This repository includes the functions needed to run Contextual Event Segmentation as presented in our paper "Predicting Visual Context for Unsupervised Event Segmentation in Continuous Photo-streams."
Given a continuous stream of photos, we, as humans, would identify the start of an event if the new frame differs from the expectation we have generated. The proposed model is analogous to such intuitive framework of perceptual reasoning. CES consists of two modules:
- the Visual Context Predictor (VCP), an LSTM network that predicts the visual context of the upcoming frame, either in the past or in the future depending on the sequence ordering. An auto-encoder architecture is used to train VCP with the objective of reaching minimum prediction mse.
- the event boundary detector, that compares the visual context at each time-step given the frame sequence from the past, with the visual context given the sequence in the future.
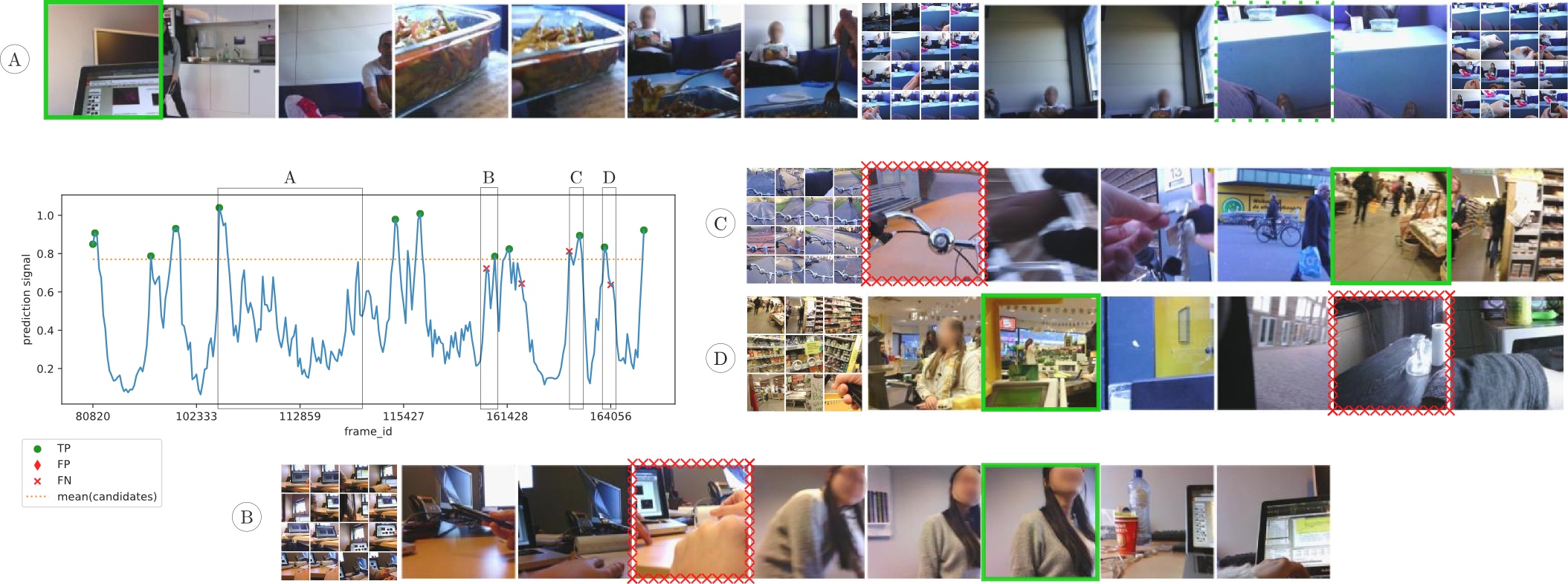
CES is able to ignore occasional occlusions as long as the different points of view span less frames than CES’ memory span (A). It is also capable of detecting boundaries that separate heterogeneous events such as riding a bike on the street and shopping at the supermarket (C, D). Most of the boundaries not detected by CES correspond to events that take place within the same physical space (B) and short transitions (C, D), e.g. parking the bike.
- Clone this repo, create a
test_datafolder within it, and extract this test lifelog and GT from EDUB-Seg to it. - Download the model architecture and weights here
- Change
PATH_VCPindemo.pyto match the location of your downloaded model architecture and weights. - Run
demo.py
The dataset used to train the model, as well as the model weights, can be found here.
If you want to execute CES on your own lifelogs (the images and ground truth, if available), just follow the instructions from this Wiki page
The Visual Context Predictor can be used for many applications, such as retrieval, activity detection from low time resolution videos, and summarization. Pointers to how to re-train it for your own data can be found in this Wiki page
The repository is organized as follows:
demo.py: full demo pipeline to test one sample data.__init__.py:class VCPto load, train and test the Visual Context Prediction model, withinit_modelandparams_VCPdefinition;prunning_SVMmodel; and training callbackEarlyStoppingTH.extraction_utils.py: methodVF_extractorto extract the visual features fromInceptionV3; functions to create the dataset from a folder of images and extract the visual features; functions to extract training and testing data for theprunning_SVMmodel.testing_utils.py: functions to extract the visual context from the testing data, find the event boundaries, and evaluate the event segmentation.
If you found this code or the R3 dataset useful, please cite the following publication:
@inproceedings{garcia2018predicting,
title={{Predicting Visual Context for Unsupervised Event Segmentation in Continuous Photo-streams}},
author={Garcia del Molino, Ana and Lim, Joo-Hwee and Tan, Ah-Hwee},
booktitle={2018 ACM Multimedia Conference on Multimedia Conference},
pages={10--17},
year={2018},
organization={ACM}
}