Start Code of Human Activity Recognition by Sensor on Smartphone
Requirements knowledge: Accelerometer, Matlab, basic ML, Android
Constant:
- N: the length of a raw data array
- frameSize: 250 samples
- frameOverlap: 50 samples
- frameNum: the number of all the frames
- dimNum: 8
Essential Variables:
- rawData: concatenate all data from all files of one activity, size (N * 3)
- frame: reshape the rawData to size (frameNum * frameSize * 3)
- frames: concatenate all frame
- labels: labels of frames
- frameData: original three axis data plus the expended dimensions, size (frameNum * frameLen * dimNum)
- featureData: extract features from frameData, also the training data
Just RUN or Follow the section of Data-processing, adjust your data file format and put your files into the folders. then RUN!
Human activity recognition uses sensors on smartphone to estimate user's activities such as walking and running [1]. Deep learning techniques like LSTM have been introduced and good performances are achieved. However, the computational cost of deep learning and the complexity of deployment limit the application of the method. Moreover, if you want explanable algorithms then the traditional machine learning techniques are more applicable. In the article, we provide a start code has good scalability and could be easily used in your projects. The script is extensible, you could add more features, labels and make comparisons among many classifiers like [1] [2]
Sensor data is a time series, for accelerometer, x axis is index and y axis is quantization of acceleration in Figure 1.
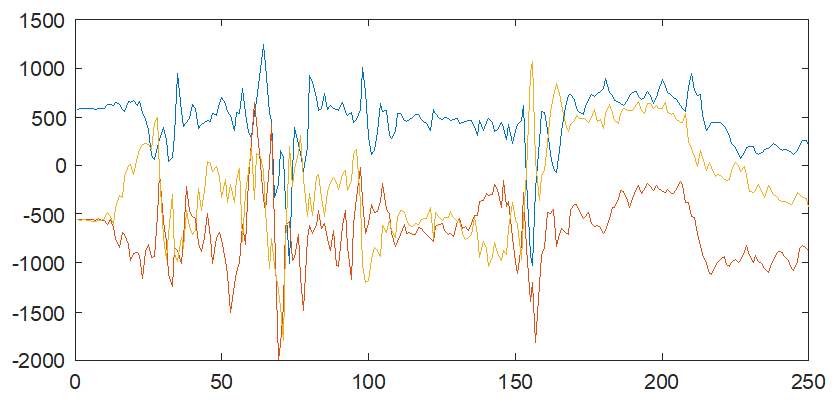 |
|---|
| Figure 1 |
We have recorded ten activities and they are stored in ten directories with the name of the corresponding activity. Each folder contains several files recorded by a sensor recording APP by 25Hz, where the smartphone is on wrist. The activities are:
driving, brushing teeth, cycling, bathing, commuting, walking, standing, running, sitting, sleeping.
Where a sequence from 1 to 10 is used to represent the activities. Each data file in a directory is recorded by the APP by CSV format (seperated by Tab '\t'). For example a data file named acc_2020.02.02.txt is:
x y z
76 -1053 -7
76 -1056 -9
76 -1063 -4
...
We iterate all the folders in a for loop where each file is read as an array and then concatenated one by one. Thus the rawData with (N, 3) contains all the data we want. Another array rawLabel is used as label. Note: You need to change your own data into this form no matter how you get it (your own APP, APPs on Google Play or public dataset).
If frameSize=250 and frameOverlap=100, a (N, 1) data could be segmented to (N, frameNum) matrix. For a 3D accelerometer, the (N, 3) data could be transformed to (N, 3, frameNum) matrix. An naive segmentation example of single dimension and three dimensions with 6 frames are shown in Figure 2.
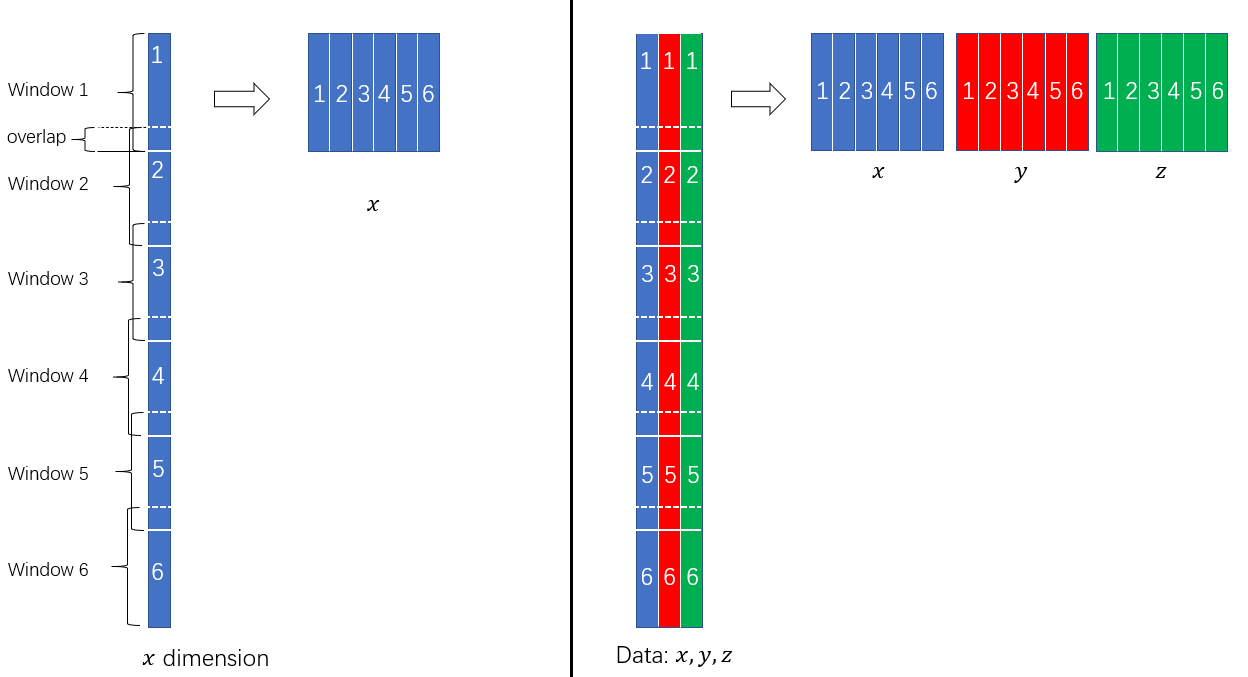 |
|---|
| Figure 2: Segmentation Example |
Where the solid line is the end of a frame and the dotted line is the start, and there has overlap between the two lines.
frame(:,:,1) = buffer(rawData(:,1),frameSize,frameOverlap,'nodelay')';
frame(:,:,2) = buffer(rawData(:,2),frameSize,frameOverlap,'nodelay')';
frame(:,:,3) = buffer(rawData(:,3),frameSize,frameOverlap,'nodelay')';Where the build-in function buffer() is employed. Hence, we have transformed (N, 3) data into (frameSize, frameNum, 3) array.
In order to extract more information based on raw data of (x, y, z), we could also construct more dimensions from the original data like:
, the magnitude that makes the recognition invariant to rotation.
Where ,
,
, and
are the angles of the sensor [].
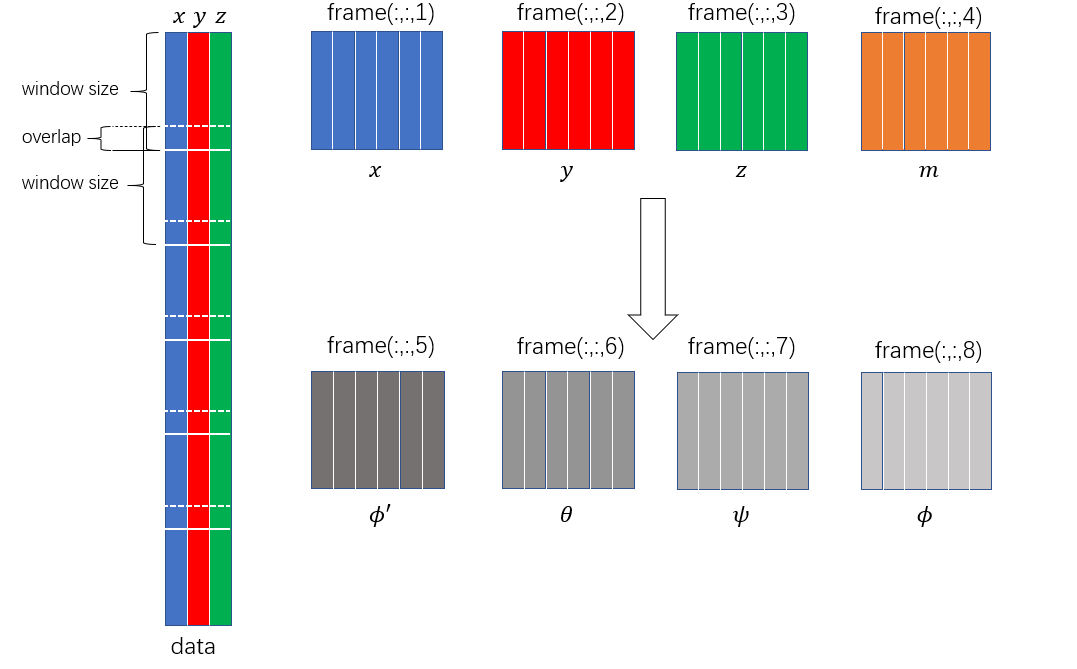 |
|---|
| Figure 3 |
Finally, we got an array of (frameNum, frameSize, 8) frameData, which means frameData(i, :, j) (frameSize-by-1) is the data of i-th frame and j-th dimension. So far, the segmentation and dimension expand have been applied.
We could extract as many features as we want from each frame defined by frameData(i, :, j). For example, we could apply build-in functions like mean() to one frame and vectorize the algorithm:
featureData(:, 1, dim) = mean(frameData(:,:,dim), 2);where the FeatureData is the feature array.
Besides the features of mean, we have summarized most commonly used features in Table 1. These features could be categorized into tatistical features, spectral features, and some heuristic/combinational features [ ]. todo: adjust the frequency coef in script to avoid magic bin number.
| index | feature | index | feature | index | feature | index | feature |
|---|---|---|---|---|---|---|---|
| 1 | mean | 8 | peak_pos | 15 | f1_3/f4_16 | 22 | f4 |
| 2 | var | 9 | f1 | 16 | sum(spec) | 23 | f5 |
| 3 | max | 10 | f2_3 | 17 | H(spectrum) | 24 | f6 |
| 4 | min | 11 | f4_5 | 18 | mean-crossing | 25 | f7 |
| 5 | skewness | 12 | f6_16 | 19 | f1 | 26 | f8 |
| 6 | kurtosis | 13 | f1/f2_3 | 20 | f2 | 27 | f9 |
| 7 | energy | 14 | f4_5/f6_16 | 21 | f3 | 28 | f10 |
Table 1: Statistical Features, Spectral Features and other Features
Simply apply all these features to every frame in frameData, we obtain a FeatureData (frameNum, 18, 8).
In order to put the feature data into classifiers, we need reshape the FeatureData from 3d to 2d matrix.
for dim=1:dimNum
temp = [temp featureData(:,:,dim)];
end
FeatureDataset = temp;Now the FeatureData is a 2d matrix (frameNum, 144).
The correlation features between x,y,z,m dimensions are employed, for example the correlation between x and y:
max(abs(xcorr(frameData(i,:,1), frameData(i,:,2))));All combinations between the x,y,z,m dimensions are computed and then padded to the FeatureData.
Hence we get the standard feature data FeatureData (frameNum, featureNum).
- Sometimes, the dataset could be severely inbalanced, so a downsampling step is added.
- Remove NaN values in the feature data.
Given the above approaches, we have built a typical data processing for sensor data. There have a lot of materials on classification method, so we only show the basic steps here:
- cross validation
- normalized
- select a classfier and training
tc = fitctree(TrainingFeatureSet,TrainingFeatureLabel, 'MaxNumSplits',30);note: you could choose any classifiers in the matlab: SVM, RF, etc. 4. predict classifier
y_hat = predict(tc, TestingFeatureSet);- error analysis of results (confusion matrix, recall, precision, etc.), find problems, fix and improve performance.
In the report, a simple decision tree is employed and you could view the structure by view().
Recursively look into wrong labeled data and re-training
You could expand the dimension by anyways you like, e.g., a specific pattern/shape and furthermore extact any features from the dimension
Easily to be implemented by C language.
For further affects of different settings like sensor position, sampling rate, classifers, please find [2]
Experiment design notes:
- Use a camera to record the subject's activity or one time period for one specific activity
- device: smartphone, wrist band. attach the smartphone to a specific part of the body
- an android app to record the sensor. e.g. Advanced Sensor Recorder, Sensor Record or https://github.com/kprikshit/android-sensor-data-recorder
[1] Buke, Ao, et al. "Healthcare algorithms by wearable inertial sensors: a survey." China Communications 12.4 (2015): 1-12.
[2] Ao, Buke, et al. "Context Impacts in Accelerometer-Based Walk Detection and Step Counting." Sensors 18.11 (2018): 3604.
[3] Bulling, Andreas, Ulf Blanke, and Bernt Schiele. "A tutorial on human activity recognition using body-worn inertial sensors." ACM Computing Surveys (CSUR) 46.3 (2014): 1-33.
[4] Brajdic, Agata, and Robert Harle. "Walk detection and step counting on unconstrained smartphones." Proceedings of the 2013 ACM international joint conference on Pervasive and ubiquitous computing. 2013.