We will be using Apache Spark, a leading distributed computing framework, to analyze a Netflix dataset to predict which shows/movies users will enjoy. We will show the effect of training amount and regularization on the accuracy of the task, as well as the speedup (if any) afforded by using more cores.
- Use Apache Spark and Vanderbilt University's ACCRE cluster to perform predictive analysis on a large dataset.
- Run the job with varying amounts of training to show the effect on accuracy.
- Test the data against different models with different regularization parameters to analyze the impact of overfitting the data.
- Run the job using different numbers of cores to analyze the speedup caused by increased cores.
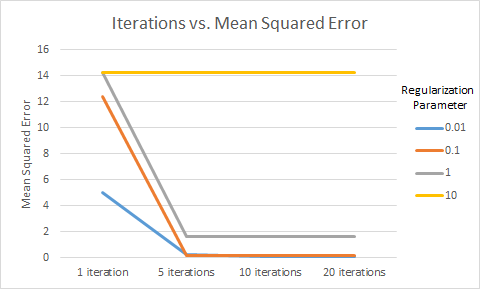
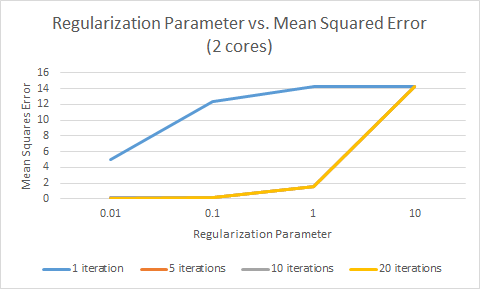
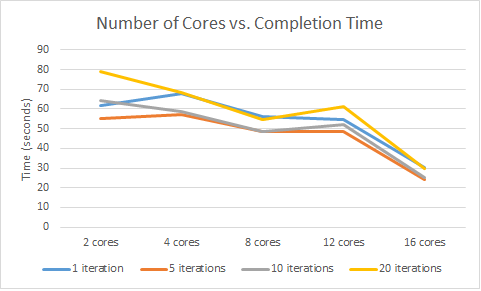
Figure 1 maps the number of iterations used for training against the MSE, or mean squared error of the results. For the most part, Figure 1 shows that the more training data used, the lower the error. The exception is when the regularization parameter is high; this means that in an attempt to avoid overfitting data, we reduce the accuracy of the predictions. Overall, we see that, as would be expected, more time training yields higher accuracy, though there are noticable diminishing returns between even 5 and 10 iterations.
Figure 2 maps the regularization parameter against the MSE. Somewhat surprisingly, in all cases, an increase in the regularization parameter yields higher error. The regularization parameter is used to avoid overfitting the data. A higher regularization parameter means a less complex model used for prediction, to avoid being too specific to this exact dataset. However, in our case, in all cases, a lower regularization parameter (and therefore a more complex model) led to more accurate predictions.
Figure 3 maps the number of cores used to run the job against the time it took to complete the job. While of course this led to a general speedup, this speedup was much less linear than expected. The time reduction from 2 all the way to 12 cores was rather gradual, and surprisingly increased in some cases. The real reduction was not obvious until 16 cores were used. Typically you see more linear returns or even diminishing returns.
We successfully ran predictive data analysis on the Netflix dataset using Apache Spark on Vanderbilt University's ACCRE cluster. Overall, results were somewhat unexpected. We expected overfitting to become an issue, but instead, we saw no penalties in accuracy for having overly complex models (aka high regularization parameters). We did, however, see diminishing returns in the complexity (lower regularization parameter) vs. the accuracy. We also expected a more linear or less than linear speedup with the number of cores; however, the data seems to suggest the biggest improvement was between 12 and 16 cores. This could be due to how Apache Spark divided our data, or due to properties of the ACCRE cluster. Training amount and accuracy did correlate as expected; more training led to higher accuracy. Lastly, it was interesting to note that regardless of how many epochs were run, the overall time remained relatively consistent. This indicates that most of the time spent was spent on data pipelining and results management, rather than running the algorithm. Regardless of our expectations, our goals were met.