中一个常见的场景就是要求用户设置一下参数,然后保存下来,以便下次用户使用你的程序的时候可以记住他的设置。
为了实现对用户的设置进行存储和恢复这一过程,EasyGUI 提供了一个叫做 EgStore 的类。
为了记住某些设置,你的应用程序必须定义一个类(下面案例中的 “Settings”)继承自 EgStore 类。
然后你的应用程序必须创建一个该类的实例化对象(下面案例中的 “settings”)。
设置类的构造函数(init 方法)必须初始化所有的你想要它所记住的那些值。
一旦你这样做了,你就可以在 settings 对象中通过设定值去实例化变量,从而很简单地记住设置。
之后使用 settings.store() 方法在硬盘上持久化保存。
2020-07-14 21:53:13 类的知识暂未掌握!!!
下面创建一个叫做 “Settings” 的类:
from easygui import EgStore
# 定义一个叫做“Settings”的类,继承自EgStore类
class Settings(EgStore):
def __init__(self, filename): # 需要指定文件名
# 指定要记住的属性名称
self.author = ""
self.book = ""
# 必须执行下面两个语句
self.filename = filename
self.restore()
# 创建“Settings”的实例化对象“settings”
settingsFilename = "settings.txt"
settings = Settings(settingsFilename)
author = "小甲鱼"
book = "《零基础入门学习Pyhon》"
# 将上面两个变量的值保存到“settings”对象中
settings.author = author
settings.book = book
settings.store()
print("\n保存完毕\n")
16. 捕获异常
exceptionbox()
使用 EasyGUI 编写 GUI 程序,有时候难免会产生异常。当然这取决于你如何运行你的应用程序,当你的应用程序崩溃的时候,堆栈追踪可能会被抛出,或者被写入到 stdout 标准输出函数中。
EasyGUI 通过 exceptionbox() 函数提供了更好的方式去处理异常。
当异常出现的时候,exceptionbox() 会将堆栈追踪显示在一个 codebox() 中,并且允许你做进一步的处理。
exceptionbox() 很容易使用,下面举个例子:
try:
print('I Love FishC.com!')
int('FISHC') # 这里会产生异常
except:
exceptionbox()
-
先练练手,把我们的刚开始的那个猜数字小游戏加上界面吧?
# 先练练手,把我们的刚开始的那个猜数字小游戏加上界面吧? import random import sys import easygui as g g.msgbox("嗨,欢迎进入第一个界面小游戏^_^") secret = random.randint(1, 10) msg = "不妨猜一下小甲鱼现在心里想的是哪个数字(1~10):" title = "数字小游戏" guess = g.integerbox(msg, title, lowerbound=1, upperbound=10) # 如果选择cancel,直接退出 if not guess: sys.exit() while True: if guess == secret: g.msgbox("我草,你是小甲鱼心里的蛔虫吗?!") g.msgbox("哼,猜中了也没有奖励!") break else: if guess > secret: g.msgbox("哥,大了大了~~~") else: g.msgbox("嘿,小了,小了~~~") guess = g.integerbox(msg, title, lowerbound=1, upperbound=10) g.msgbox("游戏结束,不玩啦^_^")
-
实现一个用于登记用户账号信息的界面(如果是带*号的必填项,要求一定要有输入并且不能是空格)
# 实现一个用于登记用户账号信息的界面(如果是带*号的必填项,要求一定要有输入并且不能是空格) import easygui as g import sys message = "【真实姓名】为必填项 \n【手机号码】为必填项 \n【*E-mail地址】为必填项 " title = "账号中心" fields = ['*用户名', '*真实姓名', '固定电话', '*手机号码', 'QQ', '*E-mail'] result = g.multenterbox(msg=message, title=title, fields=fields, values=['小甲鱼'], callback=None, run=True) while True: if not result: sys.exit() elif result[1].isspace() or not result[1]: g.msgbox('【真实姓名】为必填项, 一定要有输入并且不能是空格') elif result[3].isspace() or not result[3]: g.msgbox('【手机号码】为必填项, 一定要有输入并且不能是空格') elif result[5].isspace() or not result[5]: g.msgbox('【E-mail】为必填项, 一定要有输入并且不能是空格') else: break result = g.multenterbox(msg=message, title=title, fields=fields, values=['小甲鱼'], callback=None, run=True) g.msgbox('登记成功@!')
-
提供一个文件浏览框,让用户选择需要打开的文本文件,打开并显示文件内容
# 提供一个文件浏览框,让用户选择需要打开的文本文件,打开并显示文件内容 import easygui as g import sys f_name = g.fileopenbox(msg=None, title=None, default='*', filetypes=None, multiple=False) if f_name: message = "文件" + f_name + "的内容如下: " title = "显示文件内容" with open(f_name, 'r') as f: f_content = f.readlines() g.textbox(msg=message, title=title, text=f_content, codebox=False, callback=None, run=True) else: sys.exit()
-
在上一题的基础上增强功能:当用户点击“OK”按钮的时候,比较当前文件是否修改过,如果修改过,则提示“覆盖保存”、“放弃保存”或“另存为…”并实现相应的功能。
# 在上一题的基础上增强功能:当用户点击“OK”按钮的时候,比较当前文件是否修改过, # 如果修改过,则提示“覆盖保存”、“放弃保存”或“另存为…”并实现相应的功能。 import easygui as g import sys import os.path def mfile_action(m_choice): if m_choice == '覆盖保存': with open(f_name, 'r') as fo: temp_content = fo.readlines() with open(f_name, 'w') as fw: fw.writelines(temp_content) elif m_choice == '放弃保存': with open(f_name, 'w') as fw: fw.writelines(f_content) elif m_choice == '另存为': # with open(f_name, 'r') as fo: # temp_content = fo.readlines() new_fname = g.filesavebox(msg=None, title=None, default='', filetypes=None) if new_fname: with open(f_name, 'r') as fo: temp_content = fo.readlines() with open(new_fname, 'x') as fs: fs.writelines(temp_content) else: sys.exit() f_name = g.fileopenbox(msg=None, title=None, default='*', filetypes=None, multiple=False) old_mtime = os.path.getmtime(f_name) if f_name: message = "文件" + f_name + "的内容如下: " title = "显示文件内容" with open(f_name, 'r') as f: f_content = f.readlines() print(f_content) if g.textbox(msg=message, title=title, text=f_content, codebox=False, callback=None, run=True): new_mtime = os.path.getmtime(f_name) if new_mtime != old_mtime: warn_msg = '检测到文件内容发生改变,请选择以下操作:' warn_title = '警告' warn_choices = ['覆盖保存', '放弃保存', '另存为'] choice = g.buttonbox(msg=warn_msg, title=warn_title, choices=warn_choices, image=None, images=None, default_choice=None, cancel_choice=None, callback=None, run=True) mfile_action(choice) else: sys.exit()
-
写一个程序统计你当前代码量的总和,并显示离十万行代码量还有多远?
要求一:递归搜索各个文件夹 要求二:显示各个类型的源文件和源代码数量 要求三:显示总行数与百分比
# 写一个程序统计你当前代码量的总和,并显示离十万行代码量还有多远? # 要求一:递归搜索各个文件夹 要求二:显示各个类型的源文件和源代码数量 要求三:显示总行数与百分比 import easygui as g import sys import os import os.path def code_cal(dir_path): format_list = ['.py', '.tf', '.sh'] code_lines = 0 ext_dic = {'.py': [0, 0], '.tf': [0, 0], '.sh':[0, 0]} # os.walk() 返回的是一个三元组迭代器,有三元组参数,通过for 循环使用 for folder, sub_folders, sub_files in os.walk(dir_path): for each_file in sub_files: ext_temp = os.path.splitext(each_file)[1] if ext_temp in format_list: ext_dic[ext_temp][0] += 1 with open(os.path.join(folder, each_file), 'r') as f_py: len_temp = len(f_py.readlines()) ext_dic[ext_temp][1] += len_temp code_lines += len_temp return code_lines, ext_dic f_path = g.diropenbox(msg=None, title=None, default=None) if f_path: total_lines, ext_row_line = code_cal(f_path) message = '您目前共累计编写了 {0} 行代码,完成进度 {1:.2%} \n 离 {2} 行代码还差 {3} 行,请继续努力'.format( total_lines, total_lines/100000, 100000, 100000-total_lines ) text_title = '统计结果' text_content = '' for each in ext_row_line.keys(): text_content += '[{0}]源文件 {1} 个,源代码 {2} 行 \n'.format( each, ext_row_line[each][0], ext_row_line[each][1] ) g.textbox(msg=message, title=text_title, text=text_content) else: sys.exit()
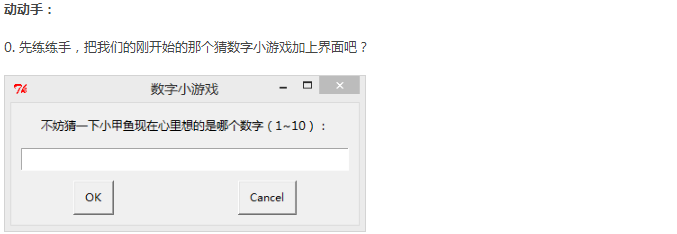
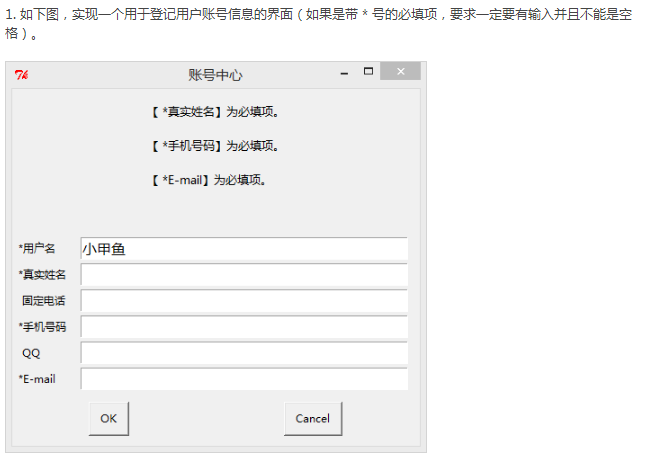
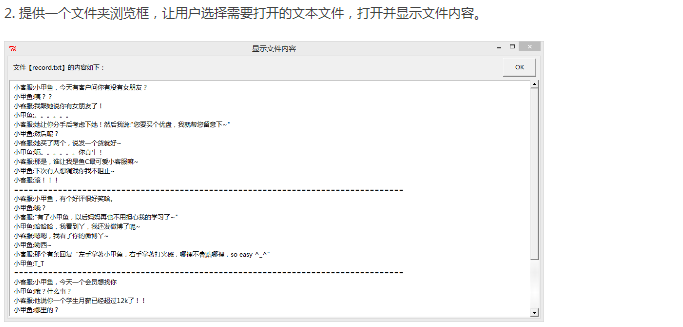
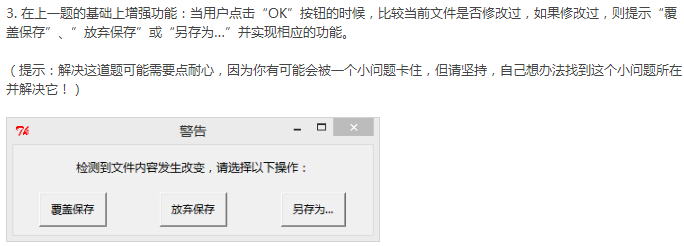
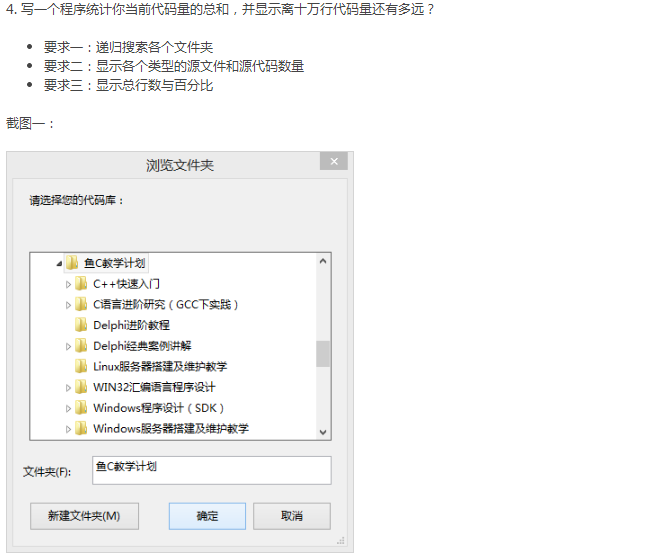

-
对象 = 属性 + 方法
class Turtle: # python中的类名约定以大写字母开头; 函数名以小写字母开头 """关于类的一个简单的例子""" # 属性 color = 'green' weight = 10 legs = 4 shell = True mouth = '大嘴' # 方法 def climb(self): print('我正很努力的往前爬。。。') def run(self): print('我正飞快的向前跑。。。') def bite(self): print('咬死你,咬死你。。。') def eat(self): print('有的吃,真满足!') def sleep(self): print('困了,睡了,晚安。Zzzz') # 类的实例化 turtle_01 = Turtle() turtle_01.sleep()
>>> from example_1 import * >>> >>> tt = Turtle() >>> Turtle() <example_1.Turtle object at 0x102adb370> >>> tt.climb() 我正很努力的往前爬。。。 >>> tt.bite() 咬死你,咬死你。。。 >>> tt.sleep() 困了,睡了,晚安。Zzzz
-
OO(object oriented) 面向对象的特征
-
封装
从表面上看对象封装了属性(变量)和方法(函数),封装更是一种信息隐蔽技术;
列表事实上就是一个对象,提供了若干种方法;但是我们不知道列表的方法是如何实现的,也不知道有多少变量,这就是封装
>>> list1 = [2, 1, 7, 5, 3] >>> list1.sort() >>> list1 [1, 2, 3, 5, 7] >>> list1.append(9) >>> list1 [1, 2, 3, 5, 7, 9] -
继承
子类共享父类的数据和方法的机制;
下面这个例子就是定义一个子类:MyList 继承父类list 的所有数据和方法
>>> class MyList(list): ... pass ... >>> list2 = MyList() >>> list2.append(3) >>> list2.append(5) >>> list2.append(7) >>> list2 [3, 5, 7] >>> list2.reverse() >>> list2 [7, 5, 3] -
多态
不同对象对同一方法响应不同的行动
下面这个例子,都调用同样一个名字为fun的方法,但是实现不一样
>>> class A: ... def fun(self): ... print('我是小A') ... >>> class B: ... def fun(self): ... print('我是小B') ... >>> a = A() >>> b = B() >>> >>> a.fun() 我是小A >>> b.fun() 我是小B
-
-
对象中的属性和方法,在编程中实际是什么?
变量和函数
-
类和对象是什么关系呢?
类和对象的关系就如同模具和用这个模具制作出的物品之间的关系。一个类为它的全部对象给出了一个统一的定义,而他的对象则是符合这种定义的一个实体,因此类和对象的关系就是抽象和具体的关系。对象是类的实例化。
-
如果我们定义了一个猫类,那你能想象出由“猫”类实例化的对象有哪些?
叮当猫,Tom猫,Hello Kitty```````
-
类的定义有些时候或许不那么“拟物”,有时候会抽象一些,例如我们定义一个矩形类,那你会为此添加哪些属性和方法呢?
属性:长,宽
方法:计算周长,面积
-
类的属性定义应该尽可能抽象还是尽可能具体?
抽象
-
请用一句话概括面向对象的几个特征?
封装:对外部隐藏对象的工作细节;
继承:子类自动共享父类之间数据和方法的机制;
多态:可以对不同类的对象调用相同的方法,产生不同的结果。
-
函数和方法有什么区别?
函数和方法几乎一样。主要有一点区别在于方法默认有一个self参数。
-
按照以下提示尝试定义一个Person类并生成类实例对象。
属性:姓名(默认姓名为“小甲鱼”)
方法:打印姓名
提示:方法中对属性的引用形式需加上self,如self.name
# 按照以下提示尝试定义一个Person类并生成类实例对象。 # 属性:姓名(默认姓名为“小甲鱼”) # 方法:打印姓名 # 提示:方法中对属性的引用形式需加上self,如self.name class Person: name = '小甲鱼' def printname(self): print(self.name) p1 = Person() p1.name = 'FishC' p1.printname()
-
按照以下提示尝试定义一个矩阵类并生成类实例对象。
属性:长和宽
方法:设置长和宽->setRect(self),获得长和宽->getRect(self),获得面积->getArea(self)
提示:方法中对属性的引用形式需加上self,如self.width
class Rectangle: def __init__(self): self.width = None self.length = None def set_rect(self): print('请输入矩形的长和宽...') self.length = float(input('长:')) self.width = float(input('宽:')) def get_rect(self): print('这个矩形的长是:{0:.2f} 宽是:{1:.2f}'.format(self.length, self.width)) def get_area(self): return self.length * self.width rect = Rectangle() rect.set_rect() rect.get_rect() rect.get_area()

-
python的self 相当于C/C++ 的指针
-
类是图纸,对象就是根据图纸建造出来的房子,self 相当于每个房子的门牌号
-
当一个对象的方法被调用的时候,对象会将自身作为第一个参数传给self参数,接收到self的时候,python就知道是哪个对象在调用这个方法了
>>> class Ball: ... def setName(self, name): ... self.name = name ... def kick(self): ... print('my name is %s, fuck, who kick me#@#' % self.name) ... >>> a = Ball() >>> a.setName('球A') >>> b = Ball() >>> b.setName('球B') >>> a.kick() my name is 球A, fuck, who kick me#@# >>> b.kick() my name is 球B, fuck, who kick me#@#
魔法方法都是被双下划线包围
-
__init__(self, param1, param2...)对象创建完后,在初始化实例对象时,该魔法方法会自动调用。可以根据需要自行改写该方法:
>>> class Ball: ... def __init__(self, name): ... self.name = name ... def kick(self): ... print('my name is %s, fuck, who kick me#@#' % self.name) ... >>> c = Ball('土豆') >>> c.kick() my name is 土豆, fuck, who kick me#@#
-
公有:
-
能直接被访问的属性和方法都是公有的。
-
默认对象的属性都是公有的
>>> class Person: ... name = 'FishC' ... >>> p = Person() >>> p.name 'FishC'
-
-
私有:
-
name mangling - 名字改编/名字重整
-
在python中定义私有变量只需要在变量名或者函数名前加上“__” 两个下划线,那么这个函数或者变量就成为私有的了
-
要访问私有变量,可以定义一个方法,从内部self 访问隐藏的变量并返回
>>> p = Person() >>> p.__name Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Person' object has no attribute '__name' >>> p.name Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Person' object has no attribute 'name' >>> >>> >>> class Person: ... __name = 'FishC' ... def getName(self): ... return self.__name ... >>> p = Person() >>> p.__name Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Person' object has no attribute '__name' >>> p.getName() 'FishC'
-
name mangling的背后原理是,python把双下划线的变量改成了
_类名__变量名,所以可以通过这种格式访问私有变量。所以python 类的私有变量其实是"伪私有">>> p._Person__name 'FishC'
-
-
以下代码体现了面向对象编程的什么特征?
>>> "FishC.com".count('o') 1 >>> [1, 1, 2, 3, 5, 8].count(1) 2 >>> (0, 2, 4, 8, 12, 18).count(1) 0
多态
-
当程序员不想把同一段代码写几次,他们发明了函数解决了这种情况。当程序员已经有了一个类,而又想建立一个非常相近的新类,他们会怎么做呢?
可以采用集成的方法。
class Newclass(Oldclass) -
self参数的作用是什么?
当一个对象的方法被调用的时候,对象会将自身作为第一个参数传给self参数,接收到self的时候,python就知道是哪个对象在调用这个方法了
-
如果我们不希望对象的属性或方法被外部直接引用,我们可以怎么做?
在变量名或者函数名前加上“__” 两个下划线,那么这个函数或者变量就成为私有的了
-
类在实例化后哪个方法会被自动调用?
__init__(self, param1, param2...)我们称之为魔法方法。你可以重写这个方法,为对象定制初始化方案 -
请解释下边代码错误的原因:
class MyClass: name = 'FishC' def myFun(self): print("Hello FishC!") >>> MyClass.name 'FishC' >>> MyClass.myFun() Traceback (most recent call last): File "<pyshell#6>", line 1, in <module> MyClass.myFun() TypeError: myFun() missing 1 required positional argument: 'self' >>>
首先你要明白类、类对象、实例对象是三个不同的名词 我们常说的类指的是类定义,由于“Python无处不对象”,所以当类定义完之后,自然就是类对象。在这个时候,你可以对类的属性(变量)进行直接访问(MyClass.name)。 一个类可以实例化出无数的对象(实例对象),Python 为了区分是哪个实例对象调用了方法,于是要求方法必须绑定(通过 self 参数)才能调用。而未实例化的类对象直接调用方法,因为缺少 self 参数,所以就会报错。
-
按照以下要求定义一个游乐园门票的类,并尝试计算2个成人+1个小孩平日票价。
- 平日票价100元
- 周末票价为平日的120%
- 儿童半票
class Ticket: def __init__(self, day, adult_count, child_count): self.day = day self.adult_count = adult_count self.child_count = child_count def price(self): if self.day == "WD": print('总票价为:{:.2f}'.format(100 * self.adult_count + 50 * self.child_count)) elif self.day == "WED": print('总票价为:{:.2f}'.format((100 * self.adult_count + 50 * self.child_count) * 1.2)) ticket1 = Ticket('WD', 2, 1) ticket1.price()
-
游戏编程:按以下要求定义一个乌龟类和鱼类并尝试编写游戏。(初学者不一定可以完整实现,但请务必先自己动手,你会从中学习到很多知识的^_^)
- 假设游戏场景为范围(x, y)为0<=x<=10,0<=y<=10
- 游戏生成1只乌龟和10条鱼
- 它们的移动方向均随机
- 乌龟的最大移动能力是2(Ta可以随机选择1还是2移动),鱼儿的最大移动能力是1
- 当移动到场景边缘,自动向反方向移动
- 乌龟初始化体力为100(上限)
- 乌龟每移动一次,体力消耗1
- 当乌龟和鱼坐标重叠,乌龟吃掉鱼,乌龟体力增加20
- 鱼暂不计算体力
- 当乌龟体力值为0(挂掉)或者鱼儿的数量为0游戏结束
# 游戏编程:按以下要求定义一个乌龟类和鱼类并尝试编写游戏。(初学者不一定可以完整实现,但请务必先自己动手,你会从中学习到很多知识的^_^) # # - 假设游戏场景为范围(x, y)为0<=x<=10,0<=y<=10 # - 游戏生成1只乌龟和10条鱼 # - 它们的移动方向均随机 # - 乌龟的最大移动能力是2(Ta可以随机选择1还是2移动),鱼儿的最大移动能力是1 # - 当移动到场景边缘,自动向反方向移动 # - 乌龟初始化体力为100(上限) # - 乌龟每移动一次,体力消耗1 # - 当乌龟和鱼坐标重叠,乌龟吃掉鱼,乌龟体力增加20 # - 鱼暂不计算体力 # - 当乌龟体力值为0(挂掉)或者鱼儿的数量为0, 游戏结束 import random as r class Turtle: def __init__(self, energy): self.init_position = None self.XY_list = ['X', 'Y'] self.direction_list = ['forward', 'backward'] self.message = '' self.move_param = None self.move_points = None self.energy = energy self.max_energy = 100 self.position = {self.XY_list[0]: r.randint(0, 10), self.XY_list[1]: r.randint(0, 10)} print('Turtle initial position is [{:d}, {:d}], energy: {:d}'. format(self.position['X'], self.position['Y'], self.energy)) def move(self, init_position): self.init_position = init_position self.move_param = (r.choice(self.XY_list), r.choice(self.direction_list)) self.move_points = r.randint(1, 2) if self.move_param[1] == 'forward': self.position[self.move_param[0]] = self.init_position[self.move_param[0]] + self.move_points if self.position[self.move_param[0]] > 10: self.position[self.move_param[0]] = 20 - self.position[self.move_param[0]] self.message = '触顶反弹' print('乌龟沿着{:s}轴 前进了{:d}步,{:s}!!!!!!now new position is [{:d}, {:d}], energy: {:d}' .format(self.move_param[0], self.move_points, self.message, self.position['X'], self.position['Y'], self.energy-1)) else: self.position[self.move_param[0]] = self.init_position[self.move_param[0]] - self.move_points if self.position[self.move_param[0]] < 0: self.position[self.move_param[0]] = 0 - self.position[self.move_param[0]] self.message = '触底反弹' print('乌龟沿着{:s}轴 后退了{:d}步,{:s}!!!!!!now new position is [{:d}, {:d}], energy: {:d}' .format(self.move_param[0], self.move_points, self.message, self.position['X'], self.position['Y'], self.energy-1)) # 乌龟每移动一步,能量减少1 self.energy -= 1 # print('Turtle moved once, now new position is [{:d}, {:d}, energy: {:d}]' # .format(self.position['X'], self.position['Y'], self.energy)) return self.position class Fish: def __init__(self): self.init_position = None self.XY_list = ['X', 'Y'] self.direction_list = ['forward', 'backward'] self.message = '' self.position = {self.XY_list[0]: r.randint(0, 10), self.XY_list[1]: r.randint(0, 10)} self.move_param = None self.move_points = 1 print('Fish initial position is [{:d}, {:d}]'.format(self.position['X'], self.position['Y'])) def move(self, init_position): self.init_position = init_position self.move_param = (r.choice(self.XY_list), r.choice(self.direction_list)) if self.move_param[1] == 'forward': self.position[self.move_param[0]] = self.init_position[self.move_param[0]] + self.move_points if self.position[self.move_param[0]] > 10: self.position[self.move_param[0]] = 20 - self.position[self.move_param[0]] self.message = '触顶反弹' print('小鱼沿着{:s}轴 前进了 {:d}步,{:s}!!!!!!now new position is [{:d}, {:d}]' .format(self.move_param[0], self.move_points, self.message, self.position['X'], self.position['Y'])) else: self.position[self.move_param[0]] = self.init_position[self.move_param[0]] - self.move_points if self.position[self.move_param[0]] < 0: self.position[self.move_param[0]] = 0 - self.position[self.move_param[0]] self.message = '触底反弹' print('小鱼沿着{:s}轴 后退了 {:d}步,{:s}!!!!!!now new position is [{:d}, {:d}]' .format(self.move_param[0], self.move_points, self.message, self.position['X'], self.position['Y'])) # print('Fish moved once, now new position is [{:d}, {:d}]'.format(self.position['X'], self.position['Y'])) return self.position print('------------------------------') print('初始化游戏!!!') print('生成1只乌龟和10条小鱼') print('------------------------------') # 生成1只乌龟和位置 turtle = Turtle(100) turtle_position = turtle.position # 鱼对象列表 fish = [] # key=鱼对象,value=鱼位置 fish_position = {} # 生成10条小鱼和位置,分别放在列表和字典中 createVar = locals() for i in range(10): createVar['fish'+str(i)] = Fish() fish.append(createVar['fish' + str(i)]) fish_position.setdefault(fish[i], fish[i].position) print(3 * '\n') print('------------------------------') print('游戏开始!!!') print('------------------------------') # 初始化鱼的数量 fish_count = len(fish_position) init_round = 1 while fish_count > 0 and turtle.energy > 0: print('Game on-going, Round: [{:}]'.format(init_round)) turtle_position = turtle.move(turtle_position) for each_fish in list(fish_position.keys()): fish_position[each_fish] = each_fish.move(fish_position[each_fish]) # 当乌龟和鱼坐标重叠, 乌龟吃掉鱼,乌龟体力增加20 if fish_position[each_fish] == turtle_position: fish_position.pop(each_fish) fish_count = len(fish_position) print('------------------------------') print('一条鱼在位置 [{:d}, {:d}] 被吃掉!还剩{:}'.format(turtle_position['X'], turtle_position['Y'], fish_count)) print('------------------------------') turtle.energy += 20 if turtle.energy >= turtle.max_energy: turtle.energy = turtle.max_energy init_round += 1 print('\n') if fish_count == 0: print('Game Over, Turtle win!!') elif turtle.energy == 0: print('Game Over, Fish win!!')
-
继承语法:
class DerivedClassName(BaseClassName):,被继承的类叫做父类,基类或超类,继承者叫做子类>>> class Parent: ... def hello(self): ... print('正在调用父类的方法。。') ... >>> class Child(Parent): ... pass ... >>> p = Parent() >>> p.hello() 正在调用父类的方法。。 >>> >>> c = Child() >>> c.hello() 正在调用父类的方法。
-
如果子类中定了和父类相同的属性或者方法,则会自动覆盖父类对应的属性或方法
>>> c = Child() >>> c.hello() 正在调用父类的方法。。 >>> class Child(Parent): ... def hello(self): ... print('正在调用子类的方法。。') ... >>> >>> c = Child() >>> c.hello() 正在调用子类的方法。
-
一个例子:
import random as r class Fish: def __init__(self): self.x = r.randint(0, 10) self.y = r.randint(0, 10) def move(self): self.x -= 1 print('我现在的位置是:', self.x, self.y) class GlodFish(Fish): pass class Salmon(Fish): pass class Shark(Fish): def __init__(self): self.hungary = True def eat(self): if self.hungary: print('我好饿,吃,吃,吃') self.hungary = False else: print('我已经吃饱啦!')
输出:
>>> goldfish = GoldFish() >>> goldfish.move() 我现在的位置是: 9 8 >>> goldfish.move() 我现在的位置是: 8 8 >>> goldfish.move() 我现在的位置是: 7 8 >>> goldfish.move() 我现在的位置是: 6 8 >>> >>> shark = Shark() >>> shark.eat() 我好饿,吃,吃,吃 >>> shark.eat() 我已经吃饱啦! >>> shark.move() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/Users/felix_yang/PycharmProjects/learningpython/38/example_01.py", line 10, in move self.x -= 1 AttributeError: 'Shark' object has no attribute 'x' >>>
上述例子中,shark 对象调用父类的move 方法时报错,是因为shark字类中重新定义了
__init__(self)方法,导致父类中的__init__(self)方法被覆盖,造成找不到x 属性要解决这个问题可以有如下两种方法:
-
调用未绑定的父类方法
class Shark(Fish): def __init__(self): # 调用未绑定的父类方法 Fish.__init__(self) self.hungary = True def eat(self): if self.hungary: print('我好饿,吃,吃,吃') self.hungary = False else: print('我已经吃饱啦!')
-
super()
推荐使用,super 函数会自动找到基类的方法,不用给定任何基类的名字,并且传入self 参数
class Shark(Fish): def __init__(self): # 使用super函数 super().__init__() self.hungary = True
-
输出
>>> shark = Shark() >>> shark.move() 我现在的位置是: 3 9
-
-
多重继承
同时继承多个基类的属性和方法:
class DerivedClassName(Base1, Base2, Base3)class Base1: def foo1(self): print('我代表基类 base1') class Base2: def foo2(self): print('我代表基类 base2') class Child(Base1, Base2): pass
>>> child = Child() >>> child.foo1 <bound method Base1.foo1 of <example_02.Child object at 0x10a5a98e0>> >>> child.foo1() 我代表基类 base1 >>> child.foo2() 我代表基类 base2
-
继承机制给程序猿带来最明显的好处是?
不需要写多个类包含相同的属性和方法
-
如果按以下方式重写魔法方法 __ init __,结果会怎样?
class MyClass: def __init__(self): return "I love FishC.com!"
实例化对象时会有如下错误,魔法方法应该返回none,不能return 其他的值
Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: __init__() should return None, not 'str' -
当子类定义了与相同名字的属性或方法时,Python 是否会自动删除父类的相关属性或方法?
不会,只会覆盖,当子类对象调用属性和方法时,会调用子类的属性和方法而已,而父类的属性和方法并未删除
-
假设已经有鸟类的定义,现在我要定义企鹅类继承于鸟类,但我们都知道企鹅是不会飞的,我们应该如何屏蔽父类(鸟类)中飞的方法?
重写一个相同的飞的方法,例如将函数体内容写 pass,这样调用 fly 方法就没有任何反应了。
-
super 函数有什么“超级”的地方?
super 函数超级之处在于你不需要明确给出任何基类的名字,它会自动帮您找出所有基类以及对应的方法。由于你不用给出基类的名字,这就意味着你如果需要改变了类继承关系,你只要改变 class 语句里的父类即可,而不必在大量代码中去修改所有被继承的方法
-
多重继承使用不当会导致重复调用(也叫钻石继承、菱形继承)的问题,请分析以下代码在实际编程中有可能导致什么问题?
class A(): def __init__(self): print("进入A…") print("离开A…") class B(A): def __init__(self): print("进入B…") A.__init__(self) print("离开B…") class C(A): def __init__(self): print("进入C…") A.__init__(self) print("离开C…") class D(B, C): def __init__(self): print("进入D…") B.__init__(self) C.__init__(self) print("离开D…")
子类D重复调用了基类A的魔法方法:init
-
如何解决上一题中出现的问题?
采用super() 方法
class A(): def __init__(self): print("进入A…") print("离开A…") class B(A): def __init__(self): print("进入B…") super().__init__() print("离开B…") class C(A): def __init__(self): print("进入C…") super().__init__() print("离开C…") class D(B, C): def __init__(self): print("进入D…") super().__init__() print("离开D…")
-
定义一个点(Point)类和直线(Line)类,使用 getLen 方法可以获得直线的长度。
提示:
- 设点 A(X1,Y1)、点 B(X2,Y2),则两点构成的直线长度 |AB| = √((x1-x2)2+(y1-y2)2)
- Python 中计算开根号可使用 math 模块中的 sqrt 函数
- 直线需有两点构成,因此初始化时需有两个点(Point)对象作为参数
import math as m class Point: def __init__(self, x, y): self.x = x self.y = y class Line(): def __init__(self, point_a, point_b): self.point_a = point_a self.point_b = point_b def getLen(self): return m.sqrt((self.point_a.x-self.point_b.x)**2 + (self.point_a.y-self.point_b.y)**2) point_a = Point(1, 3) point_b = Point(1, 5) line = Line(point_a, point_b) print(line.getLen())
-
展示一个你的作品:你已经掌握了 Python 大部分的基础知识,要开始学会自食其力了!请花一个星期做一个你能做出来的最好的作品(可以是游戏、应用软件、脚本),使用上你学过的任何东西(类,函数,字典,列表……)来改进你的程序。
-
组合: 把类的实例化放到一个新类里面,这样也就不需要继承了。解决了没有继承关系,也需要组合使用的问题
python的继承很有用,但容易把代码复杂化以及依赖隐含继承。因此,可以用组合代替。直接在类定义中把需要的类放进去实例化就可以了
那什么时候用组合,什么时候用继承呢?
- 组合:“有一个”,例如,水池里有一个乌龟,天上有一个鸟。
- 继承:“是一个”,例如,青瓜是瓜,女人是人,鲨鱼是鱼。
例子:现在要定一个类,叫水池,水池里要有乌龟和鱼
class Turtle: def __init__(self, x): self.number = x class Fish: def __init__(self, x): self.number = x class Pool: def __init__(self, x, y): self.turtle = Turtle(x) self.fish = Fish(y) def print_num(self): print('水池里总共由%d只乌龟,%d只鱼' %(self.turtle.number, self.fish.number)) p1 = Pool(1, 2) p1.print_num()
-
类,类对象和实例对象
-
当类定义完的时候,类定义就变成了类对象,可以直接通过"类名.属性"或者"类名.方法名()"引用属性和方法
>>> class C: ... count = 0 ... >>> a = C() >>> b = C() >>> c = C() >>> a.count 0 >>> b.count 0 >>> c.count 0 >>> c.count += 10 >>> c.count 10 >>> >>> >>> a.count 0 >>> b.count 0 >>> >>> C.count 0 >>> C.count += 100 >>> a.count 100 >>> b.count 100 >>> c.count 10
-
如果属性和名字和方法相同,属性会把方法覆盖掉
>>> class C: ... def x(self): #定义x方法 ... print("X-man") ... >>> c = C() >>> c.x() #调用C类的x方法 X-man >>> c.x = 1 #此时给实例对象c定义一个x属性并赋值1 >>> c.x #调用c的x属性是正常的 1 >>> c.x() #但此时再调用x方法就不可以了,因为重名的x属性覆盖了x方法 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'int' object is not callable >>> >>> a = C() >>> a.x <bound method C.x of <__main__.C object at 0x109d21a00>> >>> a.x() X-man >>> >>> c.x 1
-
-
什么是绑定?
python严格要求方法需要有实例才能被调用,这种限制就是绑定
>>> class B: ... def printB(self): ... print("BB") ... >>> B.printB() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: printB() missing 1 required positional argument: 'self' >>> >>> b = B() >>> b.printB() BB

-
什么是组合(组成)?
继承机制很有用,但容易把代码复杂化以及依赖隐含继承。因此,经常的时候,我们可以使用组合来代替。在Python里组合其实很简单,直接在类定义中把需要的类放进去实例化就可以了。
-
什么时候用组合,什么时候用继承?
根据实际应用场景确定。简单的说,组合用于“有一个”的场景中,继承用于“是一个”的场景中。例如,水池里有一个乌龟,天上有一个鸟,地上有一个小甲鱼,这些适合使用组合。青瓜是瓜,女人是人,鲨鱼是鱼,这些就应该使用继承啦。
-
类对象是在什么时候产生?
当你这个类 定义完的时候,类定义(类)就变成类对象,可以直接通过“类名.属性”或者“类名.方法名()”引用或使用相关的属性或方法。
-
如果对象的属性跟方法名字相同,会怎样?
如果对象的属性跟方法名相同,属性会覆盖方法。
-
请问以下类定义中哪些是类属性,哪些是实例属性?
class C: num = 0 def __init__(self): self.x = 4 self.y = 5 C.count = 6
num 和 count 是类属性(静态变量)->(类被删除了仍然存在),x 和 y 是实例属性->(实例变量删除后不存在)。大多数情况下,你应该考虑使用实例属性,而不是类属性(类属性通常仅用来跟踪与类相关的值)
-
请问以下代码中,bb 对象为什么调用 printBB() 方法失败?
class BB: def printBB(): print("no zuo no die") >>> bb = BB() >>> bb.printBB() Traceback (most recent call last): File "<pyshell#8>", line 1, in <module> bb.printBB() TypeError: printBB() takes 0 positional arguments but 1 was given
因为 Python 严格要求方法需要有实例才能被调用,这种限制其实就是 Python 所谓的绑定概念。 (任意一个实例对象调用函数都会传入自己作为参数 当然是python帮我们传入 我们不用写出来)所以 Python 会自动把 bb 对象作为第一个参数传入,所以才会出现 TypeError:“需要 0 个参数,但实际传入了 1 个参数“。
class BB: def printBB(self): print("no zuo no die") >>> bb = BB() >>> bb.printBB() no zuo no die
-
在类中定义一个变量,用来追踪有多少个实例被创建;
实例化一个对象,变量+1;销毁一个对象,变量-1
# 在类中定义一个变量,用来追踪有多少个实例被创建; # # 实例化一个对象,变量+1;销毁一个对象,变量-1 class InstanceCount: count = 0 def __init__(self): InstanceCount.count += 1 def __del__(self): InstanceCount.count -= 1 instance1 = InstanceCount() print('目前共计有%d个实例被创建' % InstanceCount.count) instance2 = InstanceCount() print('目前共计有%d个实例被创建' % InstanceCount.count) del instance1 print('目前共计有%d个实例被创建' % InstanceCount.count) del instance2 print('目前共计有%d个实例被创建' % InstanceCount.count)
-
定义一个栈(Stack)类,用于模拟一种具有后进先出(LIFO)特性的数据结构
至少需要有以下方法:
-
isEmpty():判断当前栈是否为空(返回True或Talse)
-
push():往栈的顶部压入一个数据项
-
pop():从栈顶弹出一个数据项(并在栈中删除)
-
top():显示当前栈顶的一个数据项
-
bottom():显示当前栈底的一个数据项
class Stack: def __init__(self): self.data = [] def isEmpty(self): if len(self.data) == 0: return True else: return False def push(self, x): self.data.append(x) def pop(self): self.data.pop() def top(self): try: print(self.data[-1]) except IndexError: print('no data in stack') def bottom(self): try: print(self.data[0]) except IndexError: print('no data in stack')
-

issubclass(cls, class_or_tuple)判断子类
>>> help(issubclass)
Help on built-in function issubclass in module builtins:
issubclass(cls, class_or_tuple, /)
Return whether 'cls' is a derived from another class or is the same class.
A tuple, as in
issubclass(x, (A, B, ...)), may be given as the target tocheck against. This is equivalent to ``issubclass(x, A) or issubclass(x, B)
or ...`` etc.
-
一个类被认为是自身的子类
-
classinfo可以是类对象组成的元组,只要class是其中任何一个候选类的子类,则返回True
>>> class A: ... pass ... >>> class B(A): ... pass ... >>> issubclass(B, A) True >>> issubclass(B, B) True >>> issubclass(B, object) # object 是所有类的默认基类 True >>> class C: ... pass ... >>> issubclass(B, C) False
-
isinstance(object, class_or_tuple)>>> help(isinstance)
Help on built-in function isinstance in module builtins:
isinstance(obj, class_or_tuple, /)
Return whether an object is an instance of a class or of a subclass thereof.
A tuple, as in
isinstance(x, (A, B, ...)), may be given as the target tocheck against. This is equivalent to ``isinstance(x, A) or isinstance(x, B)
or ...`` etc.
-
如果第一个参数不是对象,则永远返回False
-
如果第二个参数不是类或者由类对象组成的元组,会抛出一个TypeError异常
>>> b1 = B() >>> isinstance(b1, B) True >>> isinstance(b1, A) True >>> isinstance(b1, C) False >>> isinstance(b1, (A, B, C)) True
-
-
hasattr(object, name)- The arguments are an object and a string. The result is True if the string is the name of one of the object’s attributes, False if not. (This is implemented by calling getattr(object, name) and seeing whether it raises an AttributeError or not.)
- 作用就是测试一个对象里是否有指定的属性, 如果字符串是对象属性之一的命名,则返回True,否则False。
- 第一个参数(object)是对象,第二个参数(name)是属性名(属性的字符串名字)
>>> help(hasattr)
Help on built-in function hasattr in module builtins:
hasattr(obj, name, /)
Return whether the object has an attribute with the given name.
This is done by calling getattr(obj, name) and catching AttributeError.
-
Attractive = attribute: 属性
>>> class C: ... def __init__(self, x=0): ... self.x = x ... >>> >>> c1 = C() >>> hasattr(c1, 'x') # 注意此处x变量名需要加上引号变成字符串,不然会报错 True >>> hasattr(c1, x) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'x' is not defined
-
getattr(object, name[, default])- 返回对象指定的属性值,如果指定的属性不存在,则返回default(可选参数)的值;若没有设置default参数,则抛出ArttributeError异常。
>>> help(getattr)
Help on built-in function getattr in module builtins:
getattr(...)
getattr(object, name[, default]) -> value
Get a named attribute from an object; getattr(x, 'y') is equivalent to x.y.
When a default argument is given, it is returned when the attribute doesn't
exist; without it, an exception is raised in that case.
>>> getattr(c1, 'y') Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'C' object has no attribute 'y' >>> >>> getattr(c1, 'y', '你所访问的属性不存在') '你所访问的属性不存在'
-
setattr(obj, name, value)- 设置对象中指定属性的值,如果指定的属性不存在,则会新建属性并赋值
>>> help(setattr)
Help on built-in function setattr in module builtins:
setattr(obj, name, value, /)
Sets the named attribute on the given object to the specified value.
setattr(x, 'y', v) is equivalent to ``x.y = v''
>>> setattr(c1, 'y', 'Turtle') >>> getattr(c1, 'y', '你所访问的属性不存在') 'Turtle'
-
delattr(obj, name)- 用于删除对象中指定的属性,如果属性不存在,则会抛出AttributeError异常
>>> help(delattr)
Help on built-in function delattr in module builtins:
delattr(obj, name, /)
Deletes the named attribute from the given object.
delattr(x, 'y') is equivalent to ``del x.y''
>>> delattr(c1, 'y') >>> getattr(c1, 'y', '你所访问的属性不存在') '你所访问的属性不存在' >>> delattr(c1, 'y') Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: y
-
property(fget=None, fset=None, fdel=None, doc=None)- 作用是通过属性来设置属性
- 第一个参数是获得属性的方法名,第二个参数是设置属性的方法名,第三个参数是删除属性的方法名
property 的用处。当有需要对程序进行重构的时候,不需要告知用户每个方法的接口的修改,因为所有的属性都包括在x 里面提供给用户,用户看到的只是property x
>>> help(property) Help on class property in module builtins:
class property(object) | property(fget=None, fset=None, fdel=None, doc=None) |
| Property attribute. | | fget | function to be used for getting an attribute value | fset | function to be used for setting an attribute value | fdel | function to be used for del'ing an attribute | doc | docstring | | Typical use is to define a managed attribute x: | | class C(object): | def getx(self): return self._x | def setx(self, value): self._x = value | def delx(self): del self._x | x = property(getx, setx, delx, "I'm the 'x' property.") | | Decorators make defining new properties or modifying existing ones easy: | | class C(object): | @property | def x(self): | "I am the 'x' property." | return self._x | @x.setter | def x(self, value): | self._x = value | @x.deleter | def x(self): | del self._x | | Methods defined here: | | delete(self, instance, /) | Delete an attribute of instance. | | get(self, instance, owner, /) | Return an attribute of instance, which is of type owner. | | getattribute(self, name, /) | Return getattr(self, name). | | init(self, /, *args, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | set(self, instance, value, /) | Set an attribute of instance to value. | | deleter(...) | Descriptor to obtain a copy of the property with a different deleter. | | getter(...) | Descriptor to obtain a copy of the property with a different getter. | | setter(...) | Descriptor to obtain a copy of the property with a different setter. | | ---------------------------------------------------------------------- | Static methods defined here: | | new(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | ---------------------------------------------------------------------- | Data descriptors defined here: | | isabstractmethod | | fdel | | fget | | fsetclass C: def __init__(self, size=10): self.size = size def getSize(self): return self.size def setSize(self, value): self.size = value def delSize(self): del self.size x = property(getSize(), setSize(), delSize())
>>> c = C() >>> c.getSize() 10 >>> >>> c.x 10 >>> >>> c.x = 18 >>> c.x 18 >>> c.getSize() 18 >>> del c.x >>> c.x Traceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\Users\felix_yang\PycharmProjects\learningpython\40\example_property.py", line 6, in getSize return self.size AttributeError: 'C' object has no attribute 'size'
扩展知识:Python 函数修饰符(装饰器)的使用
1. 修饰符的来源
借用一个博客上的一段叙述:修饰符是一个很著名的设计模式,经常被用于有切面需求的场景,较为经典的有插入日志、性能测试、事务处理等。
修饰符是解决这类问题的绝佳设计,有了修饰符,我们就可以抽离出大量函数中与函数功能本身无关的雷同代码并继续重用。
概括的讲,修饰符的作用就是为已经存在的对象添加额外的功能。
如下:
import time
def timeslong(func):
start = time.time()
print("It's time starting ! ")
func()
print("It's time ending ! ")
end = time.time()
return "It's used : %s." % (end - start)
def myfunc():
print("Hello FishC.")
t = timeslong(myfunc)
print(t)实现结果:
It's time starting !
Hello FishC.
It's time ending !
It's used : 0.02497720718383789.
上面的程序中,定义了一个函数(timeslong()),对一个对象(代码中是 myfunc())的运行时间进行计算。
通常情况下,如果我们需要计算另外一个函数的运算时间,那么我们就需要修改 timeslong() 函数在调用时候的实参。
比如我需要统计 myfunc2 这个函数的运行时间,就需要调用 timeslong(myfunc2) 酱紫。
那么为了优化这种操作,Python 便提出了修饰符这个概念。
我们看下它是怎么实现的:
import time
def timeslong(func):
def call():
start = time.time()
print("It's time starting ! ")
func()
print("It's time ending ! ")
end = time.time()
return "It's used : %s." % (end - start)
return call
@timeslong
def myfunc():
print("Hello FishC.")
print(myfunc())实现的结果是一样的:
It's time starting !
Hello FishC.
It's time ending !
It's used : 0.022337913513183594.但是大家有没有发现,这一次我们不需要再去调用 timeslong() 函数了。
如果我有多个函数需要统计,那么使用起修饰符来就更优雅了:
import time
def timeslong(func):
def call():
start = time.time()
print("It's time starting ! ")
func()
print("It's time ending ! ")
end = time.time()
return "It's used : %s." % (end - start)
return call
@timeslong
def myfuna():
print("Hello World.")
@timeslong
def myfunb():
print("Hello Python.")
@timeslong
def myfunc():
print("Hello FishC.")
print(myfuna())
print("========================================")
print(myfunb())
print("========================================")
print(myfunc())实现结果:
It's time starting !
Hello World.
It's time ending !
It's used : 0.023639202117919922.
========================================
It's time starting !
Hello Python.
It's time ending !
It's used : 0.01770305633544922.
========================================
It's time starting !
Hello FishC.
It's time ending !
It's used : 0.014674186706542969.
通过修饰符主要达到的目标是使得整个代码看起来更加美观,仅此而已。
另外,我们还可以进一步“优雅”,
那就是把它封装成类:
import time
class timeslong(object):
def __init__(self, func):
self.func = func
def __call__(self):
start = time.time()
print("It's time starting ! ")
self.func()
print("It's time ending ! ")
end = time.time()
return "It's used : %s." % (end - start)
@timeslong
def myfuna():
print("Hello World.")
@timeslong
def myfunb():
print("Hello Python.")
@timeslong
def myfunc():
print("Hello FishC.")
print(myfuna())
print("========================================")
print(myfunb())
print("========================================")
print(myfunc())实现的结果是一样的:
It's time starting !
Hello World.
It's time ending !
It's used : 0.03470897674560547.
========================================
It's time starting !
Hello Python.
It's time ending !
It's used : 0.01266622543334961.
========================================
It's time starting !
Hello FishC.
It's time ending !
It's used : 0.014008522033691406.
其实呀,Python 也有内置的修饰符,它们分别是 staticmethod、classmethod 和 property,作用分别是把类中定义的实例方法变成静态方法、类方法和类属性。
简单地举个例子,如果我们将类这么写:
>>> class Hello(object):
... def print_hello(cls):
... print("Hello FishC")那么直接使用 类名.函数() 的方式调用就会报错:
>>> Hello.print_hello()
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
Hello.print_hello()
TypeError: print_hello() missing 1 required positional argument: 'cls'但是,只需要在类里面的函数名上方加上一个 @classmethod 修饰符:
>>> class Hello(object):
... @classmethod
... def print_hello(cls):
... print("Hello FishC")那么问题就迎刃而解了:
>>> Hello.print_hello()
Hello FishC因为给 @classmethod 修饰过后,print_hello() 就变成了类方法,可以直接通过 Hello.print_hello() 调用,而无需绑定实例对象了。
-
@staticmethod不需要表示自身对象的self和自身类的cls参数,就跟使用函数一样。
-
@classmethod也不需要self参数,但第一个参数需要是表示自身类的cls参数。
如果在@staticmethod中要调用到这个类的一些属性方法,只能直接类名.属性名或类名.方法名。 而@classmethod因为持有cls参数,可以来调用类的属性,类的方法,实例化对象等,避免硬编码。 下面上代码。
class A(object):
bar = 1
def foo(self):
print 'foo'
@staticmethod
def static_foo():
print 'static_foo'
print A.bar
@classmethod
def class_foo(cls):
print 'class_foo'
print cls.bar
cls().foo()
###执行
A.static_foo()
A.class_foo()
123456789101112131415161718123456789101112131415161718
输出
static_foo
1
class_foo
1
foo
property(fget=None, fset=None, fdel=None, doc=None)
俗话说条条大路通罗马,同样是完成一件事,Python 其实提供了好几个方式供你选择。
property() 是一个比较奇葩的BIF,它的作用把方法当作属性来访问,从而提供更加友好访问方式。
官方帮助文档代码:
class C:
def __init__(self):
self._x = None
def getx(self):
return self._x
def setx(self, value):
self._x = value
def delx(self):
del self._x
x = property(getx, setx, delx, "I'm the 'x' property.")property() 返回一个可以设置属性的属性,当然如何设置属性还是需要我们人为来写代码。第一个参数是获得属性的方法名(例子中是 getx),第二个参数是设置属性的方法名(例子中是 setx),第三个参数是删除属性的方法名(例子中是 delx)。
property() 有什么作用呢?举个例子,在上边的例题中,我们为用户提供 setx 方法名来设置 _x 属性,提供 getx 方法名来获取属性。但是有一天你心血来潮,突然想对程序进行大改,可能你需要把 setx 和 getx 修改为 set_x 和 get_x,那你不得不修改用户调用的接口,这样子的体验就非常不好。
有了 property() 所有问题就迎刃而解了,因为像上边一样,我们为用户访问 _x 属性只提供了 x 属性。无论我们内部怎么改动,只需要相应的修改 property() 的参数,用户仍然只需要去操作 x 属性即可,对他们来说没有任何影响。
使用属性修饰符创建描述符
使用属性修饰符创建描述符,也可以实现同样的功能(【扩展阅读】Python 函数修饰符(装饰器)的使用):
class C:
def __init__(self):
self._x = None
@property
def x(self):
"""I'm the 'x' property."""
return self._x
@x.setter
def x(self, value):
self._x = value
@x.deleter
def x(self):
del self._x注意:三个处理 _x 属性的方法名要相同(参数不同)
-
如何判断一个类是否为另一个类的子类?
issubclass(cls, class)
-
如何判断对象 a 是否为 类 A 的实例对象?
isinstance(a, A)
-
如何优雅地避免访问对象不存在的属性(不产生异常)?
使用
hasattr(object, name)查看是否有这个属性使用
getattr(object, name[, default]), 设置defaul message -
Python 的一些 BIF 很奇怪,但却十分有用。请问 property() 函数的作用是什么?
property() 函数允许编程人员轻松、有效地管理属性访问。
-
请补充以下代码,使程序可以正常运行:
class C: def __init__(self, size=10): self.size = size def getXSize(self): return self.size def setXSize(self, value): self.size = value def delXSize(self): del self.size # 此处应该补充一句代码,程序才能正常运行 >>> c.x 10 >>> c.x = 12 >>> c.x 12
答案:
x = property(getXSize, setXSize, delXSize) -
通过自学【扩展阅读】Python 函数修饰符(装饰器)的使用,使用修饰符修改以下代码。 代码A:
class CodeA: def foo(): print("调用静态方法 foo()") # 将 foo() 方法设置为静态方法 foo = staticmethod(foo)class CodeA: @staticmethod def foo(): print("调用静态方法 foo()") # 将 foo() 方法设置为静态方法 # foo = staticmethod(foo)代码B:
class CodeB: def foo(cls): print("调用类方法 foo()") # 将 foo() 方法设置为类方法 foo = classmethod(foo)class CodeB: @classmethod def foo(cls): print("调用类方法 foo()") # 将 foo() 方法设置为类方法 # foo = classmethod(foo) -
你真的理解了修饰符的用法吗?那请你写出以下代码没有用上修饰符的等同形式:
@something def f(): print("I love FishC.com!") f = something(f)返回的是函数的闭包
def something1(func): def call(): print('---start----') start = time.perf_counter() func() print('-------end------') end = time.perf_counter() print('used: %s ' % (end - start)) return call @something1 def f(): print("I love FishC.com!") f() -
通过自学【扩展阅读】property 的详细使用方法,将第 4 题的代码修改为“使用属性修饰符创建描述符”的方式实现。
class C: def __init__(self, size=10): self.size = size @property def x(self): """I'm the 'x' property.""" return self.size @x.setter def x(self, value): self.size = value @x.deleter def x(self): del self.size
-
魔法方法总是被双下划线所包围,例如:
__init__ -
魔法方法是面向对象的python的一切,如果你不知道魔法方法,说明你还没能意识到面向对象的python的强大
-
魔法方法的“魔力”体现在他们总是能够在适当的时候被调用
-
__init__(self[, ...])必须返回none,不要试图用init 返回任何值>>> class Rectangle: def __init__(self, x, y): self.x = x self.y = y def getPeri(self): return (self.x + self.y) * 2 def getArea(self): return self.x * self.y >>> rect = Rectangle(3, 4) >>> rect.getPeri() 14 >>> >>> rect.getArea() 12 >>> class A: def __init__(self): return "A fo init" >>> a = A() Traceback (most recent call last): File "<pyshell#31>", line 1, in <module> a = A() TypeError: __init__() should return None, not 'str'
-
__new__(cls[, ...])才是实例化对象第一个被调用的魔法方法,__init__(self[, ...])并不是第一个被调用的-
构造器,第一个参数是这个类
-
后面的参数都会原封不动的传递给init 方法
-
new 方法需要返回一个实例对象,通常是返回第一个参数 这个类的实例对象,当然也可以重写返回其他类的实例对象
-
一般极少重写new 方法。有一种情况需要重写new 方法,就是当继承一种不可变类型有需要修改的时候
>>> class CapStr(str): def __new__(cls, string): string = string.upper() return str.__new__(cls, string) >>> a = CapStr('I love FishC.com!') >>> a 'I LOVE FISHC.COM!'
-
-
__del__(self)-
析构器,当对象将要被销毁的时候,这个魔法方法就会被自动调用
-
注意:
del x不等于x.__del__(), 当对象没有任何引用时,会触发垃圾回收机制,这个时候才会调用del 魔法方法>>> class C: def __init__(self): print('我是__init__方法,我被调用了。。。') def __del__(self): print('我是__del__方法,我被调用了。。。') >>> >>> c1 = C() 我是__init__方法,我被调用了。。。 >>> >>> c2 = c1 # c2标签也指向实例 >>> c3 = c2 # c3标签也指向实例 >>> del c3 >>> del c2 >>> del c1 # 没有任何标签也指向实例,启动垃圾回收机制,这时候自动调用`__del__(self)` 我是__del__方法,我被调用了。。。
-
-
是哪个特征让我们一眼就能认出这货是魔法方法?
双下划线
-
什么时候我们需要在类中明确写出 __ init __ 方法?
当我们的实例对象需要有明确的初始化步骤的时候,你可以在 init 方法中部署初始化的代码。
-
请问下边代码存在什么问题?
class Test:
def __init__(self, x, y):
return x + yinit 方法只能返回none,不能是其他
-
请问 __ new __ 方法是负责什么任务?
new 方法主要任务是返回一个实例对象,通常是参数 cls 这个类的实例化对象,当然你也可以返回其他对象。
-
__ del __ 魔法方法什么时候会被自动调用?
如果说 __ init __ 和 __ new __ 方法是对象的构造器的话,那么 Python 也提供了一个析构器,叫做 __ del __ 方法。当对象将要被销毁的时候,这个方法就会被调用。 但一定要注意的是,并非 del x 就相当于自动调用 x.__ del (), del __ 方法是当垃圾回收机制回收这个对象的时候调用的。
-
小李做事常常丢三落四的,写代码也一样,常常打开了文件又忘记关闭。你能不能写一个 FileObject 类,给文件对象进行包装,从而确认在删除对象时文件能自动关闭?
# 小李做事常常丢三落四的,写代码也一样,常常打开了文件又忘记关闭。 # 你能不能写一个 FileObject 类,给文件对象进行包装,从而确认在删除对象时文件能自动关闭? class FileObject: '''给文件对象进行包装从而确认在删除时文件流关闭''' def __init__(self, filename='p_01.txt'): #读写模式打开一个文件 self.new_file = open(filename, 'r+') def __del__(self): self.new_file.close() del self.new_file
-
按照以下要求,定义一个类实现摄氏度到华氏度的转换(转换公式:华氏度 = 摄氏度*1.8+32)
要求:我们希望这个类尽量简练地实现功能,如下
>>> print(C2F(32)) 89.6
# 代码: class C2F(float): def __new__(cls, c_number): c_number = c_number * 1.8 + 32 return float.__new__(cls, c_number) print(C2F(32))
-
定义一个类继承于 int 类型,并实现一个特殊功能:当传入的参数是字符串的时候,返回该字符串中所有字符的 ASCII 码的和(使用 ord() 获得一个字符的 ASCII 码值)。
实现如下:
>>> print(Nint(123)) 123 >>> print(Nint(1.5)) 1 >>> print(Nint('A')) 65 >>> print(Nint('FishC')) 461
# 代码: class Nint(int): def __new__(cls, arg): if isinstance(arg, str): sum_number = 0 for each in arg: sum_number += ord(each) return int.__new__(cls, sum_number) else: return int.__new__(cls, arg) print(Nint(123)) print(Nint(1.5)) print(Nint('A')) print(Nint('FishC'))
-
python2.2 之后,将类和类型进行了统一,做法就是将如下的类型 内置函数 转换成 工厂函数
int(),float(), bool(), str(), list(),tuple(), type(), dict(), set(), frozenset()
-
工厂函数,就是能够产生类实例的内置函数
# 普通的内置函数 >> type(len) >> <class 'builtin_function_or_method'> >> type(open) >> <class 'builtin_function_or_method'> # 工厂函数,就是能够产生类实例的**内置函数** >> type(int) >> <class 'type'> >> type(list) >> <class 'type'>
-
工厂函数看上去有点像函数,实质上他们是类,当你调用它们时,实际上是生成了该类型的一个实例,就像工厂生产货物一样.
>>> type(int) <class 'type'> >>> type(list) <class 'type'> >>> >>> class C: ... pass ... >>> type(C) <class 'type'>
-
一个类定义完成就变成了类对象,所以工厂函数其实就是类对象
# 实例化int 对象,传入相应的参数 >>> a = int('123') >>> b = int('456') # 对象还可以计算 >>> a + b 579
-
python的魔法方法还可以自定义对象的数值处理,通过对魔法方法的重写,可以自定义任何对象间的算术运算
add(self, other) 定义加法的行为:+ sub(self, other) 定义减法的行为:- mul(self, other) 定义乘法的行为:* truediv(self, other) 定义真除法的行为:/ floordiv(self, other) 定义整数除法的行为:// mod(self, other) 定义取模算法的行为:% divmod(self, other) 定义当被 divmod() 调用时的行为,divmod(a, b)返回一个元组:(a//b, a%b) pow(self, other[, modulo]) 定义当被 power() 调用或 ** 运算时的行为 lshift(self, other) 定义按位左移位的行为:<< rshift(self, other) 定义按位右移位的行为:>> and(self, other) 定义按位与操作的行为:& xor(self, other) 定义按位异或操作的行为:^ or(self, other) 定义按位或操作的行为:| >>> class New_int(int): def __add__(self, other): return int.__sub__(self, other) def __sub__(self, other): return int.__add__(self, other) >>> a = New_int(3) >>> b = New_int(5) >>> a + b -2 >>> a - b 8
-
自 Python2.2 以后,对类和类型进行了统一,做法就是将 int()、float()、str()、list()、tuple() 这些 BIF 转换为工厂函数。请问所谓的工厂函数,其实是什么原理?
工厂函数,其实就是一个类对象。当你调用他们的时候,事实上就是创建一个相应的实例对象。
-
当实例对象进行加法操作时,会自动调用什么魔法方法?
对象 a 和 b 相加时(a + b),Python 会自动根据对象 a 的 add 魔法方法进行加法操作, add(self, other)
-
下边代码有问题吗?(运行起来似乎没出错的说_)
class Foo: def foo(self): self.foo = "I love FishC.com!" return self.foo >>> foo = Foo() >>> foo.foo() 'I love FishC.com!'
这绝对是一个温柔的陷阱,这种BUG比较难以排查,所以一定要注意:类的属性名和方法名绝对不能相同!如果代码这么写,就会有一个难以排查的BUG出现了:
class Foo: def __init__(self): self.foo = "I love FishC.com!" def foo(self): return self.foo >>> foo = Foo() >>> foo.foo() Traceback (most recent call last): File "<pyshell#21>", line 1, in <module> foo.foo() TypeError: 'str' object is not callable
-
写出下列算术运算符对应的魔法方法:
运算符 对应的魔法方法 + add(self, other) - sub(self, other) * mul(self, value) / truediv(self, other) // floordiv(self, other) % mod(self, other) divmod(a, b) divmod(self, other) ** pow(self, other[, modulo]) << lshift(self, other) >> rshift(self, other) & and(self, other) ^ xor(self, other) | or(self, other) -
以下代码说明 Python 支持什么风格?
def calc(a, b, c): return (a + b) * c >>> a = calc(1, 2, 3) >>> b = calc([1, 2, 3], [4, 5, 6], 2) >>> c = calc('love', 'FishC', 3) >>> print(a) 9 >>> print(b) [1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6] >>> print(c) loveFishCloveFishCloveFishC
说明 Python 支持鸭子类型(duck typing)风格。 鸭子风格
-
我们都知道在 Python 中,两个字符串相加会自动拼接字符串,但遗憾的是两个字符串相减却抛出异常。因此,现在我们要求定义一个 Nstr 类,支持字符串的相减操作:A – B,从 A 中去除所有 B 的子字符串。
# 我们都知道在 Python 中,两个字符串相加会自动拼接字符串, # 但遗憾的是两个字符串相减却抛出异常。 # 因此,现在我们要求定义一个 Nstr 类,支持字符串的相减操作:A – B,从 A 中去除所有 B 的子字符串。 class Nstr(str): def __sub__(self, other): return self.replace(other, '') s1 = Nstr('felixyangfelixyang') s2 = Nstr('felix') print(s1 - s2)
-
移位操作符是应用于二进制操作数的,现在需要你定义一个新的类 Nstr,也支持移位操作符的运算:
>>> a = Nstr('I love FishC.com!') >>> a << 3 'ove FishC.com!I l' >>> a >> 3 'om!I love FishC.c'
class Nstr(str): def __lshift__(self, other): return self[other:] + self[:other] def __rshift__(self, other): return self[-other:] + self[: -other] a = Nstr('I love FishC.com!') print(a << 3) print(a >> 3)
-
定义一个类 Nstr,当该类的实例对象间发生的加、减、乘、除运算时,将该对象的所有字符串的 ASCII 码之和进行计算:
>>> a = Nstr('FishC') >>> b = Nstr('love') >>> a + b 899 >>> a - b 23 >>> a * b 201918 >>> a / b 1.052511415525114 >>> a // b 1
class Nstr(int): def __new__(cls, arg): sum_number = 0 for each in arg: sum_number += ord(each) return int.__new__(cls, sum_number) a = Nstr('FishC') b = Nstr('love') print(a + b) print(a - b) print(a * b) print(a / b, a // b)
-
重写魔法方法,python 会根据你的意图进行计算
>>> class int(int): def __add__(self, other): return int.__sub__(self, other) >>> a = int('5') >>> a 5 >>> b = int('3') >>> a + b 2 >>>
-
反运算魔方方法,与算术运算符保持一一对应,不同之处就是反运算的魔法方法多了一个“r”
-
比如a+b, 这里加数是a,被加数是b,因此是a主动,反运算就是如果a对象的__add__()方法没有实现或者不支持相应的操作,那么Python就会调用b的__radd__()方法。
>>> class Nint(int): ... def __radd__(self, other): ... return int.__sub__(self, other) ... >>> a = Nint(5) >>> b = Nint(3) >>> a + b 8 >>> 1 + b 2
-
-
增量运算符
- a = a + b就是 a += b
-
一元操作符
- -a,取相反数的意思
- ~a,按位取反
-
对象相加(a + b),如果 a 对象有 add 方法,请问 b 对象的 radd 会被调用吗?
不会
-
Python 什么时候会调用到反运算的魔法方法?
例如 a + b, 如果a对象的__add__()方法没有实现或者不支持相应的操作,那么Python就会调用b的__radd__()方法。
-
请问如何在继承的类中调用基类的方法?
basecls.method()
或者使用super() 函数
class Derived(Base): def meth (self): super(Derived, self).meth()
-
如果我要继承的基类是动态的(有时候是 A,有时候是 B),我应该如何部署我的代码,以便基类可以随意改变。
你可以先为基类定义一个别名,在类定义的时候,使用别名代替你要继承的基类。如此,当你想要改变基类的时候,只需要修改给别名赋值的那个语句即可。顺便说一下,当你的资源是视情况而定的时候,这个小技巧很管用。
例子:
BaseAlias = BaseClass # 为基类取别名 class Derived(BaseAlias): def meth(self): BaseAlias.meth(self) # 通过别名访问基类 ...
-
尝试自己举一个例子说明如何使用类的静态属性。(一定要自己先动手再看答案哦_)
在类中直接定义的属性叫做静态属性(没有self.),需要调用的时候直接用
类名.属性名进行调用class C: number = 0 def show(self): return C.number c = C() print(c.show()) print(C.number)答案:
class A(object): count = 0 def __init__(self): A.count += 1 def getcount(self): return A.count a = A() a1 = A() b = A() print(a.getcount())
-
尝试自己举例说明如何使用类的静态方法,并指出使用类的静态方法有何要点和需要注意的地方?(一定要自己先动手再看答案哦_)
class C: @staticmethod def show(name='felix'): print(name) C.show('yang') C.show() c = C() c.show()答案:
class C: @staticmethod #该修饰符表示static()是静态方法 def static (arg1 , arg2 , arg3 ) : print (arg1 , arg2 , arg3 , arg1 + arg2 + arg3) def nostatic (self) : print ("I'm the fucking normal method") c1 = C() c2 = C() # 静态方法只在内存中生成一个,节省开销 print(c1.static is C.static) print(c1.nostatic is C.nostatic) print(c1.static) print(c2.static) print(C.static) # 普通方法每个实例对象都有独立的一个,开销较大 print(c1.nostatic) print(c2.nostatic) print(C.nostatic)
-
定义一个类,当实例化该类的时候,自动判断传入了多少个参数,并显示出来:
# 定义一个类,当实例化该类的时候,自动判断传入了多少个参数,并显示出来: class C: def __init__ (self, *args): # *arg表示不确定个数的参数 if not args: print("并没有传入参数") else: print("传入了%d个参数,分别是:" % len(args), end=' ') for each in args: print(each, end=' ') c = C() c = C(1, 2, 3)
-
定义一个单词(Word)类继承自字符串,重写比较操作符,当两个 Word 类对象进行比较时,根据单词的长度来进行比较大小。
class Word(str): def __lt__(self, other): return len(self) < len(other) def __gt__(self, other): return len(self) > len(other) def __eq__(self, other): return len(self) == len(other) def __ne__(self, other): return len(self) != len(other) def __le__(self, other): return len(self) <= len(other) def __ge__(self, other): return len(self) >= len(other) w1 = Word('123') w2 = Word('3456') print(w1 > w2) print(w1 < w2) print(w1 != w2) print(w1 == w2) print(w1 >= w2) print(w1 <= w2)
加分项:实例化时如果传入的是带空格的字符串,则去第一个空格前的单词作为参数
# 加分项:实例化时如果传入的是带空格的字符串,则去第一个空格前的单词作为参数 class Word(str): def __new__(cls, word): # 注意必须要使用__new__方法,因为str 是不可变类型 # 必须在创建的时候将他初始化 if ' ' in word: print('Value contains the spaces, truncating to first space.') word = word[: word.index(' ')] return str.__new__(cls, word) def __lt__(self, other): return len(self) < len(other) def __gt__(self, other): return len(self) > len(other) def __eq__(self, other): return len(self) == len(other) def __ne__(self, other): return len(self) != len(other) def __le__(self, other): return len(self) <= len(other) def __ge__(self, other): return len(self) >= len(other) w1 = Word('I love you') w2 = Word('felix') print(w1 > w2) print(w1 < w2) print(w1 != w2) print(w1 == w2) print(w1 >= w2) print(w1 <= w2)

-
前情提要
-
使用time模块的localtime方法获取时间
-
time.localtime返回structure_time的时间格式
gmtime(),localtime() 和 strptime() 以时间元组(struct_time)的形式返回。
索引值(Index) 属性(Attribute) 值(Values) 0 tm_year(年) (例如:2015) 1 tm_mon(月) 1 ~ 12 2 tm_mday(日) 1 ~ 31 3 tm_hour(时) 0 ~ 23 4 tm_min(分) 0 ~ 59 5 tm_sec(秒) 0 ~ 61(见下方注1) 6 tm_wday(星期几) 0 ~ 6(0 表示星期一) 7 tm_yday(一年中的第几天) 1 ~ 366 8 tm_isdst(是否为夏令时) 0, 1, -1(-1 代表夏令时) 注1:范围真的是 0 ~ 61(你没有看错哦^_^);60 代表闰秒,61 是基于历史原因保留。
-
表现你的类:
__str__和__repr__- __repr__改变的是所有的输出,而__str__改变的是print输出
- 同时包含了repr和str, print还是默认调用str,实例是调用repr
>>> class C: ... def __str__(self): ... return "felix is my name" ... >>> c1 = C() >>> c1 <__main__.C object at 0x100de3fa0> >>> print(c1) felix is my name >>> >>> >>> class C: ... def __repr__(self): ... return "this is for __repr__" ... >>> c2 = C() >>> c2 this is for __repr__ >>> print(c2) this is for __repr__
-
-
案例要求
- 定制一个计时器的类
- start和stop 方法代表启动计时器和停止计时器
- 假设计时器对象t1,print(t1) 和直接调用t1均显示结果
- 当计时器未启动或已经停止计时,调用stop方法会给予温馨的提示
- 两个计时器对象可以进行相加:t1+t2
- 只能使用提供的有限资源完成
-
我的程序:
# 案例 # # - 定制一个计时器的类 # - start和stop 方法代表启动计时器和停止计时器 # - 假设计时器对象t1,print(t1) 和直接调用t1均显示结果 # - 当计时器未启动或已经停止计时,调用stop方法会给予温馨的提示 # - 两个计时器对象可以进行相加:t1+t2 # - 只能使用提供的有限资源完成 import time import time as t class MyTimer: def __init__(self, status=0): self.start_time = None self.stop_time = None self.status = status def start(self): self.start_time = t.localtime() self.status = 1 def stop(self): if self.status == 0: print('计时器未启动') else: self.stop_time = t.localtime() self.status = 0 def __repr__(self): self.interval_sec = self.stop_time.tm_sec - self.start_time.tm_sec self.interval_min = self.stop_time.tm_min - self.start_time.tm_min self.interval_hour = self.stop_time.tm_hour - self.start_time.tm_hour self.interval = (self.interval_hour * 60 + self.interval_min) * 60 + self.interval_sec return str(self.interval) def __str__(self): self.interval_sec = self.stop_time.tm_sec - self.start_time.tm_sec self.interval_min = self.stop_time.tm_min - self.start_time.tm_min self.interval_hour = self.stop_time.tm_hour - self.start_time.tm_hour self.interval = (self.interval_hour * 60 + self.interval_min) * 60 + self.interval_sec return str(self.interval) def __add__(self, other): return float(self.__repr__()) + float(other.__repr__())
-
答案程序
-
初始程序
import time as t class Mytimer(): def __init__(self): #定义一个列表存放时间的单位,以便程序运行后输出的结果直接是带单位的结果:如:总共运行了:3秒 self.unit = ['年','月','天','小时','分钟','秒'] self.prompt = '未开始计时!' self.lasted = [] #self.start = 0 self.begin = 0 #self.stop = 0 self.end = 0 #这里特别需要注意,方法名和属性名不能定义成同一个名字,否则属性会覆盖方法 #实现直接调用对象来输出内容 def __str__(self): return self.prompt #__str__ 赋值给 __repr__ __repr__ = __str__ #两个对象相加 def __add__(self,other): prompt = "总共运行了" result = [] for index in range(6): result.append(self.lasted[index]+other.lasted[index]) if result[index]:#如果result是空的话执行 prompt += (str(result[index])+self.unit[index]) return prompt #开始计时 def start(self):#self表示对象的引用 self.begin = t.localtime() self.prompt = '提示:请先调用stop()停止计时' print('计时开始...') #停止计时 def stop(self): if not self.begin: print("提示:请先调用start()进行计时!") else: self.end = t.localtime() #结束计时时并进行计算,即对象.内部方法 self._clac() print('计时结束!') #内部方法(_方法名),计算运行时间 def _clac(self): #计算的结果放在一个列表里面 self.lasted = [] #定义一个提示的变量 self.prompt = '总共运行了' #依次遍历localtime的索引 for index in range(6): #用结束时间减去开始时间得到运行的时间,并把结果放到lasted[]列表内 self.lasted.append(self.end[index]-self.begin[index]) #把每一次计算的结果进行一次追加 if self.lasted[index]: #当lasted为0时就不会执行if内的语句,而是执行下一轮的循环 self.prompt += str(self.lasted[index])+self.unit[index] #运行时间+单位 #为下一轮计时初始化变量 self.begin = 0 self.end = 0 执行结果: >>> t1 = Mytimer() >>> t1.start() 计时开始... >>> t1.stop() 计时结束! >>> t1 总共运行了9秒 >>> t2 = Mytimer() >>> t2.start() 计时开始... >>> t2.stop() 计时结束! >>> t2 总共运行了5秒 >>> t1+t2 '总共运行了14秒' >>>
-
-
按照课堂中的程序,如果开始计时的时间为(2022年2月22日16:30:30),停止时间是(2025年1月23日15:30:30),那按照我们用停止时间减去开始时间的计算方式就会出现负数,你应该对此做一些转换
#!/usr/bin/python # -*- coding:utf-8 -*- import time as t class MyTimer: def __init__(self): self.unit = ['年', '月', '天', '小时', '分钟', '秒'] self.borrow = [1, 12, 31, 24, 60, 60] self.prompt = "未开始计时!" self.lasted = [] self.begin = 0 self.end = 0 # 开始计时 def start(self): self.begin = t.localtime() self.prompt = "提示:请先调用stop()结束计时!" print("计时开始……") # 停止计时 def stop(self): if not self.begin: print("提示:请先调用start()开始计时!") else: self.end = t.localtime() self._calc() print("计时结束!") # 内部方法,计算运行时间 def _calc(self): self.lasted = [] self.prompt = "总共运行了" for index in range(6): temp = self.end[index] - self.begin[index] # 低位不够减,需要向高位借位 if temp < 0: # 测试高位是否有得借,没得借的话再向高位借…… i = 1 while self.lasted[index-i] < 1: self.lasted[index-i] += self.borrow[index-i] - 1 self.lasted[index-i-1] -= 1 i += 1 self.lasted.append(self.borrow[index] + temp) self.lasted[index-1] -= 1 else: self.lasted.append(temp) # 由于高位随时会被借位,所以打印要放在最后 for index in range(6): if self.lasted[index]: self.prompt += str(self.lasted[index]) + self.unit[index] # 为下一轮计算初始化变量 self.begin = 0 self.end = 0 print(self.prompt) # 调用实例直接显示结果 def __str__(self): return self.prompt __repr__ = __str__ # 计算两次计时器对象之和 def __add__(self, other): prompt = "总共运行了" result = [] for index in range(6): result.append(self.lasted[index] + other.lasted[index]) if result[index]: prompt += (str(result[index]) + self.unit[index]) return prompt t1 = MyTimer() t2 = MyTimer() t1.start() t.sleep(65) t1.stop() t2.start() t.sleep(15) t2.stop() print(t1 + t2)
-
相信大家已经意识到不对劲了:为毛一个月一定要31天?不知道又可能也是30天或者29天吗?(上一题我们的答案是假设一个月31天)
没错,如果要正确得到月份的天数,我们还需要考虑是否闰年,还有每月的最大天数,所以太麻烦了......如果我们不及时纠正,我们会在错误的道理上越走越远.......
所以,这一次,小甲鱼提出来了更加优秀的解决方案:用time模块的perf_counter()和process_time()来计算,其中perf_counter()返回计时器的精准时间(系统的运行时间);process_time()返回当前进程执行CPU的时间总和
题目:改进我们课堂中的例子,这次试用perf_counter()和process_time()作为计时器。另外增加一个set_timer()方法,用于设置默认计时器(默认是perf_counter(),可以通过此方法修改为process_time()
# 用time模块的perf_counter()和process_time()计算,其中perf_counter()返回计时器的精准时间(系统的运行时间); # process_time()返回当前进程执行CPU的时间总和。 # 题目:改进我们课堂中的例子,这次使用perf_counter()和process_time()作为计时器, # 另外新增一个set_time()方法,用于设置默认计时器(默认是perf_counter(),可以通过此方法修改为process_time() ) #!/usr/bin/python # -*- coding:utf-8 -*- import time as t class MyTimer: def __init__(self): self.prompt = "未开始计时" self.lasted = 0.0 self.begin = 0 self.end = 0 self.default_timer = t.perf_counter def __str__(self): return self.prompt __repr__ = __str__ def __add__(self, other): result = self.lasted + other.lasted prompt = "总共运行了%0.2f秒" % result return prompt def start(self): self.begin = self.default_timer() self.prompt = "提示:请先调用stop()停止计时!" print("计时开始!") def stop(self): if not self.begin: print("提示:请先调用start()运行计时!") else: self.end = self.default_timer() self._calc() print("计时结束") def _calc(self): self.lasted = self.end - self.begin self.prompt = "总共运行了%0.2f秒" % self.lasted print(self.prompt) self.begin = 0 self.end = 0 def set_timer(self, timer): if timer == 'process_time': self.default_timer = t.process_time elif timer == 'perf_counter': self.default_timer = t.perf_counter else: print("输入无效") t1 = MyTimer() t1.set_timer('perf_counter') t1.start() t.sleep(5.2) t1.stop() t2 = MyTimer() t2.set_timer('perf_counter') t2.start() t.sleep(5.2) t2.stop() print(t1 + t2)
-
既然咱都做到这一步,那不如深入一下,再次改进我们的代码,让它能够统计一个函数运行若干次的时间
要求一:函数调用的次数可以设置(默认是1000000次)
要求二:新增一个 timeing()方法,用于启动计时器
# 既然咱都做到这一步,那不如深入一下,再次改进我们的代码,让它能够统计一个函数运行若干次的时间 # # 要求一:函数调用的次数可以设置(默认是1000000次) # # 要求二:新增一个 timeing()方法,用于启动计时器 # !/usr/bin/python # -*- coding:utf-8 -*- import time as t class MyTimer: def __init__(self, func, number=1000000): self.prompt = "未开始计时" self.lasted = 0.0 self.begin = 0 self.end = 0 self.default_timer = t.perf_counter self.number = number self.func = func def __str__(self): return self.prompt __repr__ = __str__ def __add__(self, other): result = self.lasted + other.lasted prompt = "总共运行了%0.2f秒" % result return prompt # 内置方法,计算运行时间 def timing(self): self.begin = self.default_timer() for i in range(self.number): self.func() self.end = self.default_timer() self.lasted = self.end - self.begin self.prompt = "总共运行了 %0.2f 秒" % self.lasted def set_timer(self, timer): if timer == 'process_time': self.default_timer = t.process_time elif timer == 'perf_counter': self.default_timer = t.perf_counter else: print("输入无效") def test(): text = "I love FishC.com!" char = 'o' if char in text: pass t1 = MyTimer(test) t1.timing() print(t1) t2 = MyTimer(test, 10000000) t2.timing() print(t2) t3 = MyTimer(test, 100000000) t3.timing() print(t3)
-
回忆复习
通常在一段程序的前后都用上time.time(),然后进行相减就可以得到一段程序的运行时间,不过python提供了更强大的计时库:timeit
#导入timeit.timeit from timeit import timeit #看执行1000000次x=1的时间: timeit('x=1') #看x=1的执行时间,执行1次(number可以省略,默认值为1000000): timeit('x=1', number=1) #看一个列表生成器的执行时间,执行1次: timeit('[i for i in range(10000)]', number=1) #看一个列表生成器的执行时间,执行10000次: timeit('[i for i in range(100) if i%2==0]', number=10000)
测试一个函数的执行时间:
from timeit import timeit def func(): s = 0 for i in range(1000): s += i print(s) # timeit(函数名_字符串,运行环境_字符串,number=运行次数) t = timeit('func()', 'from __main__ import func', number=1000) print(t)
此程序测试函数运行1000次的执行时间。
-
前情提要
-
访问属性的方法有2种
-
通过
.的方式,实例.属性访问>>> class C: ... def __init__(self): ... self.name = 'x-man' ... >>> c = C() >>> c.name 'x-man'
-
通过BIF,geattr() 优雅的访问
>>> getattr(c, 'name', '木有这个属性') 'x-man' >>> >>> getattr(c, 'size', '木有这个属性') '木有这个属性'
-
-
可以通过设置property 属性,绑定操作其他属性
>>> class C: ... def __init__(self, size): ... self.size = size ... def getSize(self): ... return self.size ... def setSize(self,value): ... self.size = value ... def delSize(self): ... del self.size ... x = property(getSize, setSize, delSize) >>> c = C(10) >>> c.size 10 >>> c.x = 1 >>> c.size 1 >>> del c.x >>> c.size Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'C' object has no attribute 'size' >>> c.x Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 5, in getSize AttributeError: 'C' object has no attribute 'size' >>> c.x = 1 >>> c.size 1 >>> c.x 1
-
-
魔法方法 - 操作属性
通过重写这几个魔法方法可以控制对属性的访问
__getattr__(self, name)定义当用户试图获取一个不存在的属性时的行为 __getattribute__(self, name)定义当该类的属性被访问时的行为 __setattr__(self, name)定义当一个属性被设置时的行为 __delattr__(self, name)定义当一个属性被删除时的行为 # 4个魔法方法操作属性 class C: # 定义当该类的属性被访问时的行为 def __getattribute__(self, name): print('getattribute') # 仅仅测试用途,通过super函数继承默认基类的同样魔法方法,不改变魔法方法本身 return super().__getattribute__(name) # 当用户试图获取一个不存在的属性的行为,如果属性存在就不会调用了; 默认行为是会报错 def __getattr__(self, name): print('getattr') # 定义当一个属性被设置时的行为 def __setattr__(self, name, value): print('setattr') # 仅仅测试用途,通过super函数继承默认基类的同样魔法方法,不改变魔法方法本身 super().__setattr__(name, value) # 定义当一个属性被删除时的行为 def __delattr__(self, name): print('delattr') # 仅仅测试用途,通过super函数继承默认基类的同样魔法方法,不改变魔法方法本身 super().__delattr__(name) c = C() c.size c.size = 1 c.size del c.size
output
getattribute # c.size 访问属性时,调用getattribute getattr # c.size 不存在,触发调用getattr setattr # c.size = 1, 触发调用setattr getattribute # c.size 访问属性时,调用getattribute;由于c.size 存在,不会触发调用getattr delattr # del c.size 删除属性时,调用delattr
-
课堂练习
-
写一个矩形类,默认有宽和高两个属性
-
如果为一个叫square的属性赋值,那么说明是一个正方形,值就是正方形的边长,此时宽和高都应该等于边长
# 课堂练习 # # - 写一个矩形类,默认有宽和高两个属性 # - 如果为一个叫square的属性赋值,那么说明是一个正方形,值就是正方形的边长,此时宽和高都应该等于边长 class Rectangle: def __init__(self): self.width = 5 self.height = 8 def __setattr__(self, name, value): if name == 'square': print('it is a square!!') self.width = value self.height = value # 继承默认基类的方法,给属性赋值;如果不写,会出现死循环 super().__setattr__(name, value) # 还可以通过默认属性字典的方式,直接给属性赋值 # self.__dict__[name] = value rec = Rectangle() print(rec.width, rec.height) rec.square = 10 print(rec.square, rec.width, rec.height)
-
-
请问以下代码的作用是什么?这样写正确吗?(如果不正确,请改正)
def __setattr__(self, name, value): self.name = value + 1
代码的作用是自动为属性的赋值加1,代码不正确,因为会有死循环,
self.name = value + 1本身也是赋值语句,需要不断调用__setattr__有2种方法改正:
-
使用super()函数继承默认object 基类
def __setattr__(self, name, value): super().__setattr__(name, value+1)
-
采用对默认属性字典直接赋值的方法
def __setattr__(self, name, value): # self.name = value + 1 self.__dict__[name] = value + 1
-
-
自定义该类的属性被访问的行为,你应该重写哪个魔法方法?
__getattribute__() -
在不上机验证的情况下,你能推断以下代码分别会显示什么吗?
>>> class C: def __getattr__(self, name): print(1) def __getattribute__(self, name): print(2) def __setattr__(self, name, value): print(3) def __delattr__(self, name): print(4) >>> c = C() >>> c.x = 1 # 位置一,请问这里会显示什么? >>> print(c.x) # 位置二,请问这里会显示什么?
位置一:
3
位置二:
2
None
因为 x 是属于实例对象 c 的属性,所以 c.x 是访问一个存在的属性,因此会访问 getattribute() 魔法方法,但我们重写了这个方法,使得它不能按照正常的逻辑返回属性值,而是打印一个 2 代替,由于我们没有写返回值,所以紧接着返回 None 并被 print() 打印出来。
-
在不上机验证的情况下,你能推断以下代码分别会显示什么吗?
>>> class C: def __getattr__(self, name): print(1) return super().__getattr__(name) def __getattribute__(self, name): print(2) return super().__getattribute__(name) def __setattr__(self, name, value): print(3) super().__setattr__(name, value) def __delattr__(self, name): print(4) super().__delattr__(name) >>> c = C() >>> c.x
>>> c = C() >>> c.x 2 1 Traceback (most recent call last): File "<pyshell#31>", line 1, in <module> c.x File "<pyshell#29>", line 4, in __getattr__ return super().__getattr__(name) AttributeError: 'super' object has no attribute '__getattr__'为什么会如此显示呢?我们来分析下:首先 c.x 会先调用 getattribute() 魔法方法,打印 2;然后调用 super().getattribute(),找不到属性名 x,因此会紧接着调用 getattr() ,于是打印 1;但是你猜到了开头没猜到结局……当你希望最后以 super().getattr() 终了的时候,Python 竟然告诉你 AttributeError,super 对象木有 getattr !!
>>> dir(super) ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__get__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__self__', '__self_class__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__thisclass__'] -
请指出以下代码的问题所在:
class Counter: def __init__(self): self.counter = 0 def __setattr__(self, name, value): self.counter += 1 super().__setattr__(name, value) def __delattr__(self, name): self.counter -= 1 super().__delattr__(name)
以下注释: class Counter: def __init__(self): self.counter = 0 # 这里会触发 __setattr__ 调用 def __setattr__(self, name, value): self.counter += 1 “””既然需要 __setattr__ 调用后才能真正设置 self.counter 的值,所以这时候 self.counter 还没有定义,所以没法 += 1,错误的根源。””” super().__setattr__(name, value) def __delattr__(self, name): self.counter -= 1 super().__delattr__(name)
-
按要求重写魔法方法:当访问一个不存在的属性时,不报错且提示“该属性不存在!”
class C: def __getattr__(self, item): print('该属性不存在!')
-
编写 Demo 类,使得下边代码可以正常执行:
>>> demo = Demo() >>> demo.x 'FishC' >>> demo.x = "X-man" >>> demo.x 'X-man'
class Demo: def __getattr__(self, name): self.name = 'FishC' return self.name demo = Demo() demo.x demo.x = "X-man" demo.x
-
修改上边【测试题】第 4 题,使之可以正常运行:编写一个 Counter 类,用于实时检测对象有多少个属性。、
程序实现如下:
>>> c = Counter() >>> c.x = 1 >>> c.counter 1 >>> c.y = 1 >>> c.z = 1 >>> c.counter 3 >>> del c.x >>> c.counter 2
方法一:此方法有一个bug,其实不是检测的某个对象的属性数量,而是检测整个类的所有对象的属性数量。。。
class Counter: counter = 0 def __setattr__(self, name, value): Counter.counter += 1 super().__setattr__(name, value) def __delattr__(self, name): Counter.counter -= 1 super().__delattr__(name) c = Counter() c.x = 1 print(c.counter) c.y = 1 c.z = 1 print(c.counter) del c.x print(c.counter)
方法二:方法二满足题目要求
class Counter: def __init__(self): super().__setattr__('counter', 0) def __setattr__(self, name, value): super().__setattr__('counter', self.counter + 1) super().__setattr__(name, value) def __delattr__(self, name): super().__setattr__('counter', self.counter - 1) super().__delattr__(name)
-
描述符就是将某种特殊类型的类的实例指派给另一个类的属性。大家对于这个定义可能还不是很理解,等会会举例说明。首先,什么是特殊类型呢?特殊类型的要求是至少要实现以下三个方法其中一个或全部实现。
__get(self, instance, owner)__用于访问属性,它返回属性的值__set(self, instance, value)__将在属性分配操作中调用,不返回任何内容__delete(self, instance)__控制删除操作,不返回任何内容
-
一个例子
>>> class MyDescriptor: ... def __get__(self, instance, owner): ... print('getting...', self, instance, owner) ... def __set__(self, instance, value): ... print('setting...', self, instance, value) ... def __delete__(self, instance): ... print('deleting...', self, instance) ... >>> class Test: ... x = MyDescriptor() ... # 先来写一个描述符 MyDescriptor,并且把所有方法的参数给打印出来。 # 再来一个真正的Test类来测试一下,就给一个属性 x ,把 MyDescriptor() 的实例指派给Test类的属性 x。我们就说 # MyDescriptor 类就是 x 的描述符。(是不是一下子感觉到了 property 的影子)。 # 我们下面实例化 Test 类,对 x 属性进行各种操作,看看描述符类 MyDescriptor 会有怎样的响应。 >>> test = Test() >>> test.x getting... <__main__.MyDescriptor object at 0x104b398e0> <__main__.Test object at 0x1044d79a0> <class '__main__.Test'> >>> >>> test <__main__.Test object at 0x1044d79a0> >>> Test <class '__main__.Test'> >>> test.x = 'x-man' setting... <__main__.MyDescriptor object at 0x104b398e0> <__main__.Test object at 0x1044d79a0> x-man >>> del test.x deleting... <__main__.MyDescriptor object at 0x104b398e0> <__main__.Test object at 0x1044d79a0> >>>
-
我们尝试直接打印 test.x ,我们看到会调用描述符的 get,并且参数的意义也很明确, self 是描述符类本身的实例,instance 参数是 它的拥有者 Test 的实例 test,我们直接打印 test,就和 instance 的内容一样,然后 owner 就是它的拥有者 Test 类本身,我们直接打印 Test,就和 owner 的内容一样。 然后赋值(test.x = “x-man”)的时候,就会调用描述符的 set,删除(del test.x)的时候也是一样,调用__delete__。
-
property 就是一个描述符类
-
自定义一个 property(MyProperty),来实现property的所有功能
-
我们这里定义的MyProperty只是把 property的功能进行照搬,大家可以加入自己的创意
>>> class MyProperty: def __init__(self, fget = None, fset = None, fdel = None): self.fget = fget self.fset = fset self.fdel = fdel def __get__(self, instance, owner): return self.fget(instance) def __set__(self, instance, value): self.fset(instance, value) def __delete__(self, instance): self.fdel(instance) >>> class C: def __init__(self): self._x = None def getx(self): return self._x def setx(self, value): self._x = value def delx(self): del self._x x = MyProperty(getx, setx, delx) >>> c = C() >>> c.x = "x-man" >>> c._x 'x-man' >>> del c.x >>> c._x Traceback (most recent call last): File "<pyshell#62>", line 1, in <module> c._x AttributeError: 'C' object has no attribute '_x'
-
-
第二个例子:课堂练习
-
先定义一个温度类,然后定义两个描述符类用于描述摄氏度和华氏度两个属性。
-
要求两个属性会自动进行转换,也就是说你可以给摄氏度这个属性赋值,然后打印的华氏度属性是自动转换后的结果。 公式:摄氏度 * 1.8 + 32 = 华氏度
class Celsius: def __init__(self, value = 26.0): self.value = float(value) def __get__(self, instance, owner): return self.value def __set__(self, instance, value): self.value = float(value) class Fahrenheit: def __get__(self, instance, owner): return instance.cel * 1.8 +32 def __set__(self, instance, value): instance.cel = (float(value) - 32) / 1.8 class Temperature: cel = Celsius() fah = Fahrenheit()
-
-
请尽量用自己的语言来解释什么是描述符(不要搜索来的答案,用自己的话解释)?
描述符其实就是个特殊的类,实例化之后赋值给目标类的属性, 描述符类有3个特殊的魔法函数,自动实现 (a). get 目标类实例的属性值,(b). set 目标类实例的属性值和 (c). 删除目标类实例的属性;
答:有时候,某个应用程序可能会有一个相当微妙的需求,需要你设计一些更为复杂的操作来响应(例如每当属性被访问时,你也许想创建一个日志记录)。最好的解决方案就是编写一个用于执行这些“更复杂的操作”的特殊函数,然后指定它在属性被访问时运行。那么一个具有这种函数的对象被称之为描述符。 往再简单了说,描述符就是一个类,一个至少实现 get()、set() 或 delete() 三个特殊方法中的任意一个的类。
-
描述符类中,分别通过哪些魔法方法来实现对属性的 get、set 和 delete 操作的?
__get(self, instance, owner)__用于访问属性,它返回属性的值__set(self, instance, value)__将在属性分配操作中调用,不返回任何内容__delete(self, instance)__控制删除操作,不返回任何内容
-
请问以下代码,分别调用 test.a 和 test.x,哪个会打印“getting…”?
>>> class MyDes: def __get__(self, instance, owner): print("getting...") >>> class Test: a = MyDes() x = a >>> test = Test()
test.a
test.x
test.a 会调用MyDes的 __get__方法 由于x=a x相当于a的复制品,当然也能调用MyDes的__get__方法
-
请问以下代码会打印什么内容?
class MyDes: def __init__(self, value = None): self.val = value def __get__(self, instance, owner): return self.val - 20 def __set__(self, instance, value): self.val = value + 10 print(self.val) class C: x = MyDes() if __name__ == '__main__': # 该模块被执行的话,执行下边语句。 c = C() c.x = 10 print(c.x)
20
0
c.x=10触发了__set__方法 所以c.x修改为10+10=20 print(c.x)打印出20 并触发了__get__方法,c.x的值修改为20-20=0 然后在get里面打印出来0
-
请问以下代码会打印什么内容?
>>> class MyDes: def __init__(self, value = None): self.val = value def __get__(self, instance, owner): return self.val ** 2 >>> class Test: def __init__(self): self.x = MyDes(3) >>> test = Test() >>> test.x
访问实例层次上的描述符 x,只会返回描述符本身。为了让描述符能够正常工作,它们必须定义在类的层次上。如果你不这么做,那么 Python无法自动为你调用 get 和 set 方法。
-
按要求编写描述符 MyDes:当类的属性被访问、修改或设置的时候,分别做出提醒。
>>> class Test: x = MyDes(10, 'x') >>> test = Test() >>> y = test.x 正在获取变量: x >>> y 10 >>> test.x = 8 正在修改变量: x >>> del test.x 正在删除变量: x 噢~这个变量没法删除~ >>> test.x 正在获取变量: x 8
class MyDes: def __init__(self, initval=0, attr=None): self.Value = initval self.attr = attr def __get__(self, instance, owner): print('正在获取变量: ' + self.attr) return self.Value def __set__(self, instance, value): print('正在修改变量: ' + self.attr) self.Value = value def __delete__(self, instance): print('正在删除变量:' + self.attr) del self class Test: x = MyDes(10, 'x')
-
按要求编写描述符 Record:记录指定变量的读取和写入操作,并将记录以及触发时间保存到文件:record.txt
>>> class Test: x = Record(10, 'x') y = Record(8.8, 'y') >>> test = Test() >>> test.x 10 >>> test.y 8.8 >>> test.x = 123 >>> test.x = 1.23 >>> test.y = "I love FishC.com!" >>>
# 按要求编写描述符 Record:记录指定变量的读取和写入操作,并将记录以及触发时间保存到文件:record.txt import time as t class Record: def __init__(self, initval, name): self.log_file = '/Users/felix_yang/PycharmProjects/learningpython/46/record.txt' self.Value = initval self.name = name self.action = None self.atime = None def __get__(self, instance, owner): self.action = '读取' self.atime = t.strftime("%a %b %d %H:%M:%S %Y %z", t.gmtime()) self.event = '{} 变量于北京时间 {} 被 {}, {}={}'.format(self.name, self.atime, self.action, self.name, self.Value ) self._logging(self.event) return self.Value def __set__(self, instance, value): self.Value = value self.action = '修改' self.atime = t.strftime("%a %b %d %H:%M:%S %Y %z", t.gmtime()) self.event = '{} 变量于北京时间 {} 被 {}, {}={}'.format(self.name, self.atime, self.action, self.name, self.Value ) self._logging(self.event) def _logging(self, event): with open(self.log_file, 'a') as f: f.write(event) f.write('\n')
课后答案:
import time class Record: def __init__(self, initval=None, name=None): self.name=name self.Value=initval def __get__(self,instance,owner): f=open('record.txt','a') f.write("%s 变量于北京时间%s被访问,%s = %s\n" % (self.name, time.ctime(), self.name,str(self.Value))) f.close() return self.Value def __set__(self,instance,Value): f=open('record.txt','a') f.write("%s 变量于北京时间%s被修改,%s = %s\n" % (self.name, time.ctime(), self.name,str(self.Value))) f.close() self.Value=Value def __delete__(self,instance): del self class Test: x = Record(10, 'x') y = Record(8.8, 'y')
-
再来一个有趣的案例:编写描述符 MyDes,使用文件来存储属性,属性的值会直接存储到对应的pickle(腌菜,还记得吗?)的文件中。如果属性被删除了,文件也会同时被删除,属性的名字也会被注销。
举个栗子:
>>> class Test: x = MyDes('x') y = MyDes('y') >>> test = Test() >>> test.x = 123 >>> test.y = "I love FishC.com!" >>> test.x 123 >>> test.y 'I love FishC.com!'
产生对应的文件存储变量的值:
>>> del test.x >>>
# 再来一个有趣的案例:编写描述符 MyDes,使用文件来存储属性,属性的值会直接存储到对应的pickle # (腌菜,还记得吗?)的文件中。如果属性被删除了,文件也会同时被删除,属性的名字也会被注销。 import os import pickle class MyDes: def __init__(self, name): self.attr_file = None self.name = name self.Value = None def __get__(self, instance, owner): return self.Value def __set__(self, instance, value): self.attr_file = '/Users/felix_yang/PycharmProjects/learningpython/46/ %s.pkl' % self.name self.Value = value self._storeattr(self.Value) def __delete__(self, instance): self.attr_file = '/Users/felix_yang/PycharmProjects/learningpython/46/ %s.pkl' % self.name os.remove(self.attr_file) del self def _storeattr(self, attr): with open(self.attr_file, 'wb') as pickle_file: pickle.dump(attr, pickle_file)
课后答案:
import os import pickle class MyDes: def __init__(self,name=None): self.name=name self.filePath=self.name+'.txt' self.saved=[] def __get__(self,instance,owner): if self.name in self.saved: return self.Value else: print("属性尚未赋值") def __set__(self,instance,Value): self.Value=Value f=open(self.filePath,'wb') pickle.dump( str("%s修改值为%s" %(self.name,self.Value)),f) f.close() self.saved.append(self.name) def __delete__(self,instance): os.remove(self.filePath) del self class Test: x = MyDes('x') y = MyDes('y') test=Test() test.x test.x=10


-
协议(Protocols)与其他编程语言中的接口很相似,它规定你哪些方法必须要定义。然而,在Python中的协议就显得不那么正式。事实上,在Python中,协议更像是一种指南。
-
定制容器的协议
- 如果你希望定制的容器是不可变的话,你只需要定义
__len__()和__getitem__()方法 (str、tuple) - 如果你希望定制的容器是可变的话,你需要定义
__len__()、__getitem__()、__setitem__()和__delitem__()方法 (list)
- 如果你希望定制的容器是不可变的话,你只需要定义
-
下表列举了定制容器类型相关的魔法方法及定义
__len__(self) 定义当被 len() 调用时的行为(返回容器中元素的个数) __getitem__(self, key) 定义获取容器中指定元素的行为,相当于 self[key] __setitem__(self, key, value) 定义设置容器中指定元素的行为,相当于 self[key] = value __delitem__(self, key) 定义删除容器中指定元素的行为,相当于 del self[key] __iter__(self) 定义当迭代容器中的元素的行为 __reversed__(self) 定义当被 reversed() 调用时的行为 __contains__(self, item) 定义当使用成员测试运算符(in 或 not in)时的行为
-
一个例子
-
定义一个不可改变的列表,且可以记录每个元素的访问次数
In [22]: class MyList: ...: # python中很有趣的两个小东西,先介绍: ...: # 1、*args保存多余变量,保存方式为元组。 ...: # 2、**args保存带有变量名的多余变量,保存方式为字典。 ...: def __init__(self, *args): ...: self.values = [x for x in args] ...: self.count = {}.fromkeys(range(len(self.values)), 0) #这里使用列表的下标作为字典的键,注意不能用元素作为字典的键 #因为列表的不同下标可能有值一样的元素,但字典不能有两个相同的键 ...: ...: def __len__(self): ...: return len(self.count) ...: ...: def __getitem__(self, item): ...: self.count[item] += 1 ...: return self.values[item] ...: In [23]: In [23]: list1 = MyList(1, 3, 4) In [24]: list1[0] Out[24]: 1 In [25]: list1[1] Out[25]: 3 In [26]: list1.count Out[26]: {0: 1, 1: 1, 2: 0}
-
-
你知道 Python 基于序列的三大容器类指的是什么吗?
List, Turple, String
-
Python 允许我们自己定制容器,如果你想要定制一个不可变的容器(像 String),你就不能定义什么方法?
如果你想要定制一个不可变的容器(像 String),你就不能定义像 __ setitem __() 和 __ delitem __() 这些会修改容器中的数据的方法。
-
如果希望定制的容器支持 reversed() 内置函数,那么你应该定义什么方法?
__reversed__(self) -
既然是容器,必然要提供能够查询“容量”的方法,那么请问需要定义什么方法呢?
在 Python 中,我们通过 len() 内置函数来查询容器的“容量”,所以容器应该定义 __ len __() 方法。
-
通过定义哪些方法使得容器支持读、写和删除的操作?
读 —— __ getitem __(),写 —— __ setitem __(),删除 —— __ delitem __(), -
为什么小甲鱼说“在 Python 中的协议就显得不那么正式”?
在 Python 中,协议更像是一种指南。这有点像我们之前在课后作业中提到的“鸭子类型”(忘了的朋友请戳:http://bbs.fishc.com/thread-51471-1-1.html) —— 当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。Python就是这样,并不会严格地要求你一定要怎样去做,而是让你靠着自觉和经验把事情做好!
-
根据上面的例子,定制一个列表,同样要求记录列表中每个元素被访问的次数。并且支持append()、pop()、extand()原生列表所拥有的方法。
要求:
-
实现获取、设置和删除一个元素的行为(删除一个元素的时候对应的计数器也会被删除)
-
增加counter(index)方法,返回index参数所指定的元素记录的访问次数
-
实现append()、pop()、remove()、insert()、clear()和reverse()方法(重写这些方法时要注意考虑计数器的对应改变)
class CountList(list): def __init__(self, *args): super().__init__(args) self.count = [] for i in args: self.count.append(0) def __len__(self): return len(self.count) def __getitem__(self, key): self.count[key] += 1 return super().__getitem__(key) def __setitem__(self, key, value): self.count[key] += 1 super().__setitem__(key, value) def __delitem__(self, key): del self.count[key] super().__delitem__(key) def counter(self, key): return self.count[key] def append(self, value): self.count.append(0) super().append(value) def pop(self, key=-1): del self.count[key] return super().pop(key) def remove(self, value): key = super().index(value) del self.count[key] super().remove(value) def insert(self, key, value): self.count.insert(key, 0) super().insert(key, value) def clear(self): self.count.clear() super().clear() def reverse(self): self.count.reverse() super().reverse()
-
-
迭代: 类似于循环,每一个重复的过程被称为一次迭代,而每一次迭代的结果将被用来作为下一次迭代的初始值;
-
提供迭代方法的容器,被称为迭代器
-
序列:元组,列表,字符串都是迭代器,字典和文件也是迭代器; 注意字典迭代的是键
In [33]: links = {'name':'felix_yang',\ ...: 'age':12 ...: } In [35]: for each in links: ...: print(('{}->{}').format(each, links[each])) ...: name->felix_yang age->12
-
-
Python 提供了2个BIF 函数处理迭代器
-
iter()
- 对于一个容器对象,iter() 返回一个迭代器
-
next()
- 返回迭代器的下一个元素; 如果迭代器没有值可以返回了,python会抛出一个异常:StopIteration
In [36]: string = 'FishC' In [37]: it = iter(string) In [38]: next(it) Out[38]: 'F' In [40]: next(it) Out[40]: 'i' In [41]: next(it) Out[41]: 's' In [42]: next(it) Out[42]: 'h' In [43]: next(it) Out[43]: 'C' In [44]: next(it) --------------------------------------------------------------------------- StopIteration Traceback (most recent call last) Input In [44], in <cell line: 1>() ----> 1 next(it) StopIteration:
-
for 语句是怎么工作的呢?
In [45]: string = 'FishC' In [46]: it = iter(string) In [49]: while True: ...: try: ...: each = next(it) ...: except StopIteration: ...: break ...: print(each) ...: F i s h C
-
-
迭代器的魔法方法
-
__iter()__返回迭代器本身 -
__next()__决定了迭代的规则In [54]: class fibonacci: ...: def __init__(self, n=10): ...: self.a = 0 ...: self.b = 1 ...: self.n = n ...: ...: def __iter__(self): ...: return self ...: ...: def __next__(self): ...: if self.b < self.n: ...: self.a, self.b = self.b, self.a + self.b ...: else: ...: raise StopIteration ...: return self.a ...: In [55]: for each in fib: ...: print(each) ...: In [56]: fib = fibonacci(20) In [57]: for each in fib: ...: print(each) ...: 1 1 2 3 5 8 13
-
-
请用你的话解释一下“迭代”的概念?
类似于循环,每一个重复的过程被称为一次迭代,而每一次迭代的结果将被用来作为下一次迭代的初始值
-
迭代器是一个容器吗?
不是。因为我们耳熟能详的容器像列表,字典,元组都是可以存放数据的,而迭代器就是实现了__next__()方法的对象(用于遍历容器中的数据)
-
迭代器可以回退(获取上一个值)吗?
迭代器性质决定没有办法回退,只能往前进行迭代。但这并不是什么很大的缺点,因为我们几乎不需要在迭代途中进行回退操作。
-
如何快速判断一个容器是否具有迭代功能?
判断该容器是否拥有
__ iter__() 和 __ next__()魔法方法。 -
for 语句如何判断迭代器里边已经取空了?
迭代器通过 __ next__() 方法每次返回一个元素,并指向下一个元素。如果当前位置已无元素,通过抛出 StopIteration 异常表示。
-
在 Python 原生支持的数据结构中,你知道哪一个是只能用迭代器访问的吗?
set。对于原生支持随机访问的数据结构(如tuple、list),可以使用迭代器或者下标索引的形式访问,但对于无法随机访问的数据结构 set 而言,迭代器是唯一的访问元素的方式。
注意,集合的元素是无序的,无法通过索引操作元素;
>>> set1 = set([1, 2, 3, 4, 5, 5]) >>> set1 {1, 2, 3, 4, 5}
-
用 while 语句实现与以下 for 语句相同的功能:
for each in range(5): print(each)
程序:
it = iter(range(5)) while True: try: each = next(it) except StopIteration: break print(each)
-
写一个迭代器,要求输出至今为止的所有闰年。如:
>>> leapYears = LeapYear() >>> for i in leapYears: if i >=2000: print(i) else: break 2012 2008 2004 2000
程序:
import datetime as dt class LeapYear: def __init__(self): self.now = dt.date.today().year def isLeapYear(self, year): if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0): return True else: return False def __iter__(self): return self def __next__(self): while not self.isLeapYear(self.now): self.now -= 1 temp = self.now self.now -= 1 return temp
In [114]: import datetime as dt ...: ...: ...: class LeapYear: ...: def __init__(self): ...: self.now = dt.date.today().year ...: ...: def isLeapYear(self, year): ...: if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0): ...: return True ...: else: ...: return False ...: ...: def __iter__(self): ...: return self ...: ...: def __next__(self): ...: while not self.isLeapYear(self.now): ...: self.now -= 1 ...: ...: temp = self.now ...: self.now -= 1 ...: ...: return temp ...: In [115]: leapYears = LeapYear() ...: for i in leapYears: ...: if i >= 2000: ...: print(i) ...: else: ...: break ...: 2020 2016 2012 2008 2004 2000
-
要求自己写一个 MyRev 类,功能与 reversed() 相同(内置函数 reversed(seq) 是返回一个迭代器,是序列 seq 的逆序显示)。例如:
>>> myRev = MyRev("FishC") >>> for i in myRev: print(i, end='') ChsiF程序:
class MyRev: def __init__(self, item): self.item = item self.index = -1 def __iter__(self): return self def __next__(self): try: temp = self.item[self.index] self.index -= 1 except IndexError: raise StopIteration return temp In [130]: myRev = MyRev("FishC") In [131]: In [131]: for i in myRev: ...: print(i, end='') ...: ChsiF
-
协同程序就是可以运行的独立函数调用,函数可以暂停或者挂起,并在需要的时候在程序离开的地方继续或者重新开始
-
生成器是迭代器的一种,是一种特殊的函数,调用可以中断,可以暂停;
-
生成器实现方式一: 在普通函数中加入yield 语句
In [1]: def myGen(): ...: print('生成器被执行!') ...: yield 1 ...: yield 2 ...: In [3]: myG = myGen() In [4]: next(myG) 生成器被执行! Out[4]: 1 In [5]: next(myG) Out[5]: 2 In [6]: next(myG) --------------------------------------------------------------------------- StopIteration Traceback (most recent call last) Input In [6], in <cell line: 1>() ----> 1 next(myG) StopIteration:
In [8]: def myGen(): ...: print('生成器被执行!') ...: yield 1 ...: yield 2 In [10]: myG = myGen() In [11]: for i in myG: ...: print(i) ...: 生成器被执行! 1 2
- fibonacci 数列通过生成器来实现
def fiboGen(m): a, b = 0, 1 while b < m: yield b a, b = b, a + b return 'done' f = fiboGen(10) for i in f: print(i)
In [12]: def fiboGen(m): ...: a, b = 0, 1 ...: while b < m: ...: yield b ...: a, b = b, a + b ...: return 'done' ...: In [13]: f = fiboGen(10) In [14]: next(f) Out[14]: 1 In [15]: for i in f: ...: print(i) ...: 1 2 3 5 8
-
生成器实现方式二:
- 推导式: 列表推导式,字典推导式,集合推导式
In [16]: a = [i for i in range(100) if not (i % 2) and i % 3] In [17]: a Out[17]: [2, 4, 8, 10, 14, 16, 20, 22, 26, 28, 32, 34, 38, 40, 44, 46, 50, 52, 56, 58, 62, 64, 68, 70, 74, 76, 80, 82, 86, 88, 92, 94, 98] In [18]: b = {i:i % 2 == 0 for i in range(10)} In [19]: b Out[19]: {0: True, 1: False, 2: True, 3: False, 4: True, 5: False, 6: True, 7: False, 8: True, 9: False} In [20]: c = {i for i in [1,1, 2, 3, 4, 4, 5, 6]} In [21]: c Out[21]: {1, 2, 3, 4, 5, 6}
- 那有没有元组推导式呢?
In [22]: e = (i for i in range(0)) In [23]: e Out[23]: <generator object <genexpr> at 0x106a87120>
其实用()括起来的推导式,其实就是生成器 “”
In [24]: sum((i for i in range(100) if i % 2)) Out[24]: 2500 In [25]: sum(i for i in range(100) if i % 2) Out[25]: 2500
-
通常,一般的函数从第一行代码开始执行,并在什么情况下结束?
对于调用一个普通的 Python 函数,一般是从函数的第一行代码开始执行,结束于 return 语句、异常或者函数所有语句执行完毕。一旦函数将控制权交还给调用者,就意味着全部结束。函数中做的所有工作以及保存在局部变量中的数据都将丢失。如果再次调用这个函数时,一切都将重新开始。
-
什么是协同程序?
所谓的协同程序就是可以运行的独立函数调用,函数可以暂停或者挂起,并在需要的时候从程序离开的地方继续或者重新开始。 Python 是通过生成器来实现类似于协同程序的概念:生成器可以暂时挂起函数,并保留函数的局部变量等数据,然后在再次调用它的时候,从上次暂停的位置继续执行下去。
-
生成器所能实现的任何操作都可以由迭代器来代替吗,为什么?
是的,都可以。因为生成器事实上就是基于迭代器来实现的,生成器只需要一个 yield 语句即可,但它内部会自动创建 __ iter__() 和 __ next__() 方法。
-
将一个函数改造为生成器,说白了就是把什么语句改为 yield 语句?
Return 语句
-
说到底,生成器的最大作用是什么?
使得函数可以“保留现场”,当下一次执行该函数是从上一次结束的地方开始,而不是重头再来。
-
如下,get_prime() 是一个获得素数的生成器,请问第 2 行代码 while True 有何作用?
def get_primes(number): while True: if is_prime(number): yield number number += 1
这个 while True 循环是用来确保生成器函数永远也不会执行到函数末尾的。只要调用 next() 这个生成器就会生成一个值。这是一个处理无穷序列的常见方法(这类生成器也是很常见的)。
-
要求实现一个功能与 reversed() 相同(内置函数 reversed(seq) 是返回一个迭代器,是序列 seq 的逆序显示)的生成器。例如:
>>> for i in myRev("FishC"): print(i, end='') ChsiFdef myRev(seq): seq_len = len(seq) index = -1 # seq[0] == seq[-seq_len] while index >= -seq_len: temp = seq[index] yield temp index -= 1 for i in myRev("FishC"): print(i, end='')
-
10 以内的素数之和是:2 + 3 + 5 + 7 = 17,那么请编写程序,计算 2000000 以内的素数之和?
import math def is_prime(number): if number > 1: if number == 2: return True if number % 2 == 0: return False for current in range(3, int(math.sqrt(number) + 1), 2): if number % current == 0: return False return True return False def get_primes(number): while True: if is_prime(number): yield number number += 1 def solve(): total = 2 for next_prime in get_primes(3): if next_prime < 2000000: total += next_prime else: print(total) return if __name__ == '__main__': solve()
- 什么是模块,简单来说,模块就是程序,保存为.py 的文件
- 容器: 数据的分装
- 函数: 语句的封装
- 类: 方法和属性的封装
- 命名空间
- 导入模块:
- import moduleName
- From moduleName import functionName
- import moduleName as newName
-
说到底,Python 的模块是什么?
模块就是程序。没错,所谓模块就是平时我们写的任何代码,然后保存的每一个“.py”结尾的文件,都是一个独立的模块。
-
请问我如何在另外一个源文件 test.py 里边使用 hello.py 的 hi() 函数呢?
def hi(): print("Hi everyone, I love FishC.com!") 12
import hello as h h.hi() -
你知道的总共有几种导入模块的方法
第一种:import 模块名 第二种:from 模块名 import 函数名 第三种:import 模块名 as 新名字
-
曾经我们讲过有办法阻止 from…import * 导入你的“私隐”属性,你还记得是怎么做的吗?
如果你不想模块中的某个属性被 from…import * 导入,那么你可以给你不想导入的属性名称的前边加上一个下划线(_)。不过需要注意的是,如果使用 import … 导入整个模块,或者显式地使用 import xx._oo 导入某个属性,那么这个隐藏的方法就不起作用了。
-
倘若有 a.py 和 b.py 两个文件,内容如下:
# a.py def sayHi(): print("嗨,我是 A 模块~") # b.py def sayHi(): print("嗨,我是 B 模块~")
那么我在 test.py 文件中执行以下操作,会打印什么结果?
# test.py from a import sayHi from b import sayHi sayHi()
会打印“嗨,我是 B 模块~”,因为第二次导入的 b 模块把 a 模块的同名函数 sayHi() 给覆盖了,这就是所谓命名空间的冲突。所以,在项目中,特别是大型项目中我们应该避免使用 from…import…,除非你非常明确不会造成命名冲突。
-
执行下边 a.py 或 b.py 任何一个文件,都会报错,请尝试解释一下此现象。
# a.py from b import y def x(): print('x') # b.py from a import x def y(): print('y') >>> Traceback (most recent call last): File "/Users/FishC/Desktop/a.py", line 1, in <module> from b import x File "/Users/FishC/Desktop/b.py", line 1, in <module> import a File "/Users/FishC/Desktop/a.py", line 1, in <module> from b import x ImportError: cannot import name 'x'
这个是循环嵌套导入问题。无论运行 a.py 或 b.py 哪一个文件都会抛出 ImportError 异常。这是因为在执行其中某一个文件(a.py)的加载过程中,会创建模块对象并执行对应的字节码。但当执行第一个语句的时候需要导入另一个文件(from b import y),因此 CPU 会转而去加载另一个文件(b.py)。同理,执行另一个文件的第一个语句(from a import x)恰好也是需要导入之前的文件(a.py)。此时,之前的文件处于仅导入第一条语句的阶段,因此其对应的字典中并不存在 x,故抛出“ImportError: cannot import name ‘x’”异常。
解决方案是直接使用 import 语句导入:
# a.py import b def x(): print('x') # b.py import a def y(): print('y') a.x()
-
问大家一个问题:Python 支持常量吗?相信很多鱼油的答案都是否定的,但实际上 Python 内建的命名空间是支持一小部分常量的,比如我们熟悉的 True,False,None 等,只是 Python 没有提供定义常量的直接方式而已。那么这一题的要求是创建一个 const 模块,功能是让 Python 支持常量。
说到这里大家可能还是一头雾水,没关系,我们举个栗子。
test.py 是我们的测试代码,内容如下:
# const 模块就是这道题要求我们自己写的 # const 模块用于让 Python 支持常量操作 import const const.NAME = "FishC" print(const.NAME) try: # 尝试修改常量 const.NAME = "FishC.com" except TypeError as Err: print(Err) try: # 变量名需要大写 const.name = "FishC" except TypeError as Err: print(Err)
执行后的结果是:
>>> FishC 常量无法改变! 常量名必须由大写字母组成!
在 const 模块中我们到底做了什么,使得这个模块这么有“魔力”呢?大家跟着小甲鱼的提示,一步步来做你就懂了:
提示一:我们需要一个 Const 类 提示二:重写 Const 类的某一个魔法方法,指定当实例对象的属性被修改时的行为 提示三:检查该属性是否已存在 提示四:检查该属性的名字是否为大写 提示五:细心的鱼油可能发现了,怎么我们这个 const 模块导入之后就把它当对象来使用(const.NAME = “FishC”)了呢?难道模块也可以是一个对象?没错啦,在 Python 中无处不对象,到处都是你的对象。使用以下方法可以将你的模块与类 A 的对象挂钩。
''' sys.modules 是一个字典,它包含了从 Python 开始运行起,被导入的所有模块。键就是模块名,值就是模块对象。 ''' import sys sys.modules[__name__] = A()
呃……好像说得有点太多了,大家一定要自己动手先尝试完成哦
程序如下:
class Const: def __setattr__(self, name, value): if hasattr(self, name): raise TypeError('常量无法改变!') if not name.isupper(): raise TypeError('常量名必须由大写字母组成!') super().__setattr__(name, value) import sys sys.modules[__name__] = Const()
-
代码模块化的优势
-
代码阅读性和测试,分开更有利
-
代码的重用
-
-
if __name__ == '__main__'-
举一个例子,模块中有测试代码
模块代码:test.py
def c2f(cel): fah = cel * 1.8 + 32 return fah def f2c(fah): cel = (fah - 32) / 1.8 return cel def test(): print("测试,0摄氏度 = %.2f华氏度" % c2f(0)) print("测试,0华氏度 = %.2f摄氏度" % f2c(0)) test()
直接运行模块,进行测试:
测试,0摄氏度 = 32.00华氏度 测试,0华氏度 = -17.78摄氏度程序代码(导入模块:test):
import test as tc print('32 摄氏度 = %.2f 华氏度' % tc.c2f(32)) print('32 华氏度 = %.2f 摄氏度' % tc.f2c(32))
运行结果:(出问题了:打印了测试代码的输出)
# 打印了测试代码的输出 测试,0摄氏度 = 32.00华氏度 测试,0华氏度 = -17.78摄氏度 32 摄氏度 = 89.60 华氏度 32 华氏度 = 0.00 摄氏度 -
原因分析:
- 导入模块的时候,运行了模块中的测试代码:test()
-
解决方法:
使用
__name__属性在判断是否需要运行测试代码if __name__ == '__main__': test()
所有模块都有一个 name 属性,name 的值取决于如何应用模块,在作为独立程序运行的时候,name 属性的值是 ‘main’,而作为模块导入的时候,这个值就是该模块的名字了。
- 导入模块,运行主程序,在模块中调用
__name__属性,值是模块名 - 直接运行模块程序,
__name__属性,值是'__main__'
In [7]: __name__ Out[7]: '__main__' In [8]: tc.__name__ Out[8]: 'test'
- 导入模块,运行主程序,在模块中调用
-
-
搜索路径
-
推荐放置模块的位置:'/opt/homebrew/lib/python3.9/site-packages'; (不同的OS位置不一样)
In [8]: import sys In [9]: sys.path Out[9]: ['/opt/homebrew/bin', '/opt/homebrew/Cellar/python@3.9/3.9.13_1/Frameworks/Python.framework/Versions/3.9/lib/python39.zip', '/opt/homebrew/Cellar/python@3.9/3.9.13_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9', '/opt/homebrew/Cellar/python@3.9/3.9.13_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/lib-dynload', '', '/opt/homebrew/lib/python3.9/site-packages', '/opt/homebrew/opt/python-tk@3.9/libexec'] -
可以添加模块路径
sys.path.append('module_path'),以把相关的模块导入进来
-
-
包(package)
-
创建一个文件夹,用于存放相关的模块。文件夹的名字即包的名字;
-
在文件夹中创建一个
__init__.py的模块文件,内容可以为空; -
将相关的模块放入文件夹中
# 上面这个例子,可以把test 模块放入到M 包中,修改主程序cal.py 的代码,导入包.模块:M.test import M.test as tc print('32 摄氏度 = %.2f 华氏度' % tc.c2f(32)) print('32 华氏度 = %.2f 摄氏度' % tc.f2c(32))
-
-
__name__属性的含义是什么?所有模块都有一个 name 属性,name 的值取决于如何应用模块,在作为独立程序运行的时候,name 属性的值是 ‘main’,而作为模块导入的时候,这个值就是该模块的名字了。
- 导入模块,运行主程序,在模块中调用
__name__属性,值是模块名 - 直接运行模块程序,
__name__属性,值是'__main__'
- 导入模块,运行主程序,在模块中调用
-
什么时候
__name__属性,值是'__main__'?模块在作为独立程序运行的时候,
__name__属性的值是'__main__' -
如果获得当前python的搜索路径?
import sys sys.path
-
如果你不想讲相关的模块文件放到当前文件夹中,那最好的选择是?
可以创建一个包(package),放在 site-packages 文件夹,因为它就是用来存放你的模块文件的。
-
如果你遇到import urllib.request,那么这个urllib是什么?
是一个包,Python 把同类的模块放在一个文件夹中统一管理,这个文件夹称之为一个包。
urllib 是 Python 负责管理 URL 的包,用于访问网址(后边我们会讲到)
-
Python 如何区分一个文件夹是一个包还是一个普通文件夹?
看文件夹中是否有 init.py 文件。
必须在包文件夹中创建一个 init.py 的模块文件,内容可以为空。可以是一个空文件,也可以写一些初始化代码。这个是 Python 的规定,用来告诉 Python 将该目录当成一个包来处理。
-
执行下面的a.py 或者 b.py任何一个文件,都会报错,请改正程序
-
下边是一个python项目的基本结构,请你合理组织它们,便于维护和使用
鱼C大项目 % tree ./ ./ ├── LICENSE.txt ├── README ├── docs ├── help.html ├── images ├── moduleA.py ├── moduleB.py ├── moduleC.py ├── package │ ├── moduleA.py │ ├── moduleB.py │ ├── moduleC.py │ └── static │ ├── images │ └── sounds ├── quickstart.html ├── readme.txt ├── requirements.txt ├── setup.py ├── sounds ├── static ├── test ├── test_advanced.py └── test_basic.py 10 directories, 14 files
答:通过将相关的模块组织成包,使项目结构更为完善和合理。从而增强代码的可维护性和实用性。 以下提供一个可供参考的Python项目结构(仅供参考,没有硬性规定): |----README/ | |----readme.txt | |----LICENSE.txt | |----requirents.txt | |----setup.py |----docs/ | |----help.html | |----quickstart.html |----test/ | |----__init__.py | |----test_basic.py | |----test_advanced.py |----package/ | |----__init__.py | |----moduleA.py | |----moduleB.py | |----moduleC.py | |----static/ | | |----images/ | | |----sounds/ |----setup.py

大家可能还不知道,在Python的社区里有句俗话:“Python自己带着电池(Batteries included)”,什么意思呢?要从Python的设计哲学说起,Python的设计哲学是:优雅、明确和简单。因此,Python开发者演变出来的哲学就是,用一种方法,最好是只有一种方法来做一件事。虽然小甲鱼常常鼓励大家多思考,条条大路通罗马,那是为了训练大家的发散性思维,但是在正式编程中,如果有完善、并且经过严密测试过的模块可以直接实现,那么最好就是使用现成的模块来工作。
-
所以Python附带安装的有Python标准库,一般我们说的电池就是Python标准库中的模块,这些模块都极其有用,Python标准库中包含一般任务所需要的模块,不过呢,Python标准库包含的模块有数100个之多,一个个单独来讲那着实是不科学的,所以这一讲,我们将学习如何独立的来探索模块。
-
对于Python来说,学习资料其实一直都在身边,因为Python不仅带着电池,还带着充电器!,我们这里给大家分析,遇到问题,我们应该如何去找答案,其实90%的答案你都可以通过我们以下的方式来找到解决的方法。
-
首先要做的就是打开Python的文档,打开IDLE->Help->Python Docs(F1),如下:

※1、What’s new in Python3.8?
介绍了3.8有什么新的特征,新的特性,列举自Python2.0以后所以的新特性。
※2、Tutorial
是一个简易的教程,简单地介绍了python的语法
※3、Liberary Reference
Python的枕边书,这里边详细的列举了python所有内置函数和标准库各个模块的用法,非常详细,但是,你从头到尾是看不完的,当做字典来查就可以了。
※4、Inatalling Python Modules
是一个教你如何安装python第三方模块的教程
※5、Distuributing Python Modules
教你如何发布Python的第三方模块,你需要知道,Python除了标准库的几百个官方模块之外,还有一个叫做 pypi 的社区,----https://pypi.python.org/pypi, 搜集了全球Python爱好者贡献出来的模块,你自己也可以写一个模块发布到pypi社区,分享给全世界。
※6、language reference
讨论Python的语法和设计哲学
※7、Python setup and usage
谈论Python如何在不同平台上使用
※8、Python HOWTOs
针对一些特定的主题进行深入并且详细的探讨
※9、Extending and Embedding
介绍如何用 C和 C++ 来开发Python的扩展模块,还有开发对应所需要的API函数
※10、FAQs
这个是常见问题解答
-
PEP是Python Enhancement Proposals 的缩写,翻译过来就是Python增强建议书的意思。它是用来规范与定义Python的各种加强和延伸功能的技术规格,好让Python开发社区能有共同遵循的依据。
-
每一个PEP都有一个唯一的编号,这个编号一旦给定就不会再改变。例如,PEP 3000 就是用来定义 Python 3.0 的相关技术规格;而PEP 333 则是 Python 的 Web 应用程序界面 WSGI (Web Server Gateway Interface 1.0)的规范。关于PEP 本身的相关规范定义在 PEP 1,而PEP 8 则定义了 Python 代码的风格指南。
-
有关 PEP 的列表大家可以参考 PEP 0 :https://www.python.org/dev/peps/
-
比如说现在需要用到timeit模块,但自己不清楚,可以通过索引和搜索去查找查看学习timeit的文档,,如下:里边有简单的使用方法、介绍,以及这个模块里边包含了哪些类,哪些函数,还有哪些变量,他们的功能以及用法,最后有个例子,大部分文档都遵循这个顺序讲解
-
想要快速掌握一个模块的用法,最好是使用IDLE 交互界面,首先 import 该模块,然后可以调用 __doc__属性,这样就可以查看到这个模块的简介
-
事实上你对于这个方法应该很熟悉了,这跟我们之间讲过的函数文档是一样的,就是写在模块最开头的那个字符串,这个字符串是带格式的,我们可以使用 print() 把这个格式打印出来。会有缩进,换行,会显得更好看一点:
-
然后你可能需要知道这个模块里面定义了哪些变量,哪些函数,哪些类,你可以用 dir() 内置方法把它显示出来:
-
显示出来的这些并不是所有的名字对我们都有用,所以我们需要过滤一些我们不需要的东西,那你可能留意到 __all__这个属性了,这个属性事实上他就是帮助我们完成过滤的过程,我们调用 __all__属性:
-
它回给我们的是一个列表,这个列表只有4个成员,如果你有看前面的关于 timeit 的文档的话,你会发现,Timer是一个类,timeit、repeat、default_timer 是3个接口函数。所以,我们这个 all 属性显示出来的就是这个模块可以供外界调用的所有东西
这里有两点需要注意的,
-
第一个不是所有的模块都有 all 属性,有 all 的话,这个属性里面包含的内容就是作者希望外部调用的名字,这些函数这些类,其它的就是不希望外部调用的了。
-
第二点就是,如果一个模块设置了 all 属性,那么使用 from ‘模块名’ import * 语句导入到命名空间的操作,只有 all 属性这里面的名字才能被导入。例如:
设置了__all__ 属性,只有 all 属性这里面的名字才能被导入,如第一个Timer。但是如果你没有设置这个 all 属性的话,from ‘模块名’ import * 就会把所有不以下划线开头的名字都导入到当前命名空间,所以,我们建议,在编写模块的时候,对外提供接口函数和类都设置到 all 属性的列表中去,这样子是比较规范的做法。
-
-
还有一个属性叫做 file 属性,这个属性是指明了该模块的源代码所在的位置







-
我们说过,快速提高编程能力有三大法宝
-
一个就是不断地编写代码
-
第二个就是阅读高手的代码
-
最后我们还可以使用 help() 函数,比doc属性详细一点,比官方文档简单一点,介于中间的一个帮助文档,可以快速知道各个函数的用法
-

总共 16 道题,不上机的情况下答中 14 道以下请自觉忏悔!
注:题目虽然简单,但有陷阱,反正这一讲也没什么要测试的,就考考大家常识^_^
-
请问以下代码会打印什么内容?
>>> def func(): pass >>> print(type(func()))A. <type ‘function’> B. <type ‘tuple’> C. <type ‘NoneType’> D. <type ‘type’>C
-
请问以下代码会打印什么内容?
>>> print(type(1J))A. <type ‘unicode’> B. <type ‘int’> C. <type ‘str’> D. <type ‘complex’>D
-
请问以下代码会打印什么内容?
>>> print(type(lambda:None))A. <type ‘NoneType’> B. <type ‘function’> C. <type ‘int’> D. <type ‘tuple’>
B
-
请问以下代码会打印什么内容?
>>> a = [1, 2, 3, "FishC", ('a', 'b', 'c'), [], None] >>> print(len(a))A. 13 B. 7 C. 6 D. 5
B
-
请问以下代码会打印什么内容?
class A: def __init__(self, x): x = x + 1 self.v1 = x class B(A): def __init__(self, x): x = x + 1 self.v2 = x >>> b = B(8) >>> print("%d %d" % b.v1, b.v2)A. 9 10 B. 9 9 C. 10 10 D. 抛出异常
D
-
请问以下代码会打印什么内容?
class A: def __init__(self, x): self.x = x x = 666 >>> a = A() >>> a = A(888) >>> a.xA. 666 B. 888 C. None D. 抛出异常
B
-
请问以下代码会打印什么内容?
values = [1, 1, 2, 3, 5] nums = set(values) def checkit(num): if num in nums: return True else: return False for i in filter(checkit, values): print(i, end=' ')A. 1 2 3 5 B. 1 1 2 3 5 C. 1 2 3 4 3 2 1 D. 抛出异常
B
-
请问以下代码会打印什么内容?
values = [1, 1, 2, 3, 5] def transform(num): return num ** 2 for i in map(transform, values): print(i, end=' ')A. 1 1 4 9 25 B. 1 1 2 3 5 C. 0.5 0.5 1 1.5 2.5 D. 2 2 4 6 10
A
-
请问以下代码会打印什么内容?
class A: def __init__(self, x): self.x = x a = A(100) a.__dict__['y'] = 50 print(a.y + len(a.__dict__))A. 2 B. 50 C. 51 D. 52
D
-
请问以下代码会打印什么内容?
class A: def __init__(self): pass def get(self): print(__name__) >>> a = A() >>> a.get()A. A B. a C. __main__ D. _A__a
C
-
请问以下代码会打印什么内容?
country_counter = {} def addone(country): if country in country_counter: country_counter[country] += 1 else: country_counter[country] = 1 addone('China') addone('Japan') addone('China') addone("American") print(len(country_counter))A. 0 B. 1 C. 2 D. 3
D
-
请问以下代码会打印什么内容?
dict1 = {} dict1[1] = 1 dict1['1'] = 2 dict1[1.0] = 3 result = 0 for each in dict1: print(dict1[each]) result += dict1[each] print(result)A. 2 B. 3 C. 5 D. 6
C; 注意 dict1[1] 和dict1[1.0] 的键值是一样的
-
请问以下代码会打印什么内容?
def dostuff(param1, *param2): print type(param2) dostuff('apples', 'bananas', 'cherry', 'dates')A. <type ‘int’> B. <type ‘str’> C. <type ‘tuple’> D. <type ‘dict’>
C
-
请问以下代码会打印什么内容?
class A: def __init__(self, a, b, c): self.x = a + b + c a = A(1,2,3) b = getattr(a, 'x') setattr(a, 'x', b+1) print(a.x)A. 1 B. 2 C. 6 D. 7
D
-
请问以下代码会打印什么内容?
list1 = [1, 2] list2 = [3, 4] dict1 = {'1':list1, '2':list2} dict2 = dict1.copy() dict1['1'][0] = 5 result = dict1['1'][0] + dict2['1'][0] print(result)A. 5 B. 6 C. 8 D. 10
D
-
请问以下代码会打印什么内容?
import copy list1 = [1, 2] list2 = [3, 4] dict1 = {'1':list1, '2':list2} dict2 = copy.deepcopy(dict1) dict1['1'][0] = 5 result = dict1['1'][0] + dict2['1'][0] print(result)A. 5 B. 6 C. 8 D. 10
B