Official code for the paper "TabEBM: A Tabular Data Augmentation Method with Distinct Class-Specific Energy-Based Models", published in the Thirty-Eighth Annual Conference on Neural Information Processing Systems (NeurIPS 2024).
Authored by Andrei Margeloiu, Xiangjian Jiang, Nikola Simidjievski, Mateja Jamnik, University of Cambridge, UK

TL;DR: We introduce a new data augmentation method for tabular data, which is fast, requires no additional training, and can be applied to any downstream predictors model.
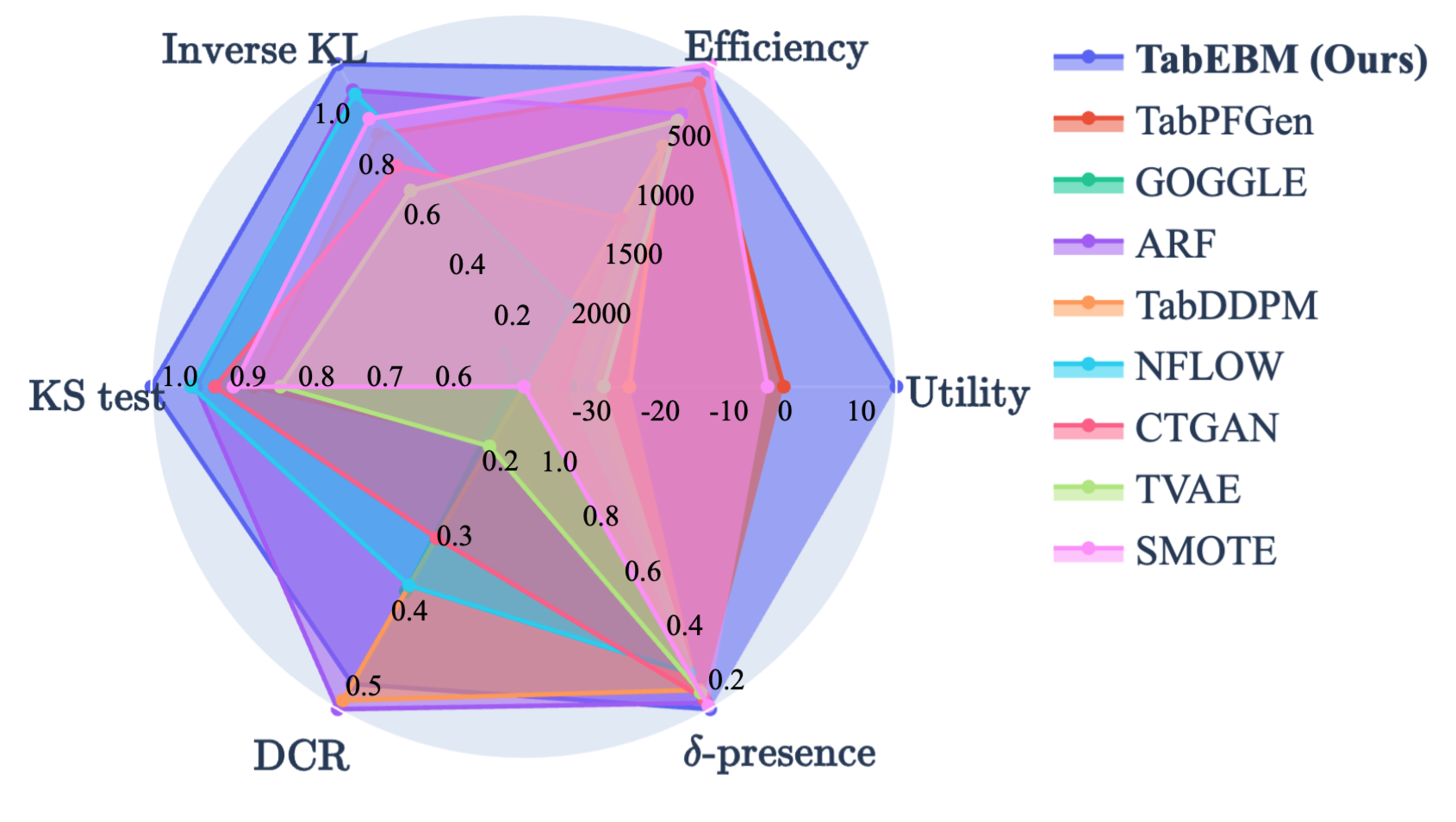
Abstract: Data collection is often difficult in critical fields such as medicine, physics, and chemistry. As a result, classification methods usually perform poorly with these small datasets, leading to weak predictive performance. Increasing the training set with additional synthetic data, similar to data augmentation in images, is commonly believed to improve downstream classification performance. However, current tabular generative methods that learn either the joint distribution p(x,y) p(\mathbf{x}, y) or the class-conditional distribution p(x∣y) p(\mathbf{x} \mid y) often overfit on small datasets, resulting in poor-quality synthetic data, usually worsening classification performance compared to using real data alone. To solve these challenges, we introduce TabEBM, a novel class-conditional generative method using Energy-Based Models (EBMs). Unlike existing methods that use a shared model to approximate all class-conditional densities, our key innovation is to create distinct EBM generative models for each class, each modelling its class-specific data distribution individually. This approach creates robust energy landscapes, even in ambiguous class distributions. Our experiments show that TabEBM generates synthetic data with higher quality and better statistical fidelity than existing methods. When used for data augmentation, our synthetic data consistently improves the classification performance across diverse datasets of various sizes, especially small ones.
For attribution in academic contexts, please cite this work as:
@article{margeloiu2024tabebm,
title={TabEBM: A Tabular Data Augmentation Method with Distinct Class-Specific Energy-Based Models},
author={Andrei Margeloiu and Xiangjian Jiang and Nikola Simidjievski and Mateja Jamnik},
journal={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
}
TabEBM.pycontains (i) the implementation of TabEBM, and (ii) a helper functionplot_TabEBM_energy_contourto show the energy contour (or unnormalized probability) approximated by TabEBMTabEBM_approximated_density.ipynbshows the TabEBM approximation of the density of the real data distributionTabEBM_generate_data.ipynbshows how to generate data using TabEBM
pip install tabebm
- Create
condaenvironment
conda create -n tabebm python=3.10.12
conda activate tabebm
- Install tabebm and dependencies
git clone https://github.com/andreimargeloiu/TabEBM
cd TabEBM/
pip install --no-cache-dir -r requirements_paper.txt
pip install .
-
Tutorial 1: Generate synthetic data with TabEBM
-
The library can generate synthetic data with three lines of code.
from tabebm.TabEBM import TabEBM tabebm = TabEBM() augmented_data = tabebm.generate(X_train, y_train, num_samples=100) # Output: # augmented_data[class_id] = numpy.ndarray of generated data for a specific ’’class_id‘‘
-
-
-
The library allows computation of TabEBM’s energy function and the unnormalised data density.
from tabebm.TabEBM import plot_TabEBM_energy_contour X, y = circles_dataset(n_samples=300, noise=2) plot_tabebm_probabilities(X, y, title_prefix='(noise=2)', h=0.2) plt.show()
-
-
- We provide a minimal example of using TabEBM to augment a real-world datasets for improvied downstream performance.