

A collection of academic articles, published methodology, and datasets on the subject of machine unlearning.
A sortable version is available here: https://awesome-machine-unlearning.github.io/
Please read and cite our paper:
Nguyen, T.T., Huynh, T.T., Nguyen, P.L., Liew, A.W.C., Yin, H. and Nguyen, Q.V.H., 2022. A Survey of Machine Unlearning. arXiv preprint arXiv:2209.02299.
@article{nguyen2022survey,
title={A Survey of Machine Unlearning},
author={Nguyen, Thanh Tam and Huynh, Thanh Trung and Nguyen, Phi Le and Liew, Alan Wee-Chung and Yin, Hongzhi and Nguyen, Quoc Viet Hung},
journal={arXiv preprint arXiv:2209.02299},
year={2022}
}
| Paper Title | Venue | Year |
|---|---|---|
| Machine Unlearning: Solutions and Challenges | arXiv | 2023 |
| Exploring the Landscape of Machine Unlearning: A Comprehensive Survey and Taxonomy | arXiv | 2023 |
| Machine Unlearning: A Survey | CSUR | 2023 |
| An Introduction to Machine Unlearning | arXiv | 2022 |
| Machine Unlearning: Its Need and Implementation Strategies | IC3 | 2021 |
| Making machine learning forget | Annual Privacy Forum | 2019 |
| “Amnesia” - A Selection of Machine Learning Models That Can Forget User Data Very Fast | CIDR | 2019 |
| Humans forget, machines remember: Artificial intelligence and the Right to Be Forgotten | Computer Law & Security Review | 2018 |
| Algorithms that remember: model inversion attacks and data protection law | Philosophical Transactions of the Royal Society A | 2018 |
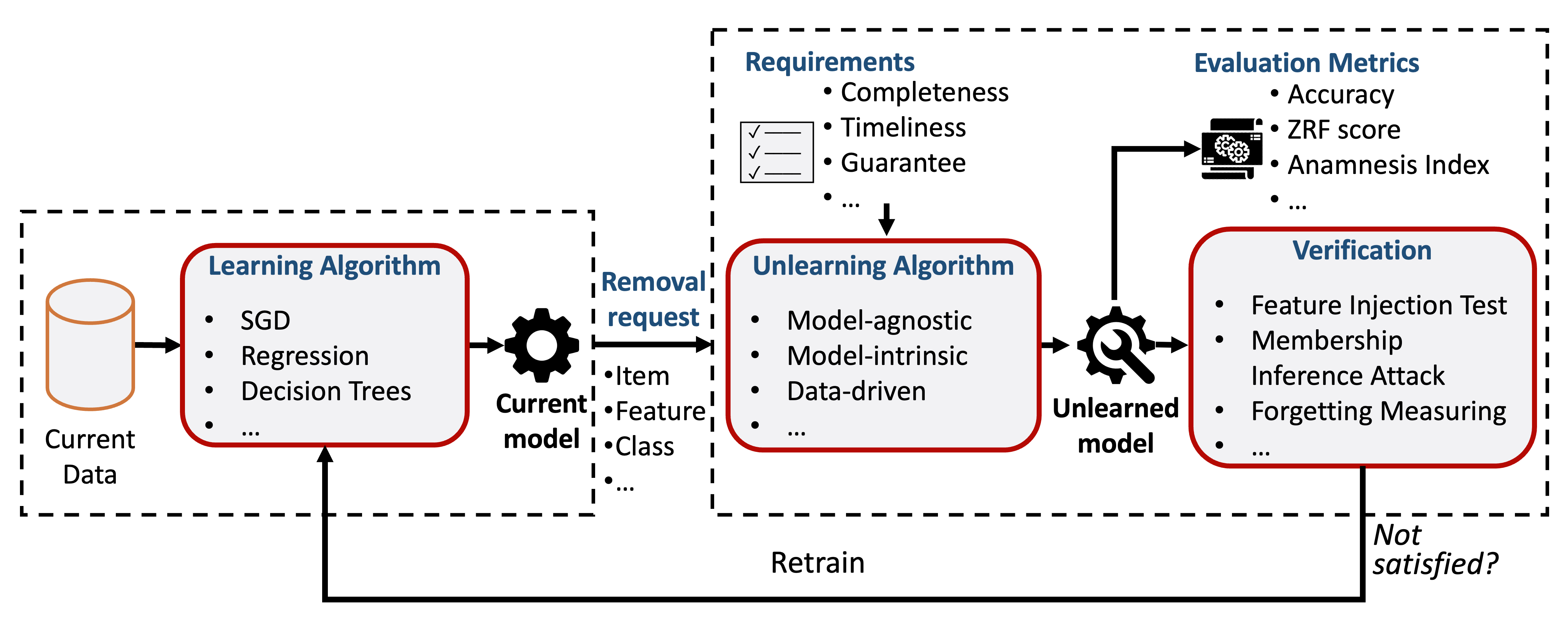
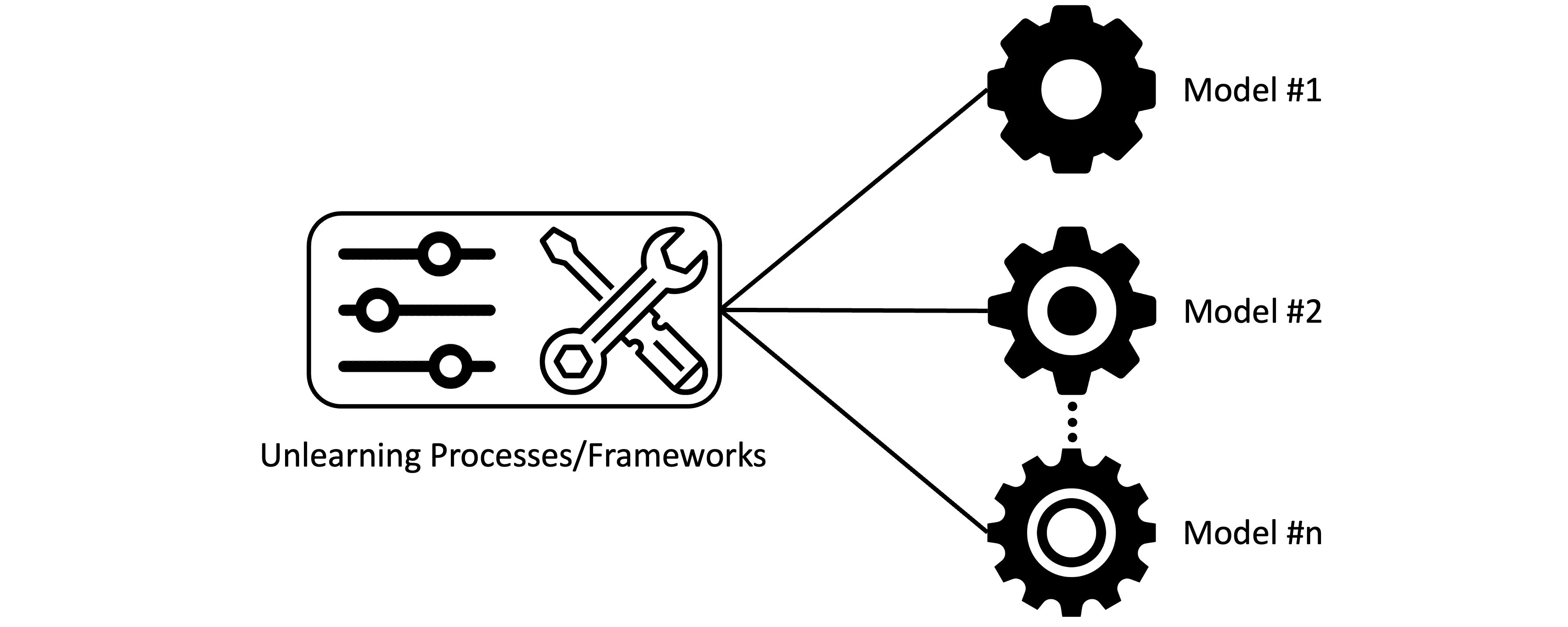 Model-agnostic machine unlearning methodologies include unlearning processes or frameworks that are applicable for different models. In some cases, they provide theoretical guarantees for only a class of models (e.g. linear models). But we still consider them model-agnostic as their core ideas are applicable to complex models (e.g. deep neural networks) with practical results.
Model-agnostic machine unlearning methodologies include unlearning processes or frameworks that are applicable for different models. In some cases, they provide theoretical guarantees for only a class of models (e.g. linear models). But we still consider them model-agnostic as their core ideas are applicable to complex models (e.g. deep neural networks) with practical results.
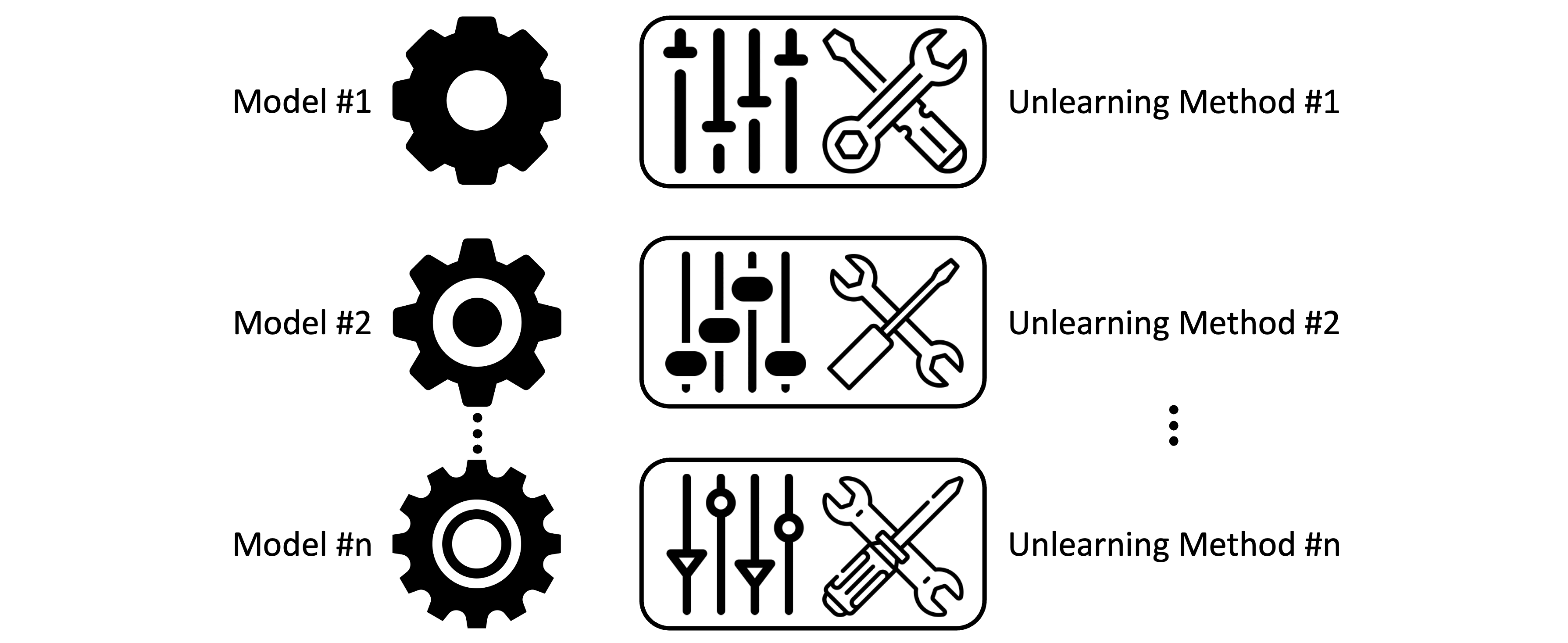 The model-intrinsic approaches include unlearning methods designed for a specific type of models. Although they are model-intrinsic, their applications are not necessarily narrow, as many ML models can share the same type.
The model-intrinsic approaches include unlearning methods designed for a specific type of models. Although they are model-intrinsic, their applications are not necessarily narrow, as many ML models can share the same type.
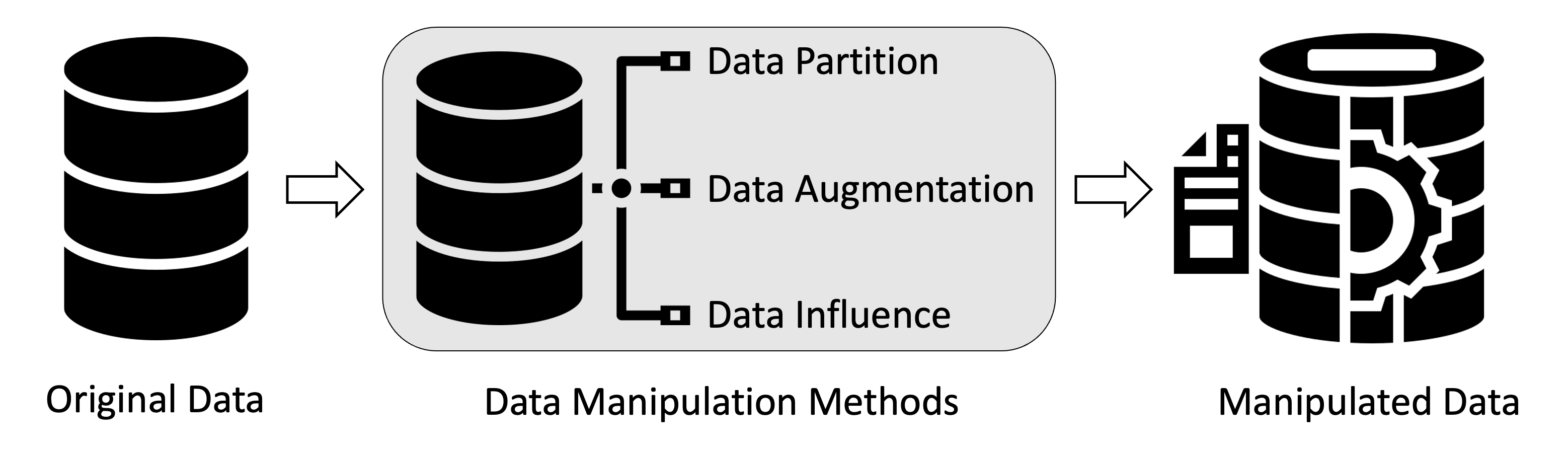 The approaches fallen into this category use data partition, data augmentation and data influence to speed up the retraining process. Methods of attack by data manipulation (e.g. data poisoning) are also included for reference.
The approaches fallen into this category use data partition, data augmentation and data influence to speed up the retraining process. Methods of attack by data manipulation (e.g. data poisoning) are also included for reference.
| Dataset | #Items | Disk Size | Downstream Application | #Papers Used |
|---|---|---|---|---|
| MNIST | 70K | 11MB | Classification | 29+ papers |
| CIFAR | 60K | 163MB | Classification | 16+ papers |
| SVHN | 600K | 400MB+ | Classification | 8+ papers |
| LSUN | 69M+ | 1TB+ | Classification | 1 paper |
| ImageNet | 14M+ | 166GB | Classification | 6 papers |
| Dataset | #Items | Disk Size | Downstream Application | #Papers Used |
|---|---|---|---|---|
| Adult | 48K+ | 10MB | Classification | 8+ papers |
| Breast Cancer | 569 | <1MB | Classification | 2 papers |
| Diabetes | 442 | <1MB | Regression | 3 papers |
| Dataset | #Items | Disk Size | Downstream Application | #Papers Used |
|---|---|---|---|---|
| IMDB Review | 50k | 66MB | Sentiment Analysis | 1 paper |
| Reuters | 11K+ | 73MB | Categorization | 1 paper |
| Newsgroup | 20K | 1GB+ | Categorization | 1 paper |
| Dataset | #Items | Disk Size | Downstream Application | #Papers Used |
|---|---|---|---|---|
| Epileptic Seizure | 11K+ | 7MB | Timeseries Classification | 1 paper |
| Activity Recognition | 10K+ | 26MB | Timeseries Classification | 1 paper |
| Botnet | 72M | 3GB+ | Clustering | 1 paper |
| Dataset | #Items | Disk Size | Downstream Application | #Papers Used |
|---|---|---|---|---|
| OGB | 100M+ | 59MB | Classification | 2 papers |
| Cora | 2K+ | 4.5MB | Classification | 3 papers |
| MovieLens | 1B+ | 3GB+ | Recommender Systems | 1 paper |
| Metrics | Formula/Description | Usage |
|---|---|---|
| Accuracy | Accuracy on unlearned model on forget set and retrain set | Evaluating the predictive performance of unlearned model |
| Completeness | The overlapping (e.g. Jaccard distance) of output space between the retrained and the unlearned model | Evaluating the indistinguishability between model outputs |
| Unlearn time | The amount of time of unlearning request | Evaluating the unlearning efficiency |
| Relearn Time | The epochs number required for the unlearned model to reach the accuracy of source model | Evaluating the unlearning efficiency (relearn with some data sample) |
| Layer-wise Distance | The weight difference between original model and retrain model | Evaluate the indistinguishability between model parameters |
| Activation Distance | An average of the L2-distance between the unlearned model and retrained model’s predicted probabilities on the forget set | Evaluating the indistinguishability between model outputs |
| JS-Divergence | Jensen-Shannon divergence between the predictions of the unlearned and retrained model | Evaluating the indistinguishability between model outputs |
| Membership Inference Attack | Recall (#detected items / #forget items) | Verify the influence of forget data on the unlearned model |
| ZRF score | The unlearned model should not intentionally give wrong output |
|
| Anamnesis Index (AIN) | Zero-shot machine unlearning | |
| Epistemic Uncertainty | if otherwise |
How much information the model exposes |
| Model Inversion Attack | Visualization | Qualitative verifications and evaluations |
Disclaimer
Feel free to contact us if you have any queries or exciting news on machine unlearning. In addition, we welcome all researchers to contribute to this repository and further contribute to the knowledge of machine unlearning fields.
If you have some other related references, please feel free to create a Github issue with the paper information. We will glady update the repos according to your suggestions. (You can also create pull requests, but it might take some time for us to do the merge)
