- This is a pytorch implementation of the Encoder-Generator-Discriminator architecture for learning disentagled representations of text

- We have three modules, an Encoder , a Generator and a Discriminator. . Training is done in a wake-sleep fashion.
- Encoder takes
xas input and produces a latent vectorz. We define a structured controllable vectorc. Generator takes the concatenated vectorz,cto generate the corresponding sentencex'. Discriminator ensures that the generated sentence is consistent with the contrallable vectorc. - Modules are learned in a way such that we get disentangled representations. When all modules are trained we expect:
- A generator to produce novel sentences conditioned on
c - An encoder to capture all features other than
cin a vectorz. - A discriminator that can be used to identify
cgiven a sentence.
- A generator to produce novel sentences conditioned on
- In this implementation, c only represents a sentiment, i.e postive or negative (dim(c) = 1).
- Discriminator is a TEXT_CNN. In principle, we can use more than one discriminator for other features like tense, humor, etc if we have some labeled examples.
- VAE Loss: Variational-Autoencoder Loss which has KL-Divergence and Cross-Entropy. KLD annealing is used to avoid the loss from KLD to drop zero once the training begins.
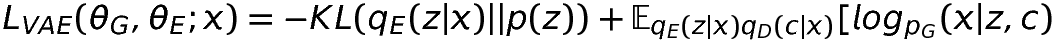

- VAE Loss
- Reconstruction of z: The generated sentence is sent back to encoder and loss from reconstruction of z is added to the generator loss. To pass the gradient back to generator, soft distribution is used as the input.
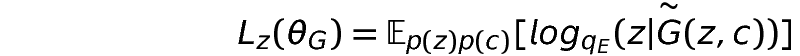

- Reconstruction of c: The generated sentence is used as input to discriminator. Again we use soft distribution as the input.


- Loss from labelled data: Here XL are the sentences and CL are the corresponding labels.

- Loss from generated data: In the sleep phase, sentences are generated for random
zandc. Discriminator uses thatcas the signal for the generated data. An additional entropy regularizing term is used to alleviate the issue of noisy data from generator.

Link - (https://drive.google.com/open?id=1EUywrhUgtc2IjiU12ZmN8xTGDWqdIXRR)
Toward Controlled Generation of Text
Zhiting Hu, Zichao Yang, Xiaodan Liang, Ruslan Salakhutdinov, Eric P. Xing ;
Proceedings of the 34th International Conference on Machine Learning, PMLR 70:1587-1596, 2017.