Цель проекта: посмотреть на разные подходы для хранения time-series данных, используя sql или no-sql, или же специализированное решение. При этом, интересно оценить перфоманс для вычисления разных агрегаций, и то, как можно решить задачу средствами данной СУБД путем вычисления простых аналитических запросов.
Для того, чтобы поднять проект необходимо установить docker-compose и воспользоваться следующей командой
docker compose up --build -dДалее нужно создать логин для Influx DB, зарегистрировавшись по адресу localhost:8086, получить токен и стандартный бакет quotes_trades и организацию.
Далее данные переменные необходимо указать в .env файле
INFLUXDB_V2_TOKEN=<your_token>
INFLUXDB_V2_ORG=<your_organisation>
INFLUX_BUCKET=quotes_trades
Теперь можно перезагрузить контейнеры
docker compose down
docker compose up --build -d
После этого можно загрузить данные, запустив скрипт в dataloading
docker exec -it dataloading python /code/scripts/load_data_dbs.pyИзмерить перфоманс можно воспользовашись скриптом
docker exec -it dataloading python /code/scripts/measure_time.pyВ случае ошибок можно посмотреть на логи с помощью команды
docker compose logs -f
Данные устроены очень просто - это записи высокочастотных торгов (точность вплоть до наносекунд) т. н. trades и quotes для различных тикеров по дням. Схема выглядит следующим образом.
Требуется максимально быстро отвечать на различные аналитические запросы.

- TIMESTAMP - время продажи trades или обновления quotes
- OMDSEQ - уникальный идентификатор, задающий порядок, в случае если timestamp'ы совпадают
- SYMBOL - имя тикера
- ASK_SIZE - это количество ценной бумаги, которую маркет-мейкер предлагает продать по цене спроса
- BID_SIZE - это количество ценной бумаги, которую маркет-мейкер предлагает купить по цене предложения
- ASK_PRICE - цена спроса
- BID_PRICE - цена предложения
- PRICE - цена сделки
- SIZE - размер сделки
Я использую GPC instance на ssd
| config | value |
|---|---|
| Machine type | n2-standard-4 |
| vCPU | 4 |
| Memory | 16Gb |
| Storage | 150Gb SSD persistent disk |
- Вычисление The Lee–Ready algorithm, примеры других алгоритмов доступны здесь
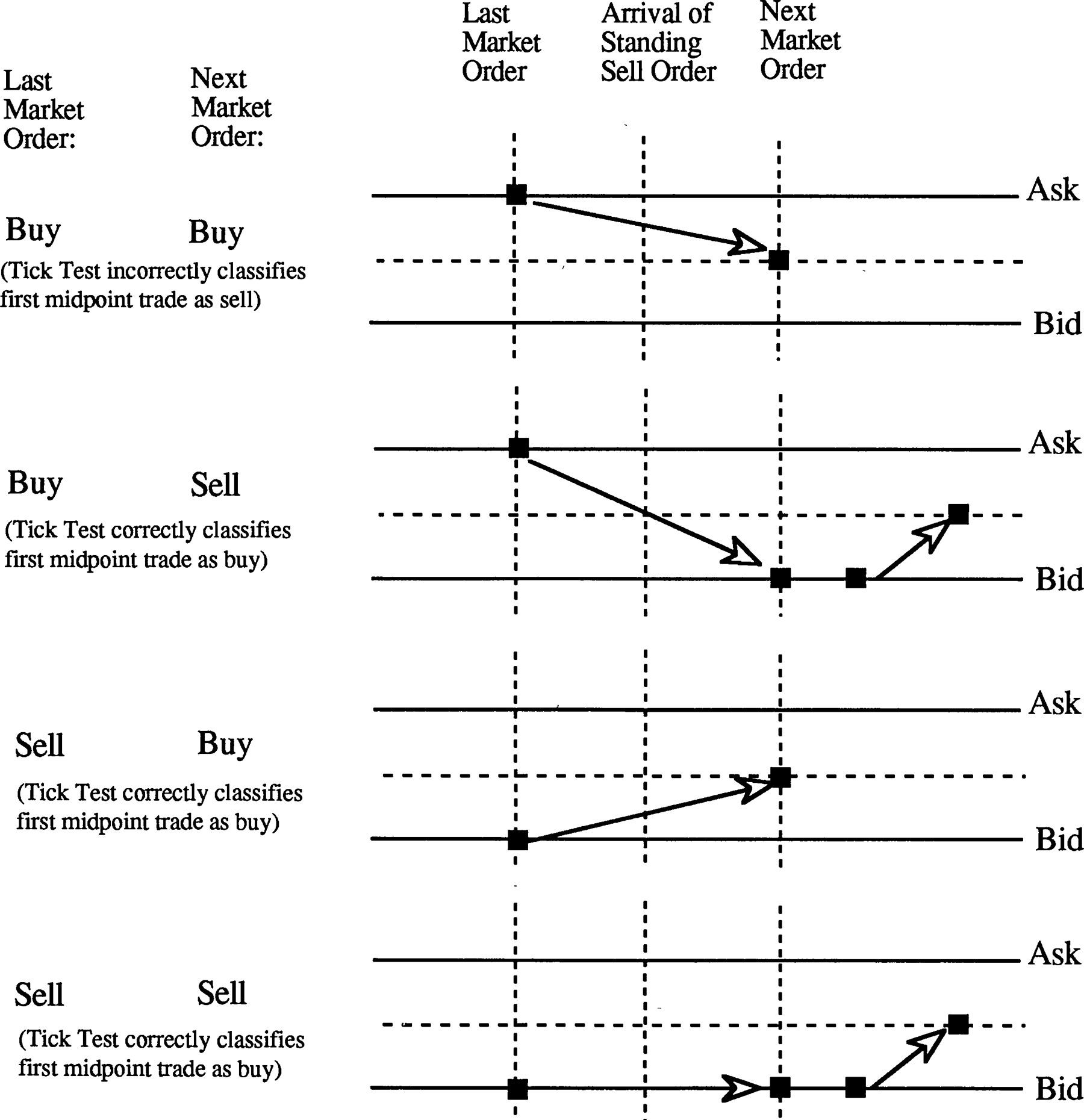 Classifying trades bracketed by price continuations.
Classifying trades bracketed by price continuations.

LAST_MID_PRICE -> (ASK_PRICE + BID_PRICE) / 2 # at time of last quote tick before given trade
LAST_PRICE -> PRICE # at time of previous trade
if PRICE > LAST_MID_PRICE:
SIDE = 1
elif PRICE < LAST_MID_PRICE:
SIDE = -1
else:
if PRICE > LAST_PRICE:
SIDE = 1
elif PRICE < LAST_PRICE:
SIDE = -1
else:
SIDE = 0- Агрегации: средняя price/mid price за один день
Все вычисления должны быть сделаны group by SYMBOL. Данные в базы могут быть загружены с помощью скрипта. При этом пример исходных файлов лежит в директории data.
Количечество записей в тестовом датасете было 20,225,508 в trades, и 396,613,627 в quotes
В качестве SQL решения использую PostgresSQL. И схема двух таблиц quotes и trades приведена выше.
CREATE TABLE IF NOT EXISTS quotes (
SYMBOL char(20) NOT NULL,
TIME timestamp NOT NULL,
OMDSEQ bigint NOT NULL,
ASK_SIZE double precision,
ASK_PRICE double precision,
BID_SIZE double precision,
BID_PRICE double precision,
PRIMARY KEY (TIME, OMDSEQ, SYMBOL)
);
CREATE TABLE IF NOT EXISTS trades (
SYMBOL char(20) NOT NULL,
TIME timestamp NOT NULL,
OMDSEQ bigint NOT NULL,
SIZE double precision,
PRICE double precision,
PRIMARY KEY (TIME, OMDSEQ, SYMBOL)
);При этом я создаю индекс для поля SYMBOL, поскольку частыми операциями являются группировки по этому полю, либо же join'ы.
CREATE INDEX idx_trades ON trades(SYMBOL);
CREATE INDEX idx_quotes ON quotes(SYMBOL);Загрузка данных за 1 день заняла примерно 8 часов 11 минут.
SELECT
symbol, AVG((ask_price + bid_price)/2) AS mid_price
FROM
quotes
GROUP BY
symbol;Среднее время работы данной квери для dataset'a на 396,613,627 кортежей занимает 4 минуты.
Существует расширение для Postgres DB, которое улучшает работу с временными данными Timescale, но я не проверял насколько оно ускоряет работу
В качесте базы No-SQL используется MongoDB.
Создано две коллекции:
- quotes с записями из файла .*_qte.csv
- trades с записями из файла .*_trd.csv
db.quotes.aggregate([
{
$addFields: {
sum_price: { $add: ['$ask_price', '$bid_price'] }
}
},
{
$addFields: {
mid_price: { $multiply: ["$sum_price", 0.5] }
}
},
{
$group: {
_id: "$symbol",
avg: { $avg: "$mid_price"}
}
}
])Среднее время работы данной квери для dataset'a на 396,613,627 записей занимает примерно 15 минут.
Версия Mongo DB 5.0 содержит Time Series Collections, но я не проверял её работу
Используется база InfluxDB как самое наилучшее решение согласно рейтингу.
 DB-Engines Ranking of Time Series DBMS
DB-Engines Ranking of Time Series DBMS
ask_stream = from(bucket:"quotes_trades")
|> range(start: 0, stop: now())
|> filter(fn: (r) => r._measurement == "quotes" and r._field == "ask_price")
|> mean()
bid_stream = from(bucket:"quotes_trades")
|> range(start: 0, stop: now())
|> filter(fn: (r) => r._measurement == "quotes" and r._field == "bid_price")
|> mean()
join(tables: {ask: ask_stream, bid: bid_stream}, on: ["symbol"])
|> map(fn: (r) => ({symbol: r.symbol, _time: r._time,
mid_price: (r._value_ask + r._value_bid) / 2.0}))
|> yield()
Среднее время работы данной квери для dataset'a на 396,613,627 тиков занимает около минуты, что намного быстрее чем примеры выше.
Для анализа производительности были загружены данные за 1 день (csv-файлы размером 39Gb).
| Postgres | Mongo | Influx | |
|---|---|---|---|
data loading seq. (416,839,135 ticks) |
8h11m | 2h15m | 15h11m |
price average query (20,225,508 ticks) |
3.74s | 20.25s | 1.09s |
mid price average query (396,613,627 ticks) |
449.21s | 795.94s | 20.64s |
lee and ready query (416,839,135 ticks) |
TODO | TODO | TODO |
для кверей считалось среднее время за 5 запусков
- Иерархические данные временных рядов естественным образом сочетаются с реляционными таблицами
- Если временной ряд основан на транзакционных данных, то будет выгодно хранить временные ряды в той же базе данных для удобства проверки, перекрестных ссылок и т.д. Стоит попробовать готовые специализированные расширения, как Timescale
- Скорость обработки аналитических запросов выше, по крайней мере для out-of-the-box решения
- Запись (append) в базу выполняются быстро, поскольку нет нужды перестраивать индексы
- Отсутствие требования миграции баз при изменении схемы
- Более производительное готовое решение, потому с меньшей вероятностью можно создать неудобную схему