BinSwarm is a tool used to reproduce a single Travis build for a C based project. All Docker conatainers that are used to build a project are made public here. This project was used to create the dataset for our TSE paper:
@article{ahmed2021learning,
title={Learning to Find Usage of Library Functions in Optimized Binaries},
author={Ahmed, Toufique and Devanbu, Premkumar and Sawant, Anand Ashok},
journal={IEEE Transactions on Software Engineering},
year={2021},
publisher={IEEE}
}
BinSwarm is an edited version of BugSwarm (see below for the original readme on BugSwarm). In contrast to BugSwarm, BinSwarm simply needs to be pointed to a project that has a travis file and a build history and the tool wil;l try to find the appropriate Docker image that can build the latest build.
To start with BinSwarm, you have to first run:
python3 setup.py install
You also have to setup the Travis build CLI tools, instructions can be found here
To run a build for a project, the project has to first be downloaded locally. Then the following command can be run on it:
python3 pair-culler/single_build.py -r <project_name> -p <project_address_on_disk> -b <project_branch>
BugSwarm is a framework that enables the creation of scalable, diverse, real-world, continuously growing set of reproducible build failures and fixes from open-source projects.
The framework consist of two major components: Miner and Reproducer.
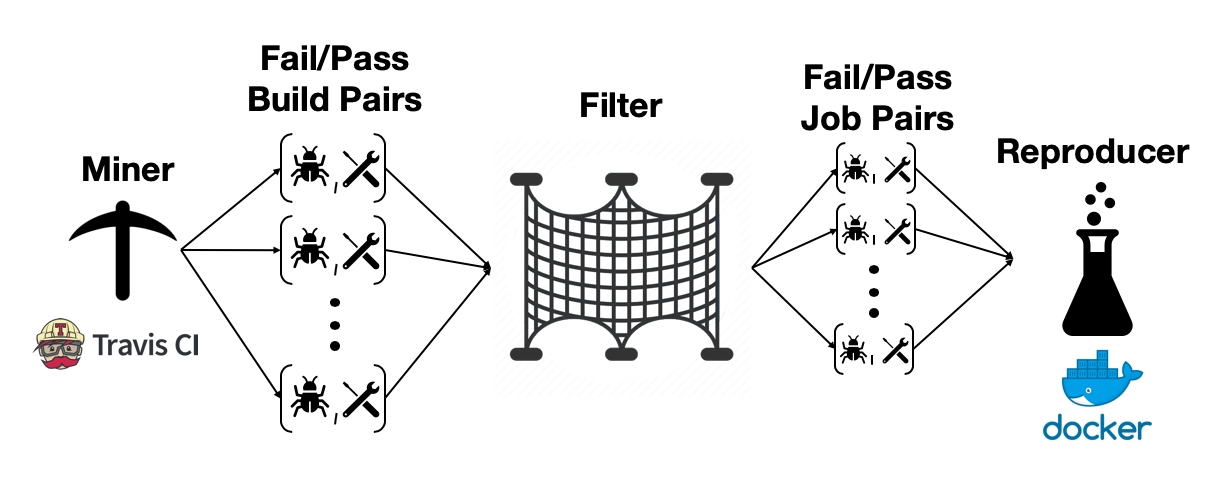 Datasets play an important role in the advancement of software tools and facilitate their evaluation. BugSwarm is an infrastructure to automatically create a large dataset of real-world reproducible failures and fixes
Datasets play an important role in the advancement of software tools and facilitate their evaluation. BugSwarm is an infrastructure to automatically create a large dataset of real-world reproducible failures and fixes
For more details:
- Website: http://www.bugswarm.org
- DockerHub Repository for BugSwarm Dataset: https://hub.docker.com/r/bugswarm/images/tags
- ICSE-2019 Paper: BugSwarm: Mining and Continuously Growing a Dataset of Reproducible Failures and Fixes
If you use our infrastructure or dataset, please cite our paper as follows:
@inproceedings{BugSwarm-ICSE19,
author = {David A. Tomassi and
Naji Dmeiri and
Yichen Wang and
Antara Bhowmick and
Yen{-}Chuan Liu and
Premkumar T. Devanbu and
Bogdan Vasilescu and
Cindy Rubio{-}Gonz{\'{a}}lez},
title = {BugSwarm: mining and continuously growing a dataset of reproducible
failures and fixes},
booktitle = {{ICSE}},
pages = {339--349},
publisher = {{IEEE} / {ACM}},
year = {2019}
}
-
Install the prerequisites:
- Install Docker - Why Docker?
- Install MongoDB - Why MongoDB? (Optional)
-
Clone the repository:
$ git clone https://github.com/BugSwarm/bugswarm.git -
Setup MongoDB:
Note: If you wish to use your own local MongoDB, skip to Step 4.
Select either of the options BugSwarm provides below:
Pulling the Docker Image of the BugSwarm MongoDB:
- Pull the image from our BugSwarm DockerHub repository:
$ docker pull bugswarm/images:bugswarm-db - Run & port the Docker container containing MongoDB:
$ docker run -it -p 27017:27017 -p 5000:5000 bugswarm-db - Move to step 4.
Create your own Docker Image of the BugSwarm MongoDB:
BugSwarm provides a Dockerfile to build a Docker image of MongoDB to port with the pipeline. Follow the steps below:
-
Depending on where you cloned the repository, change to the database directory:
$ cd ~/bugswarm/database -
Build the Docker Image with the tag as
bugswarm-dbfrom the Dockerfile located similarly to the above directory:$ docker build . -t bugswarm-db -
Run & port the Docker container containing MongoDB:
$ docker run -it -p 27017:27017 -p 5000:5000 bugswarm-dbNote: If multiple instances of MongoDB are running on the system, you must change the port accordingly. Please see the FAQ
-
Move to step 4.
- Pull the image from our BugSwarm DockerHub repository:
-
Mongo should now be up and running, test the connection by opening a new Terminal and use:
$ mongo -
Configure necessary credentials:
- Make a copy of the credentials file:
$ cp bugswarm/common/credentials.sample.py bugswarm/common/credentials.py - Fill in credentials in
bugswarm/common/credentials.py:DOCKER_HUB_REPO=<DOCKER_HUB_REPO> DOCKER_HUB_USERNAME=<DOCKER_HUB_USERNAME> DOCKER_HUB_PASSWORD=<DOCKER_HUB_PASSWORD> GITHUB_TOKENS=<GITHUB_TOKENS> DATABASE_PIPELINE_TOKEN=<DATABASE_PIPELINE_TOKEN> ('testDBPassword' if using Docker image of Mongo) COMMON_HOSTNAME=<LOCAL-IPADDRESS>:5000The following values are required for authentication, accessing components and APIs used within the BugSwarm pipeline. Please see the FAQ for details regarding the credentials.
- Make a copy of the credentials file:
-
Run the provision script:
$ ./provision.shThe
provision.shwill provision the environment to utilize the BugSwarm pipeline
BugSwarm mines builds from projects on GitHub that use Travis CI, a continuous integration service. We mine fail-pass build pairs such that the first build of the pair fails and the second, which is next chronologically in Git history on each branch, passes.
The Miner component consists of the Pair-Miner and Pair-Filter.
run_mine_project.sh: Mines job-pairs from a project given its repo-slug.
Usage: ./run_mine_project.sh -r <repo-slug> [OPTIONS]
<repo-slug> Repo slug of the project from which the job-pair was mined
OPTIONS:
-t, --threads Maximum number of worker threads to spawn. Defaults to 1.
-c, --component-directory The directory containing all the required BugSwarm components.
Example:
$ ./run_mine_project.sh -r Flipkart/foxtrot
The example will mine job-pairs from the "Flipkart/foxtrot" project. This will run through the Miner component of the BugSwarm pipeline. The output will push data to your MongoDB specified and outputs several .json files after each sub-step.
BugSwarm obtains the original build environment that was used by Travis CI, via a Docker image, and generate scripts to build and run regression tests for each build. We match the reproduced build log, which is a transcript of everything that happens at the command line during build and testing, with the historical build log from Travis CI. We do this five times to account for reproducibility and flakiness.
run_reproduce_project.sh: Reproduces all job-pairs mined from a project given its repo slug.
Usage: ./run_reproduce_project -r <repo-slug> [OPTIONS]
<repo-slug> Repo slug of the project
OPTIONS:
-t, --threads Maximum number of worker threads to spawn. Defaults to 1.
-c, --component-directory The directory containing all the required BugSwarm components.
Example:
$ ./run_reproduce_project -r "Flipkart/foxtrot" -c ~/bugswarm/
The example will attempt to reproduce all job-pairs mined from the "Flipkart/foxtrot" project. We add the "-c" argument to specify that "~/bugswarm/" directory contains the required BugSwarm components to run the pipeline sucessfully. If successful, metadata will be pushed to our specified MongoDB and the Artifact is pushed to the DockerHub repository we specified.
run_reproduce_pair.sh: Reproduces a single job-pair given the slug for the project from which the job-pair
was mined, the failed Job ID, and the passed job ID.
Usage: ./run_reproduce_pair.sh -r <repo-slug> -f <failed-job-id> -p <passed-job-id> [OPTIONS]
<repo-slug> Repo slug of the project
<failed-job-id> The failed job ID
<passed-job-id> The passed job ID
OPTIONS:
-t, --threads Maximum number of worker threads to spawn. Defaults to 1.
-c, --component-directory The directory containing all the required BugSwarm components.
Example:
$ ./run_reproduce_pair.sh -r Flipkart/foxtrot -f 433449696 - p 433455764 -t 2
The example above will take the repo-slug "Flipkart/foxtrot" and both failed/passed job id to reproduce through the Reproducer component of the pipeline. We use 2 threads to run the process. If successful, we push the Artifact to the DockerHub repository specified in the "credentials.py" file and push metadata to the MongoDB.
generate_pair_input.py: Generate job pairs from the given repo slug or file containing a list of repos. This allows
the user to be selective in which job pairs they'd want to reproduce through the optional argument filters. The output
will result as such: repo-slug, failing-job-id, and passing-job-id.
Usage: python3 generate_pair_input.py -r <repo-slug> -o <output-path> [OPTIONS]
<repo-slug> Repo slug of the project
<output-path> Path for the output
OPTIONS:
--include-attempted Include job pairs in the artifact database collection that we have already attempted to reproduce. Defaults to false.
--include-archived-only Include job pairs in the artifact database collection that are marked as archived by GitHub but not resettable. Defaults to false.
--include-resettable Include job pairs in the artifact database collection that are marked as resettable. Defaults to false.
--include-test-failures-only Include job pairs that have a test failure according to the Analyzer. Defaults to false.
--classified-build Restrict job pairs that have been classified as build according to classifier Defaults to false.
--classified-code Restrict job pairs that have been classified as code according to classifier Defaults to false.
--classified-test Restrict job pairs that have been classified as test according to classifier Defaults to false.
--classified-exception Restrict job pairs that have been classified as contain certain exception
--build-system Restricted to certain build system
--os-version Restricted to certain OS version(e.g. 12.04, 14.04, 16.04)
Example:
$ python3 generate_pair_input.py --repo stormpath/stormpath-sdk-java --include-resettable --include-test-failures-only --include-archived-only --classified-code --classified-exception NullPointerException -o /home/user/results_output.txt
The example above will include job pairs that were previously attempted to reproduce from the Artifact database collection, among those job pairs we include only those that have test failure according to the Analyzer, marked as resettable, and finally we restrict the job pairs further to those that were classified with having the "NullPointerException".
What credentials do I input?
DOCKER_HUB_REPO- The DockerHub repository that will hold Docker Images pushed by the BugSwarm Reproducer.DOCKER_HUB_USERNAME- This is the username credential being used by the DockerHub API to access theDOCKER_HUB_REPO.DOCKER_HUB_PASSWORD- This is the password credential being used by the DockerHub API to access theDOCKER_HUB_REPO.GITHUB_TOKENS- A GitHub Access Token to perform Git Operations over HTTPS via the Git API (used for Mining projects)DATABASE_PIPELINE_TOKEN- The token of a user's account used to access MongoDB. ('testDBPassword' if using Docker image of Mongo)COMMON_HOSTNAME- :5000, this hostname is used to integrate the API usage with your local database.
BugSwarm still using old credentials input?
In the case where you modify your credentials under the common/credentials.py file, but ran the provision.sh
script previously, the BugSwarm package will still retain the old values. You would need to uninstall the package and
run the provision.sh script once more.
Have multiple instances of MongoDB Running?
If you have an existing MongoDB instance running on your machine, it's most likely utilizing the default port 27017.
In the case where you would want to use our provided Dockerfile for the database you must change the port in a few spots.
For example, lets use port 27020 when running the Docker image of the database, the command would be:
$ docker run -it -p 27020:27017 -p 5000:5000 bugswarm-db (Note the change in the first -p argument)
So now when connecting to this instance of Mongo, the command would be:
$ mongo --port 27020
In the case where the second -p argument for port 5000 is used, our BugSwarm pipeline API port, we can also map to a
different port as follows:
$ docker run -it -p 27017:27017 -p 5002:5000 bugswarm-db (Note the change in the second -p argument)
This port will now be set under the common/credentials.py file as:
COMMON_HOSTNAME=<LOCAL-IPADDRESS>:5002
If you have followed these steps, resume at #4 of Setting up BugSwarm
Why do we use Docker?
Docker is lightweight in comparison to Virtual Machines (VMs). The virtualization environment is interchangeable with VMs. In principle, Travis CI creates and retains a base Docker image which is the exact build environment.
Why do we use MongoDB?
MongoDB is an object-oriented, scalable and dynamic NoSQL database. The data is stored as JSON or BSON documents inside a collection. The use of high performance, availability, and scaling provides easy integration thus satisfying the BugSwarm needs.