阿里云开发者社区爬虫
使用该项目,推荐您拥有以下的产品权限 / 策略:
| 服务/业务 | 函数计算 |
|---|---|
| 权限/策略 | AliyunFCFullAccess |
- 🔥 通过 Serverless 应用中心 ,
该应用。

- 通过 Serverless Devs Cli 进行部署:
- 安装 Serverless Devs Cli 开发者工具 ,并进行授权信息配置 ;
- 初始化项目:
s init developer-spider -d developer-spider - 进入项目,并进行项目部署:
cd developer-spider && s deploy -y
本应用是基于 Python 语言的爬虫案例,主要包括:
- 获取随机头
- 建立代理IP池
- 删除代理IP
- 获取代理IP
通常情况下,反爬虫系统会校验请求头信息,在请求头信息中最常校验的就是User-Agent,所以在本方法中,会随即返回一个User-Agent。如果在使用过程中,已经列举的User-Agent无法满足需求,可以额外添加。
tips:
User-Agent不仅仅单纯的应对反爬虫的时候会有用,往往也会降低我们的数据采集难度,例如有一些网站手机端User-Agent请求时所触发的反爬虫策略等级会远小于电脑版,所以User-Agent在一定程度上也可以用来切换客户端类型。
由于代理IP在一定程度上是需要付费进行使用的,所以本案例所采用的代理IP部分仅供学习和参考。
本案例的代理IP服务商来自阿里云云市场:https://market.aliyun.com/products/57126001/cmapi00037885.html
开发者可以根据自己的需求对这一部分的代理IP获取方法进行完善。
tips:本文所采用的代理IP使用策略是,当前IP失效后,清理掉失效IP,再更换代理IP,当然这个策略并不一定适合全部的数据采集情况,例如某些网站的反爬虫策略是IP限频,那么此时如果想要突破频率,可以采用的是每次更换代理IP,或同一链路请求完成更换代理IP,代理IP不清理并且循环利用;
循环条件,此处案例1到10,用来进行页码的循环,但是在实际爬虫过程中可能有其他的方法:
- 根据返回的数据页面进行循环;
- 根据返回的数据个数,决定是否要继续循环操作;
- 更具已有的列表决定是否要循环
当然还有其他的很多循环条件,此处可以根据实际需要自行修改
在代码中虚拟了一个逻辑分支,用于为用户铺垫切换IP/切换UA/删除IP的条件:例如 response 出现了某个指定的字符串,需要对现有的IP进行删除,并切换IP和UA
if 'xxxxx' in response:
proxy = getProxy()
headers["User-Agent"] = getUserAgent()
response_status = False
# 触发重试逻辑,进行重试
continue
数据的下游处理方法在本文中并没有提及,通常情况下会将数据存放在MongoDB等数据库进行持久化,或将数据转到下游清洗逻辑进行数据清洗等相关的操作。
当前案例采用的是定时任务,当然,在实际生产中可能出现触发式爬虫,例如像OSS写入数据进行数据采集,或者通过url进行数据采集。这一部分可以根据项目实际需求进行更改。
项目中定时任务配置:
triggers:
- name: timer
type: timer
config:
cronExpression: '@every 100m'
enable: true
部署完成后,可以点击函数:
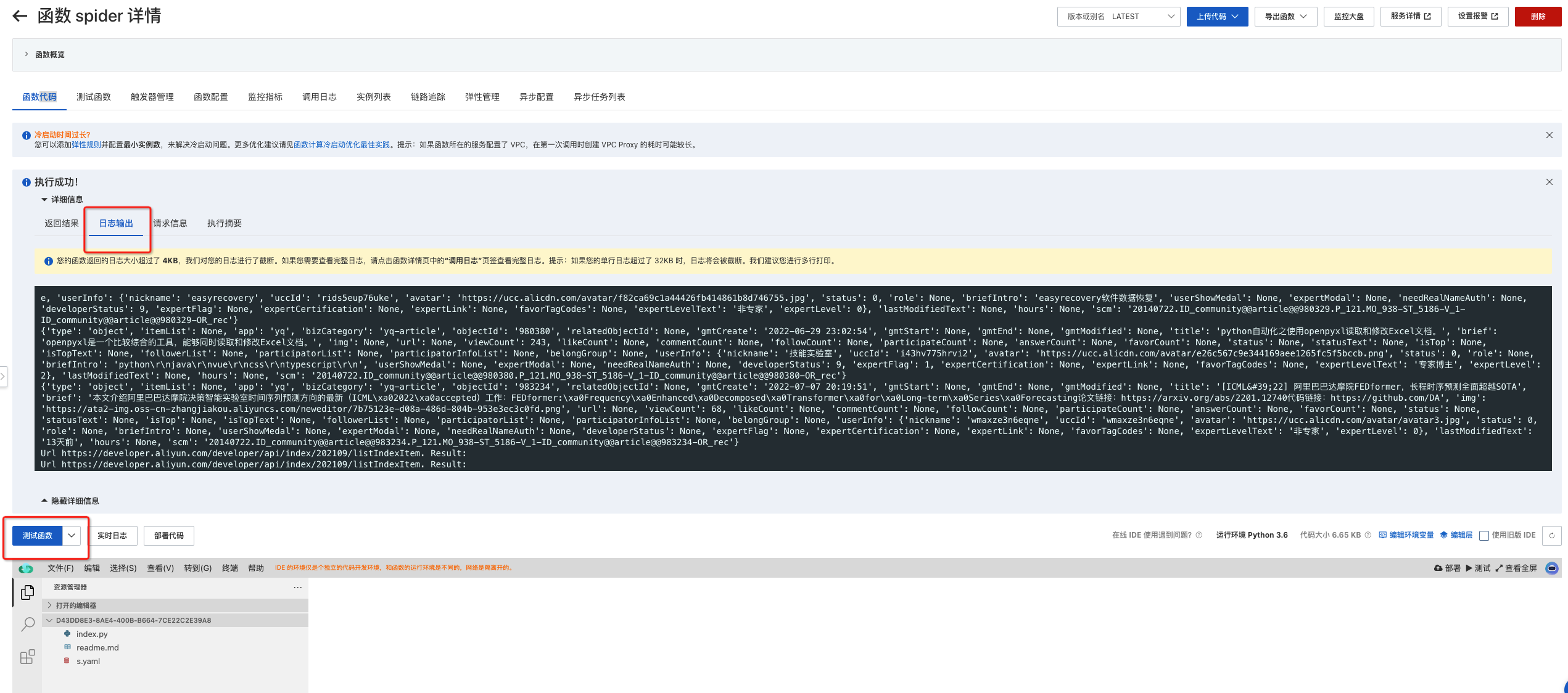
进入到函数查看页面,此时可以点击运行查看测试效果:
您如果有关于错误的反馈或者未来的期待,您可以在 Serverless Devs repo Issues 中进行反馈和交流。如果您想要加入我们的讨论组或者了解 FC 组件的最新动态,您可以通过以下渠道进行:
 |
 |
 |
|---|---|---|
微信公众号:serverless |
微信小助手:xiaojiangwh |
钉钉交流群:33947367 |