欢迎来到MY_QBOT项目!这是一个基于Python的QQ机器人后端服务,提供了一系列自动化和交互功能。
- AI聊天,角色扮演
- 群聊
- 从pixiv获取并发送涩图()
- 指定关键词发送或者随机涩图
- AI绘画
- AI生成语音
目前仅在Windows端Llonebot上测试过,理论上所有支持oneonev11协议的消息平台都可以用,不过http对接配置可能要麻烦一点
-
先运行如下命令建立相关目录与文件:
mkdir bot && cd bot mkdir config && cd config vim config.json打开config.json文件,按i进入输入模式,按需填入以下配置:
{ "openai_api_key": "",#你的apikey "model": "gpt-3.5-turbo",#默认3.5 "nicknames": [""],#当消息中出现nickname时自动触发对话 "self_id": 123,#修改为机器人QQ号 "admin_id": 456,#修改为管理员QQ号 "block_id": 789, #修改为要屏蔽的QQ号 "report_secret": "123456",#http上报密钥,见下文Llonebot配置,如果选择反向ws连接则可不填。 "connection_type": 连接类型,可选`http`和`ws_reverse`,具体见下文。 "proxy_api_base": "https://api.openai.com/v1",#api请求地址,默认为官方 "system_message": { "character": ""#机器人人设 }, "reply_probability": 0.5 #群聊中没有nickname时触发主动聊天的概率 "r18": 0为关闭r18,1开启r18,2为随机发送(慎选) "audio_save_path": 语音文件保存位置 "voice_service_url": 语音接口地址 "cha_name":语音接口指定角色 }填完后按下esc退出输入,再输入
:wq回车保存 回到上一级目录vim docker-compose.yaml新建docker-compose.yaml文件,将项目内的复制过去,或者直接下载项目内的,copy到服务器上,执行
docker-compose up -d即可,记得放行3001端口,用于跟QQ通信
-
- 安装Python环境:确保您的系统上安装了Python 3.11或更高版本(低版本还没有测试过)。
- 克隆本项目
git clone -b dev https://github.com/syuchua/MY_QBOT.git- 进入项目目录
cd MY_QBOT- 创建虚拟环境(可选):
python -m venv venv source venv/bin/activate # 对于Windows使用 venv\Scripts\activate- 安装依赖:
pip install -r requirements.txt
在config.json文件中配置机器人的设置,包括但不限于:
-
openai_api_key: 你的openai_api_key -
model: 使用的模型,默认为gpt-3.5-turbo -
self_id:机器人的QQ号。 -
admin_id:管理员的QQ号。 -
block_id: 要屏蔽的QQ号。 -
nicknames:机器人的昵称列表。 -
system_message:系统消息配置,最重要的是character,相当于机器人的人格。 -
connection_type: 连接类型,可选http或ws_reverse -
report_secret: http事件上传密钥。 -
enable_time: 每天自动开始回复时间,如08:00 -
disable_time: 自动停止回复时间如02:00 -
proxy_api_base: openai_api_key请求地址,默认为https://api.openai.com/v1 -
reply_probability: 当收到的消息中没有nickname时的回复频率,1为每一条都回复,0为仅回复带有nickname的消息,默认0.5 -
r18: 0为关闭r18,1开启r18,2为随机发送(慎选) -
audio_save_path: 语音文件保存位置 -
voice_service_url: 语音接口地址 -
cha_name:语音接口指定角色

若使用反向ws连接则仅需这样配置:
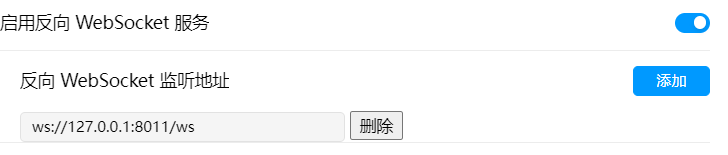
本项目使用 MongoDB 作为数据库。MongoDB 是一个文档导向的 NoSQL 数据库,具有高性能、高可用性和易扩展性的特点。
虽然 SQLite 是一个轻量级的选择,但 MongoDB 在以下方面具有优势:
- 可扩展性:MongoDB 可以轻松处理大量数据和高并发访问。
- 灵活性:MongoDB 的文档模型允许存储复杂的数据结构,无需预定义模式。
- 查询能力:MongoDB 提供强大的查询语言,支持复杂的数据分析。
- 分布式:MongoDB 支持分片,可以在多台服务器上分布数据。
-
下载 MongoDB: 访问 MongoDB 下载页面 并下载适合你操作系统的版本。
-
安装 MongoDB: 按照官方文档的指引进行安装。
-
启动 MongoDB 服务:
- Windows:
进入 MongoDB 安装目录,运行以下命令(请根据实际情况修改路径):
注意:请确保指定的数据和日志目录已经存在。
mongod --dbpath D:\MongoDB\data --logpath D:\MongoDB\log\mongodb.log --logappend - macOS/Linux: 运行
sudo systemctl start mongod
- Windows:
进入 MongoDB 安装目录,运行以下命令(请根据实际情况修改路径):
-
注意:确保在启动机器人之前,MongoDB 服务已经正常运行。
本项目使用 app/database.py 文件管理数据库操作。主要功能包括:
- 存储用户信息
- 记录聊天历史
- 管理会话上下文
数据库的具体配置和操作已在 database.py 中实现,无需额外配置。
在终端中执行以下命令启动机器人:
python main.py
- 直接对话即可
- 发送
发一张,来一张+关键词即可自定义发送涩图,比方说发一张卡芙卡 - 发送
来份涩图,来份色图,再来一张即可发送随机涩图 - 发送
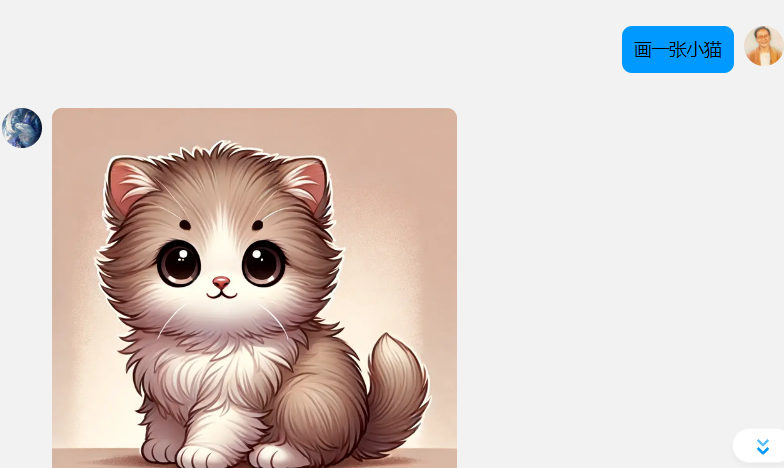
画一张,生成一张即可发送AI绘画(目前默认使用dalle进行AI绘画,若需使用AI绘画功能,模型必须为gpt系列) - 发送
语音说,``语音回复+要用语音说的话`让机器人发送语音,或者再提示词里提示机器人通过把`#voice`标签放在回复的开头,实现更生动地语音回复。 - 发送
点歌+歌曲名进行点歌,支持模糊匹配。 - R-18?
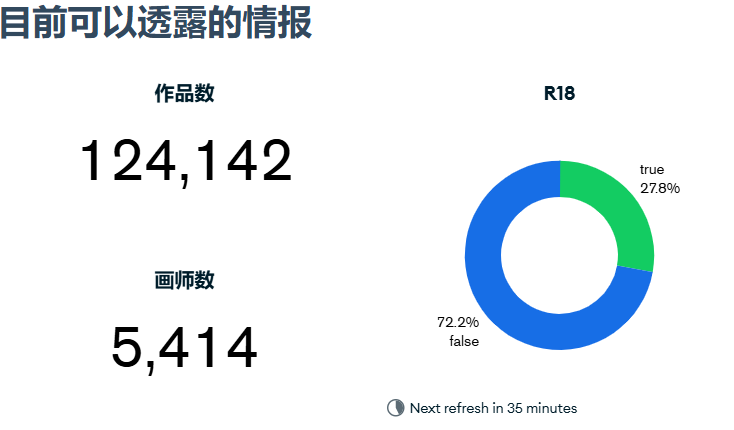
该接口的涩图数量足有十几万,其中r18占27.8%,建议公共场合尽量设置为0,2的话,还是不要太相信自己的运气了(问就是惨痛的教训)

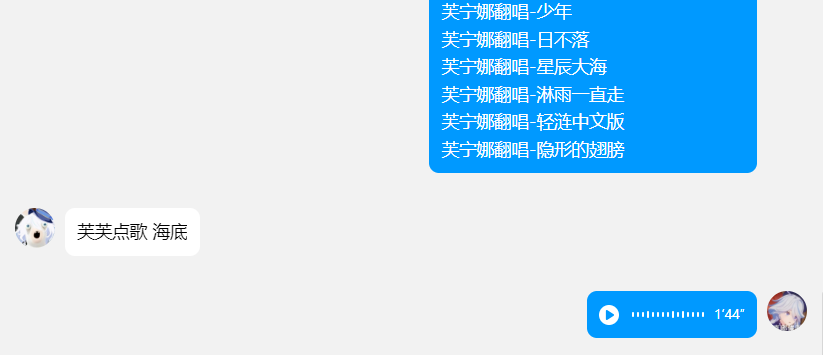
AI翻唱.zip 解压后放到data/music目录下即可
机器人支持以下命令:
/help:显示帮助信息。/reset:重置当前会话。/character:输出config.json中的character值,也即当前的人设。/history: 输出之前的条消息记录,默认十条,也可以接空格+数字指定。/clear:清除消息记录,默认十条,可接空格+数字指定。/music_list: 获取歌曲列表/r18 [0, 1, 2]切换涩图接口r18模式,0为关闭,1为开启,2随机/model [new_model]切换模型,新模型需先在model.json中配置好。
- 基本的消息接收和发送功能
- 命令交互
- 配置文件读取和解析
- 接入ChatGPT
- 接入DALLE
- 接入图片接口
- 自定义人格
- 新增支持反向ws连接
- 接入语音接口 #本地搭建参考b站箱庭xter的视频: https://b23.tv/9dOdMo6
- 接入其他大模型 #理论上只要符合openai api格式都可以,不过目前只涵盖了gemini,claude和kimi,其他的可以仿照
config/model.json里的models配置自己写,记得下方model的值要在上方的available_models里。 - 新增图片识别功能,需要模型为
GPT4系列或在model.json里设置vision为true
如果您有任何建议或想要贡献代码,请提交Pull Request或创建Issue。
本项目采用MIT许可。