This repository contains the implementation of our Heterogeneous Multi-output Gaussian Process (HetMOGP) model. The entire code is written in Python and connected with the GPy package, specially useful for Gaussian processes. Our code consists of two main blocks:
- hetmogp: This block contains all model definitions, inference, and important utilities.
- likelihoods: General library of probability distributions for the heterogeneous likelihood construction.
Our tool is a novel extension of multi-output Gaussian processes for handling heterogeneous outputs (from different statistical data-types). The following distributions are already available to be used: [Gaussian, Bernoulli, Heteroscedastic Gaussian, Categorical, Exponential, Gamma, Beta]. We expect to upload Student, Poisson, Ordinal and Dirichlet distributions code as soon as possible. If you want to contribute and include a new likelihood function, please follow the instructions given below to add your new script to the likelihoods module.
Please, if you use this code, cite the following paper:
@article{MorenoArtesAlvarez18,
title={Heterogeneous Multi-output {G}aussian Process Prediction},
author={Pablo Moreno-Mu\~noz, Antonio Art\'es-Rodríguez and Mauricio A. \'Alvarez},
journal={arXiv preprint arXiv:1805.07633},
year={2018}
}
Our Python implementation follows a straightforward sintaxis where you only have to define a list of input and output values, build the heterogeneous likelihood with the desired distributions that you need and call directly to the model class. That is
- Output and input data definition:
Y = [Y_hg, Y_ber, Y_cat]
X = [X_hg, X_ber, X_cat]
- Heterogeneous Likelihood definition:
likelihood_list = [HetGaussian(), Bernoulli(), Categorical(K=3)]
- Model and definition:
model = SVMOGP(X=X, Y=Y, Z=Z, kern_list=kern_list, likelihood=likelihood, Y_metadata=Y_metadata)
A complete example of our model usage can be found in this repository at notebooks > demo
The heterogeneous likehood structure (based on Eero Siivola's GPy release and GPstuff) permits to handle mixed likelihoods with different statistical data types in a very natural way. The idea behind this structure is that any user can add his own distributions easily by following a series of recommendations:
- Place your new_distribution.py under the likelihood directory.
- Define the logpdf, first order dlogp_df and second order derivatives d2logp_df2 of your log-likelihood function.
- Use var_exp and var_exp_derivatives for approximating integrals with Gauss-Hermite quadratures.
- Code your predictive and get_metadata methods to have all available utilities.
-
Missing Gap Prediction: Predicting in classification problems with information obtained from parallel regression tasks.
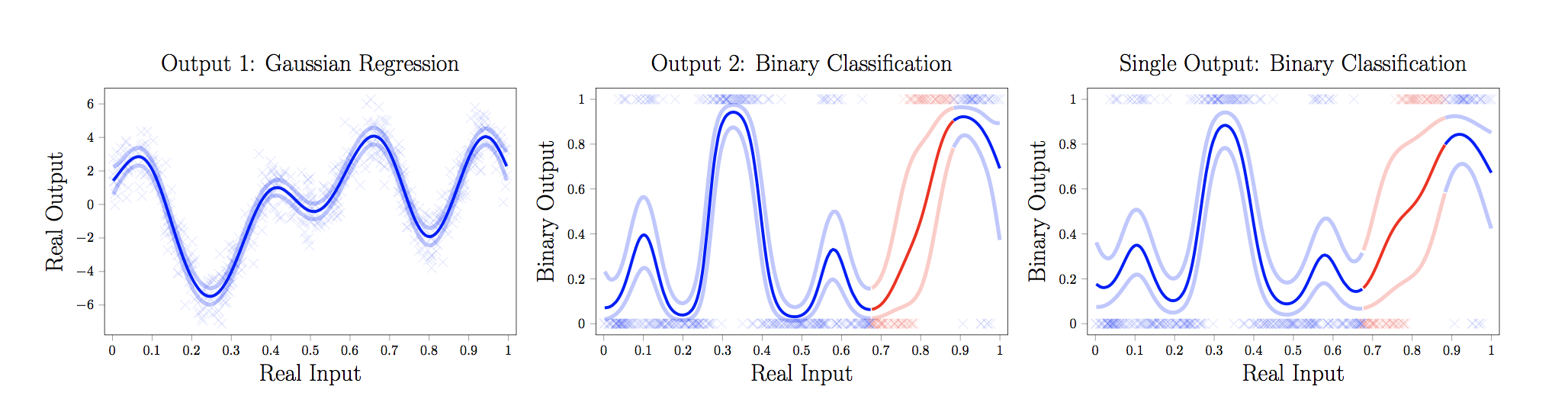
-
London House Prices: Spatial modeling with heterogeneous samples. This is a demographic example where we mix discrete data (type of house) with real observations (log-price of house sale contracts).
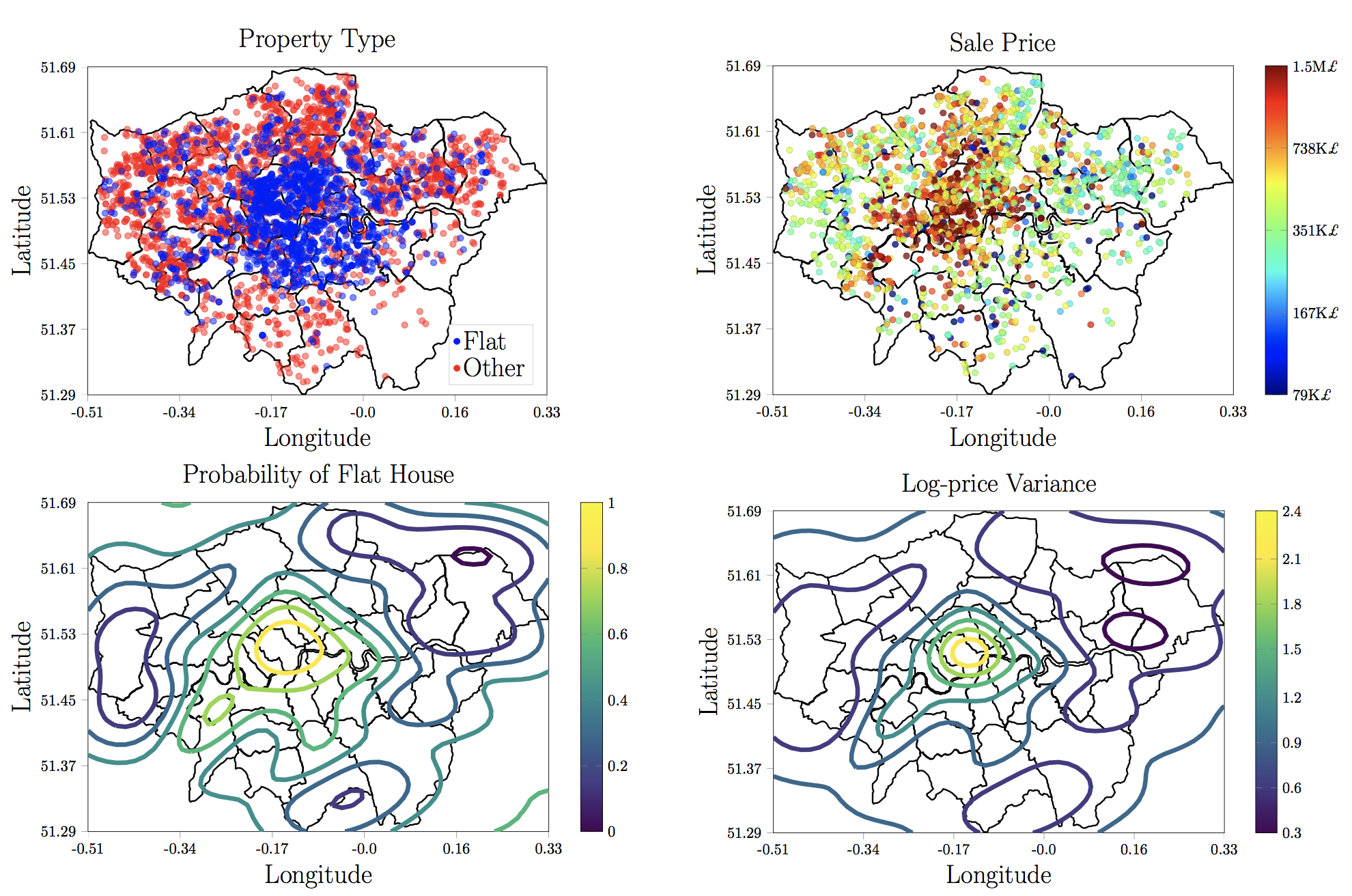


Pablo Moreno-Muñoz, Antonio Artés-Rodríguez and Mauricio A. Álvarez
For further information or contact:
pmoreno@tsc.uc3m.es