As analytics solutions have moved away from the one-size-fits-all model to choosing the right tool for the right function, architectures have become more optimized and performant while simultaneously becoming more complex. Solutions leveraging Amazon Redshift will often be used alongside services including AWS DMS, AWS AppSync, AWS Glue, AWS SCT, Amazon Sagemaker, Amazon QuickSight, and more. One of the core challenges of building these solutions can oftentimes be the integration of these services.
This solution takes advantage of the repeated integrations between different services in common use cases, and leverages the AWS CDK to automate the provisioning of AWS analytics services, primarily Amazon Redshift. Deployment is now customizing a JSON configuration file indicating the resources to be used, and this solution takes those inputs to auto-provision the required infrastructure dynamically.
PLEASE NOTE: This solution is meant for proof of concept or demo use cases, and not for production workloads.
This project leverages CloudShell, a browser-based shell service, to programmatically initiate the deployment through the AWS console. To achieve this, a JSON-formatted config file specifying the desired service configurations needs to be uploaded to CloudShell. Then, a series of steps need to be run to clone this repository and initiate the CDK scripts.
The following sections give further details of how to complete these steps.
Prior to deployment, some resources need to be preconfigured:
- Please verify that you will be deploying this solution in a region that supports CloudShell
- Execute the deployment with an IAM user with permissions to use:
- AWS CloudShell
- AWS Identity and Access Management (IAM)
- AWS CloudFormation
- Amazon SSM
- Amazon Redshift
- Amazon S3
- AWS Secrets Manager
- Amazon EC2
- AWS Database Migration Service (DMS)
- For a more granular list of permissions, please see here
- [OPTIONAL] If using SCT or JMeter, create a key pair that can be accessed (see the documentation on how to create a new one)
- [OPTIONAL] If using an external database, open source firewalls/ security groups to allow for traffic from AWS
If these are complete, continue to deployment steps. If you come across errors, please refer to the troubleshooting section -- if the error isn't addressed there, please submit the feedback using the Issues tab of this repo.
In order to launch the staging and target infrastructures, download the user-config-template.json file in this repo.
The structure of the config file has two parts: (1) a list of key-value pairs, which create a mapping between a specific service and whether it should be launched in the target infrastructure, and (2) configurations for the service that are launched in the target infrastructure. Open the user-config-template.json file and replace the values for the Service Keys in the first section with the appropriate Launch Value defined in the table below. If you're looking to create a resource, define the corresponding Configuration fields in the second section.
| Service Key | Launch Values | Configuration | Description |
|---|---|---|---|
vpc_id |
CREATE, existing VPC ID |
In case of CREATE, configure vpc:vpc_cidr: The CIDR block used for the VPC private IPs and sizenumber_of_az: Number of Availability Zones the VPC should covercidr_mask: The size of the public and private subnet to be launched in the VPC. |
[REQUIRED] The VPC to launch the target resources in -- can either be an existing VPC or created from scratch. |
redshift_endpoint |
CREATE, N/A, existing Redshift endpoint |
In case of CREATE, configure redshift:cluster_identifier: Name to be used in the cluster IDdatabase_name: Name of the databasenode_type: ds2.xlarge, ds2.8xlarge, dc1.large, dc1.8xlarge, dc2.large, dc2.8xlarge, ra3.xlplus, ra3.4xlarge, or ra3.16xlargenumber_of_nodes: Number of compute nodesmaster_user_name: Username to be used for Redshift databasesubnet_type: Subnet type the cluster should be launched in -- PUBLIC or PRIVATE (note: need at least 2 subnets in separate AZs)encryption: Whether the cluster should be encrypted -- y/Y or n/NloadTPCdata: Whether a sample TPC-DS dataset should be loaded into the new cluster -- Y/y or N/n |
Launching a Redshift cluster. |
dms_on_prem_to_redshift_target |
CREATE, N/A |
Can only CREATE if are also using a Redshift cluster. In case of CREATE,1. Configure dms_migration:migration_type: full-load, cdc, or full-load-and-cdcsubnet_type: Subnet type the cluster should be launched in -- PUBLIC or PRIVATE (note: need at least 2 subnets in separate AZs)2. Configure external_database:source_db: Name of source database to migratesource_engine: Engine type of the sourcesource_schema: Name of source schema to migratesource_host: DNS endpoint of the sourcesource_user: Username of the database to migratesource_port: [INT] Port to connect to connect on |
Creates a migration instance, task, and endpoints between a source and Redshift configured above. |
sct_on_prem_to_redshift_target |
CREATE, N/A |
Can only CREATE if are also using a Redshift cluster. In case of CREATE, configure other:key_name: EC2 key pair name to be used for EC2 running SCT (you don't need to configure the jmeter_node_type parameter) |
Launches an EC2 instance and installs SCT to be used for schema conversion. |
jmeter |
CREATE, N/A |
Can only CREATE if are also using a Redshift cluster. In case of CREATE, configure other:key_name: EC2 key pair name to be used for EC2 running JMeterjmeter_node_type: The EC2 node type to be used to run JMeter |
Launches an EC2 instance and installs JMeter to be used for load testing the Redshift cluster. |
You can see an example of a completed config file under user-config-sample.json.
Once all appropriate Launch Values and Configurations have been defined, save the file as the name user-config.json.
-
Open CloudShell
-
Clone the Git repository
git clone https://github.com/aws-samples/amazon-redshift-infrastructure-automation.git -
Run the deployment script
~/amazon-redshift-infrastructure-automation/scripts/deploy.sh -
When prompted

upload the completed user-config.json file

- When the upload is complete,

press the Enter key
- When prompted

input a unique stack name to be used to identify this deployment, then press the Enter key

input the region used for this deployment, then press the Enter key

input the CIDR of the on premise environment/ your IP address which needs access to the deployed resources, then press the Enter key
- Depending on your resource configuration, you may receive some additional input prompts:
| Prompt | Input | Description |
|---|---|---|
 |
Password of external database | If are using an external database, will create a Secrets Manager secret with the password value |
 |
Password of existing Redshift cluster | If are giving a Redshift endpoint in the user_config.json file, will create a Secrets Manager secret with the password for the cluster database |
Once the script has been run, you can monitor the deployment of CloudFormation stacks through the CloudShell terminal, or with the CloudFormation console.
-
Open the CloudFormation console, and select Stacks in the left panel:
- Filter by the stack name used for the deployment
- Select the stacks to be deleted, and select Delete at the top
-
To remove secrets produced by the deployment, you can either
- Open the Secrets Manager console, and select Secrets in the left panel
- Filter by the stack name used for the deployment
- Select each secret, and under Actions, select Delete secret
- Replace
[STACK NAME]in the below prompts below with the stack name used for the deployment and run them in CloudShell:
aws secretsmanager delete-secret --secret-id [STACK NAME]-SourceDBPassword --force-delete-without-recoveryaws secretsmanager delete-secret --secret-id [STACK NAME]-RedshiftPassword --force-delete-without-recoveryaws secretsmanager delete-secret --secret-id [STACK NAME]-RedshiftClusterSecretAA --force-delete-without-recovery - Open the Secrets Manager console, and select Secrets in the left panel
-
Error:
User: [IAM-USER-ARN] is not authorized to perform: [ACTION] on resource: [RESOURCE-ARN]User running CloudShell doesn't have the appropriate permissions required - can use a separate IAM user with appropriate permissions:
NOTE: User running the deployment (logged into the console) still needs AWSCloudShellFullAccess permissions
- Open the IAM console
- Under Users, select Add users
- Create a new user
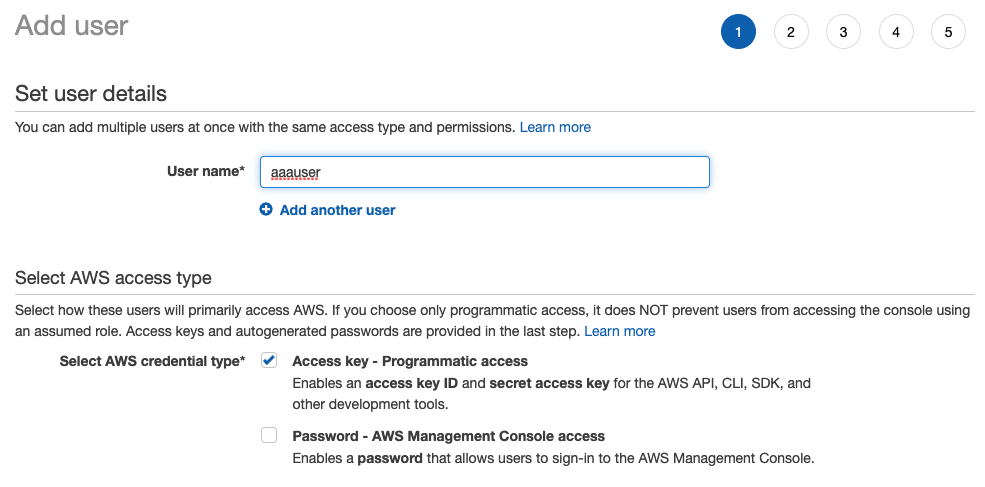
- Select Next: Permissions
- Add the following policies:
- IAMFullAccess
- AWSCloudFormationFullAccess
- AmazonSSMFullAccess
- AmazonRedshiftFullAccess
- AmazonS3FullAccess
- SecretsManagerReadWrite
- AmazonEC2FullAccess
- Create custom DMS policy called AmazonDMSRoleCustom -- select Create policy with the following permissions:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "dms:*", "Resource": "*" } ] }
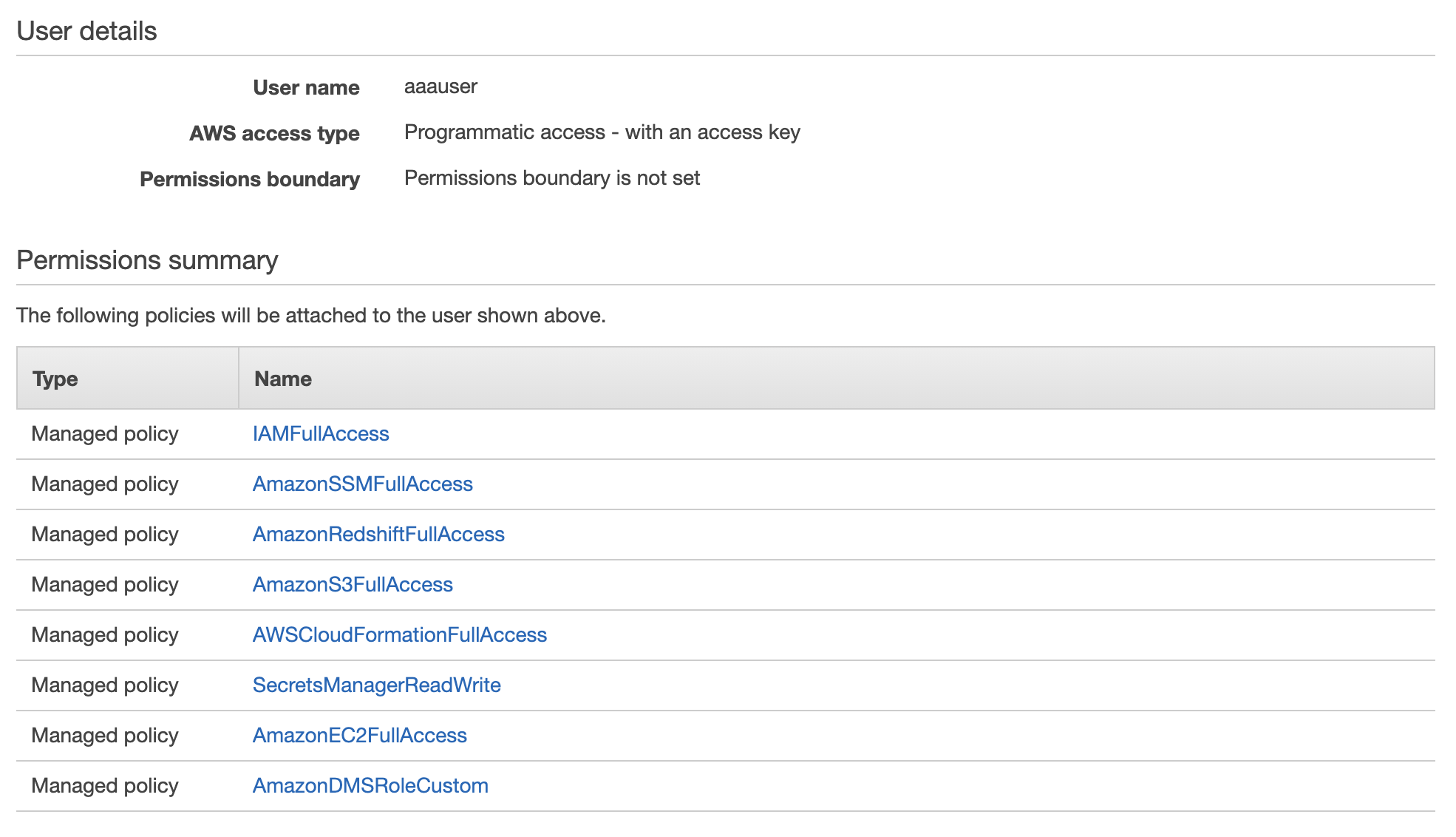
- Get and download the CSV containing the Access Key and Secret Access Key for this user -- these will be used with Cloudshell:

-
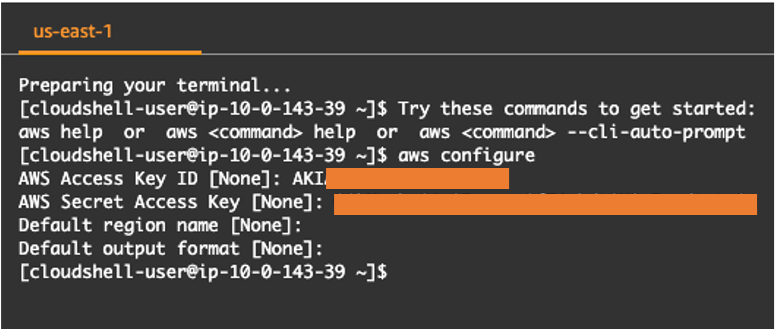
When first open CloudShell, run
'aws configure'
-
Enter the Access Key and Secret Access Key downloaded for the IAM user created in the Prerequisites
-
Error:
An error occurred (InvalidRequestException) when calling the CreateSecret operation: You can't create this secret because a secret with this name is already scheduled for deletion.This occurs when you use a repeated stack name for the deployment, which results in a repeat of a secret name in Secrets Manager. Either use a new stack name when prompted for it, or delete the secrets by replacing
[STACK NAME]with the stack name used for the deployment in the following commands and running them in CloudShell:aws secretsmanager delete-secret --secret-id [STACK NAME]-SourceDBPassword --force-delete-without-recoveryaws secretsmanager delete-secret --secret-id [STACK NAME]-RedshiftPassword --force-delete-without-recoveryaws secretsmanager delete-secret --secret-id [STACK NAME]-RedshiftClusterSecretAA --force-delete-without-recoveryThen rerun:
~/amazon-redshift-infrastructure-automation/scripts/deploy.sh




Our aim is to make this tool as dynamic and comprehensive as possible, so we’d love to hear your feedback. Let us know your experience deploying the solution, and share any other use cases that the automation solution doesn’t yet support. Please use the Issues tab under this repo, and we’ll use that to guide our roadmap.
See CONTRIBUTING for more information.
This library is licensed under the MIT-0 License. See the LICENSE file.