Monitering Money Movement.
Recorded Presentation, Slidedeck, Recorded Dashboard Demo, and Dashboard
The Foreign Exchange market (ie. the Currency Market) is the largest financial market in the world and over 6 trillion in US dollars are traded every day. This market is a crucial tool for multinational corporations who want to protect themselves from the risk associated with foreign currency transactions. When creating long term business and investment strategies, it is important for these corporations to track changes in currency prices. Interest rates play a key role in currency prices however, forex trading platforms do not provide easy access to this data.
Currency Flow is a platform that synthesizes data to help corporate researchers and analysts determine how forex price action responds to a global event. To do so, it aggregates historical forex data and interest rates for a chosen timeframe to get a snapshot of the underlying movement of capital between economies.
Note: Currency Flow processes ~200GB of raw Forex data for the period January 2010 to October 2020.
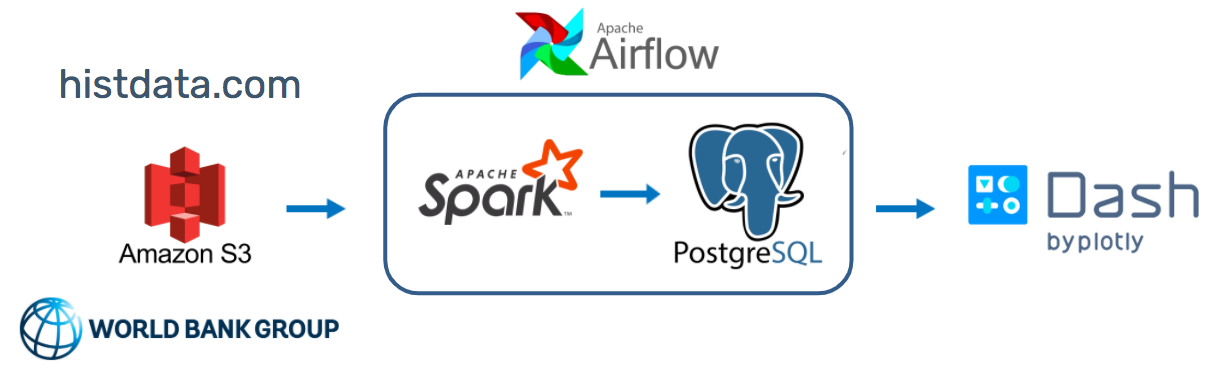
Historical currency data starting from 2000 is available from histdata.com. Note that some currency pairs have more data then others. The data is available in a variety of formats but the data used for this project are ascii tick data quotes which are non-aggregated trade quotes. Interest rate data since 1956 is available from OECD.
I tested and tuned various methods and configurations to optimize the Spark aspect of the pipeline. The first effective method I found was pre-defining a static schema and utilizing Spark functions as opposed to UDF wrappers. Repartitioning and caching dataframes before running Spark SQL queries brought run-time down to 8 minutes. Also tuning partition parameters led to further decreased job time. And this resulted in a total 34% reduction compared to baseline.
Another challenge I tackled was improving database query speeds for my UI. I improved query speeds by creating an index for lookups and list partitioning tables by currency pair which reduced look up time from 3.23 to 1.2 seconds.
In the Data Processing folder you will find the currency_pairs.csv file which lists the currency pair options. The read_in.py script reads currency trade csv files to Spark dataframes for each month of the specified date range and does the following:
Filters dataframes based on specified conditions and returns certain fields Writes the DataFrame to a Postgres table (table creation is not included in this script) with the following schemas:
Forex Data Schema
|-- pair (string),
|-- date (date),
|-- min_bid (float),
|-- max_bid (float),
|-- avg_bid (double),
|-- min_ask (float),
|-- max_ask (float),
|-- avg_ask (double)
Interest Rate Data Schema
|-- location (string),
|-- time (date),
|-- value (float)
This project was built using an Apache Spark 2.4.7 / Hadoop 2.7 binary downloaded from spark.apache.org. It reads from AWS S3 and writes to PostgreSQL, so a driver from jdbc.postgresql.org should added in spark/jars/ and configurations should be added to spark-defaults.conf. The frontend runs in Python 3 with Dash.
For data ingestion, run the data_upload.py script. Specify the date range you are interested in and the destination. The script performs the following tasks:
- Downloads compressed trade files for each month in the specified date range.
- Unzips the files (.zip -> .csv)
- Stores monthly csv files to specified S3 bucket
Setup Spark 2.4.7 using these instructions. I set up 1 master node and 2 workers which are m5.large EC2 instances (18.04 Ubuntu,2 vCPUs, 8GB). Navigate to your master instance and use run.sh to read in and process data for this application.