- Sobre o Projeto
- Início
- Uso
- Roadmap
- Estratégia de deployment
- Mapa dos arquivos
- Bases de dados no MongoDB
- Análises
- Contribuição
- Licença
- Contato
- Reconhecimentos
Projeto para cumprimento de tarefa desafio definida pelo processo de seleção da empresa Oncase Intelligence Consulting. O projeto consiste em desenvolver um processo de web crawling para estruturar dados de portais concorrentes de notícias, agregar métricas sobre essesdados e disponibilizar as informações.
O tema escolhido nesse projeto é o de tecnologia, agregaremos então as notícias de três portais: OlharDigital, CanalTech e GizModo.
Para que possamos dar início à aquisição dos dados, será necessário o cumprimento das seguintes etapas explicadas abaixo.
Primeiramente teremos de configurar o MongoDB para que possamos usa-lo.
brew tap mongodb/brew
brew install mongodb-community@4.2
brew services start mongodb-community@4.2- Para mais informações sobre como instalar o MongoDB no MacOS.
- Clone o repositório
git clone https://github.com/anderson93/oncase-scrapper-challenge.git- Instalação dos pacotes do Python 3.7.4:
pip3 install -r requirements.txt- Após as instalações dos pré-requisitos das seções anteriores, para executar a aplicação basta:
./start.sh- Iniciar-se-á a aplicação e deve-se informar, caso desejar iniciar com cold start, que significa limpando previamente a DB chamada
tech_newsdo servidor MongoDB, caso já exista.
######################################################################
######################################################################
Scrapper Oncase Challenge
######################################################################
######################################################################
O objetivo deste projeto é a execução processo de web crawling
paraestruturar dados de portais concorrentes de notícias, agregar
métricas sobre essesdados e disponibilizar informações.
Iremos agora iniciar os processos, portanto é então necessário
saber algumas informações.
Deseja um começo cold start (realizarei um drop caso já exista a base
tech_news e eliminarei também os logs da pasta)?
Y ou n:- É então perguntado quantas páginas de cada portal serão crawladas para se obter os links, para que então posteriormente sejam scrappeadas.
Quantas páginas das notícias do portal OlharDigital você deseja: [número de páginas]
E agora do CanalTech: [número de páginas]
E para finalizar, GizModo: [número de páginas]- Quando a aplicação finalizar, aparecerá a mensagem abaixo e todos os dados estarão no MongoDB.
Links do OlharDigital capturados! 1/3
Links do CanalTech capturados! 2/3
Links do GizModo capturados! 3/3
Páginas do OlharDigital capturadas! 1/3
Páginas do CanalTech capturadas! 2/3
Páginas do GizModo capturadas! 3/3
######################################################################
######################################################################
JOB DONE!
######################################################################
######################################################################Veja a seção open issues para uma lista de melhorias sugeridas e problemas/bugs conhecidos.
Existe também o log de trabalho disponível.
Algumas estratégias podem ser tomadas para o deployment dessa aplicação em produção, mas que dependem de algumas características do projeto.
Cada spider é uma classe definida pelo Scrapy que permite que seja definido as ações a serem tomadas quando se realiza o request no site, sejam ações de scrapping ou de crawling. Em um ambiente de produção, é possível construir mais spiders para diferentes sites e a abordagem do problema continuará a mesma.
O scrapy possue uma gama de configurações que nos permitem realizar enriquecimento de base de forma mais contínua e progressiva. Alguns problemas que podem existir seriam limites de requests, bloqueio de IP, bloqueio por falta de header http, entre outros. Algumas das configurações são: delay do request, delay aleatório do request, inclusão de header do navegador, uso de cookies, etc. Isso é importante no ambiente de produção, pois torna a aplicação mais resiliente.
Como a aplicação possui um drop de itens duplicados na base, é possível executar a aplicação em diferentes máquinas que compartilhem do mesmo backend, assim em projetos maiores podemos nos utilizar de diversas máquinas e portanto diversos IPs diferentes (evitando bloqueios de IP), mas o enriquecimento da base ocorrerá sem duplicados.
A escolha do framework Scrapy foi também dada graças a estrutura de pipeline do mesmo, pois assim ele consegue devolver os dados scrapeados para vários backends diferentes, assim o projeto tanto pode ser iniciado em um MongoDB (como nesta versão), como também além do MongoDB ele pode exportar os dados para outras fontes externas, como o sistema de arquivos local ou FTP, S3 e além desses, é possível também fazer a exportação através do Python, o que abre um leque de possibilidades.
Através do próprio scrapy, também é possível algumas estratégias de monitoramento das tarefas das Spiders, como por exemplo mensagem de status via e-mail, bot do telegram ou notificação via slack. As notificações podem ser a partir de qualquer natureza, como: motor iniciado, motor parado, itens scrappeados, itens droppados, erros dos itens, spider aberta, spider fechada, spider ociosa, erro de spider, requests agendados, requests droppado, requests recebido, requests baixado; dentre outros.
Existem duas bibliotecas que foram criadas com o objetivo de tornar o deployment das Spiders mais fácil. A primeira delas se chama Scrapyd. Essa biblioteca, funciona todos os requests de processos do scrapy, assim os administrando e os alocando em múltiplos processos em paralelo. Além disso, ele fornece uma interface de comunicação e agendamento de Spiders, que na metáfora da biblioteca se chamam eggs (filhote de aranha, lol), que podem ser uppados através da porta da biblioteca e serão chocados (lançados) no momento agendado. Essas implementações disponíveis através do Scrapyd, permite que as Spiders sejam controladas remotamente e portanto serem implantadas em clusters, o que abre espaço para a segunda biblioteca chamada ScrapydWeb.
A ScrapydWeb, é uma aplicação web que permite monitoramento, visualização e análise de logs. Através dessa biblioteca, é possível controlar as spiders ativas, agendar através de uma interface web entre algumas outras funções já descritas aqui, mas agora com uma UI amigável e assim possível a configuração, deployment, agendamento, execução de comandos em multinodes e tudo através da interface web. É possível também, conectar a outros clusters através do ponto de comunicação gerado pelo Scrapyd, e assim controla-los e monitora-los remotamente, todas as informações agregadas em apenas uma página web.
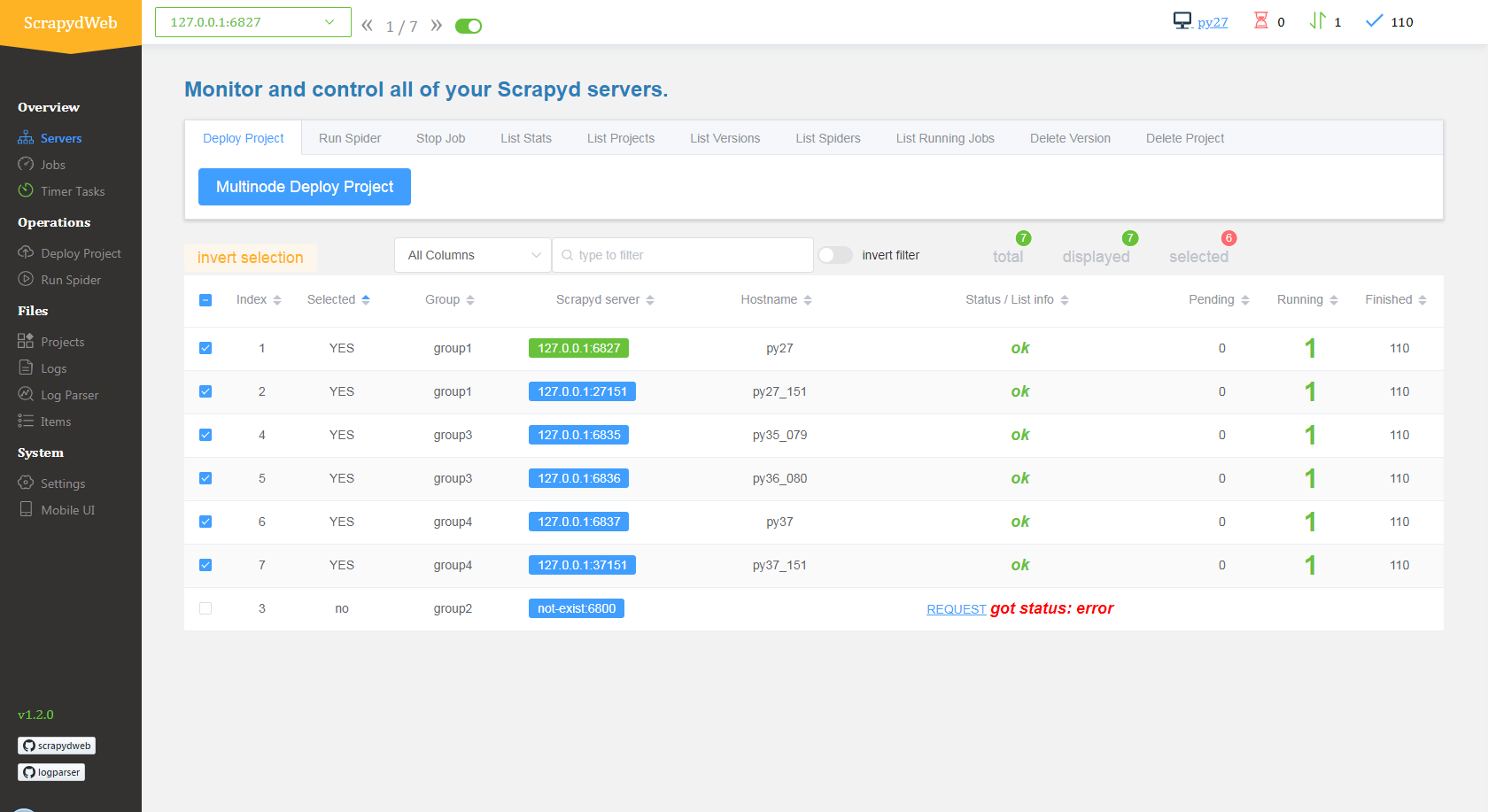
.
├── LICENSE
├── README.md
├── drop_tech_db.py -> Script em python para droppar a base em caso de cold start
├── requirements.txt -> Dependências necessárias do python
├── start.sh -> Script para uso do programa
└── techcrawlers
├── logs -> Pasta de saída dos logs
├── scrapy.cfg -> Arquivo de configuração do Scrapy
└── techcrawlers
├── __init__.py
├── items.py -> Configurações da estrutura da saída dos arquivos
├── middlewares.py -> Definições dos modelos dos requests
├── mongo_connector.py -> Arquivo auxiliar para conexão com o MongoDB
├── pipelines.py -> Configuração dos backends
├── settings.py -> Configurações de variáveis do Scrapy
└── spiders
├── CanalTech.py -> Spider para captura de notícias
├── CanalTechLinks.py -> Spider para captura dos links das notícias
├── GizModo.py -> Spider para captura de notícias
├── GizModoLinks.py -> Spider para captura dos links das notícias
├── OlharDigital.py -> Spider para captura de notícias
├── OlharDigitalLinks.py -> Spider para captura dos links das notícias
└── __init__.pyComo saída será criada o banco de dados tech_news no MongoDB.
Dentro do banco de dados, haverão coleções, que serão criadas:
gizmodo-links-------> Detém os links de notícias do site GizModo.olhardigital-links--> Detém os links de notícias do site OlharDigital.canaltech-links-----> Detém os links de notícias do site CanalTech.news_data-----------> Detém as notícias scrappeadas dos sites OlharDigital, CanalTech e GizModo.
- Afim de complementar com mais informações, é possível treinar um classificador de notícias que sugira mais tags para um texto, assim é possível complementar mais informações das notícias ao longo dos sites.
- Existem casos de uso da análise de sentimentos em notícias, para predição de comportamentos de compras em diversos setores, afim de melhorar a predição dos dados através de fontes externas.
- Não foi possível adquirir informações sobre engajamento nas páginas, devido ao plugin do Facebook, então uma forma de encontrar dados sobre engajamento, seria pegar através do feed do twitter os links das notícias e atualiza-las no MongoDB utilizando a url (que presumidamente é única no site). O Scrapy tem ferramentas para capturar a url mesmo depois de redirecionamentos, como por exemplo o uso de encurtadores de links como tinyurl e etc.
- Com esses dados também seria possível identificar os melhores horários para serem postados específicas notícias sobre dados assuntos, afim de que a eficiência no engajamento seja máxima dada a categoria do texto.
Contribuições é o que faz a comunidade open source forte e um maravilhoso ambiente para aprender, se insipirar e criar. Quaisquer contribuições serão efusivamente bem vindas.
- Fork o projeto
- Crie seu ramo (
git checkout -b feature/FabulosoFeature) - Dê commit nas suas melhorias (
git commit -m 'Adicionando Fabulosidade') - Dê push para o ramo (
git push origin feature/FabulosoFeature) - Abra um Pull request!
- ???
- Profit!
Distribuída sob a licença MIT. Veja LICENSE para mais informações.
Anderson Henrique de Oliveira Conceição - email
Link do projeto: https://github.com/anderson93/oncase-scrapper-challenge
- Obrigado a Oncase por me fornecer essa oportunidade de demonstrar um pouco do meu conhecimento através deste desafio.
- Agradeço também a comunidade Open-Source sem a qual jamais estaríamos desenvolvendo tecnologia e soluções a nivel industrial tão facilmente.