End-to-end Machine Learning Pipeline demo using Delta Lake, MLflow and AzureML in Azure Databricks
The problem I set out to solve is this public Kaggle competition hosted my Microsoft earlier this year. Essentially, Microsoft has provided datasets containing Windows telemetry data for a variety of machines; in order words - a dump of various windows features (Os Build, Patch version etc.) for machines like our laptops. The idea is to use the test.csv and train.csv dataset to develop a Machine Learning model that would predict a Windows machine's probability of getting infected with various families of malware.
 .
.
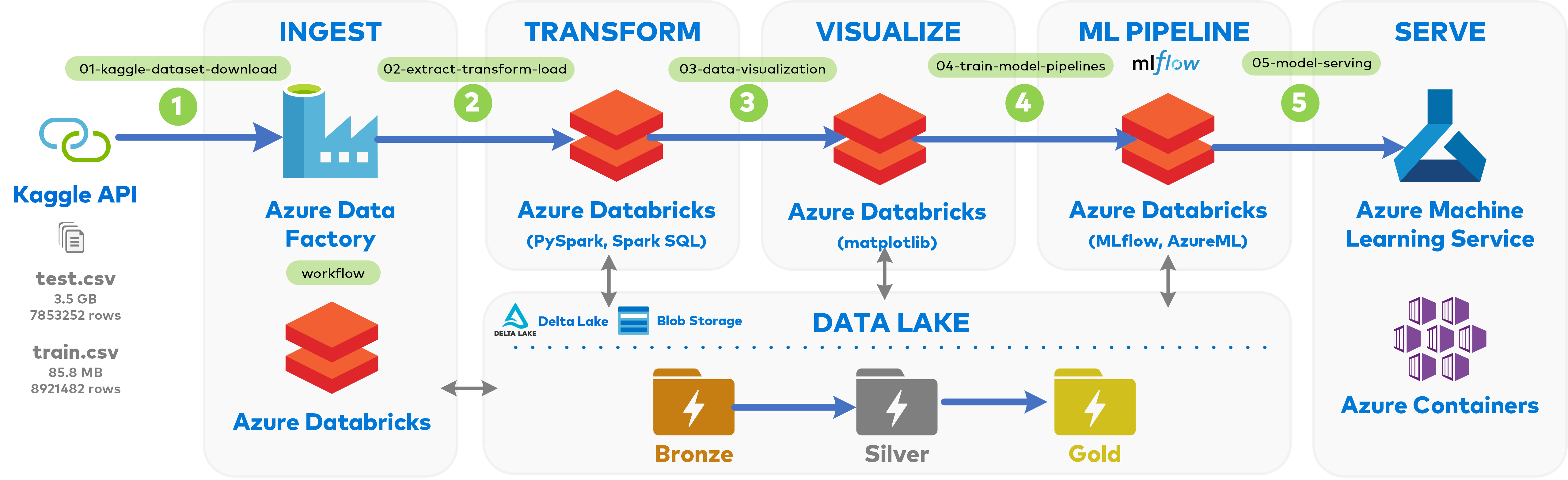
01-kaggle-dataset-download: Connecting to Kaggle via API and copying competition files to Azure Blob Storage
The Kaggle API allows us to connect to various competitions and datasets hosted on the platform: API documentation.
Pre-requisite: You should have downloaded the kaggle.json containing the API username and key and localized the notebook below.
In this notebook, we will -
- Mount a container called
bronzein Azure Blob Storage - Import the competition data set in .zip format from Kaggle to the mounted container
- Unzip the downloaded data set and remove the zip file
Here is the Data Lake Architecture we are emulating:
Pre-requisite: You should have run 01-kaggle-dataset-download to download the Kaggle dataset to BRONZE Zone.
In this notebook, we will -
- EXTRACT the downloaded Kaggle
train.csvdataset from BRONZE Zone into a dataframe - Perform various TRANSFORMATIONS on the dataframe to enhance/clean the data
- LOAD the data into SILVER Zone in Delta Lake format
- Repeat the above three steps for
test.csv - Take the Curated
test.csvdata and enhance it further for ML scoring later on.
I'm leveraging a lot of the visualization/data exploration done by the brilliant folks over at Kaggle that have already spent a lot of time exploring this Dataset.
Pre-requisite: You should have run 02-extract-transform-load and have the curated data ready to go in SILVER Zone.
In this notebook, we will -
- Import the
malware_train_deltatraining dataset from SILVER Zone into a dataframe - Explore live visualization capabilities built into Databricks GUI
- Explore the top 10 features most correlated with the
HasDetectionscolumn - the column of interest - Generate a correlation heatmap for the top 10 features
- Explore top 3 features via various plots to visualize the data
MLflow Tracking is one of the three main components of MLflow. It is a logging API specific for machine learning and agnostic to libraries and environments that do the training. It is organized around the concept of runs, which are executions of data science code. Runs are aggregated into experiments where many runs can be a part of a given experiment and an MLflow server can host many experiments.
MLflow tracking also serves as a model registry so tracked models can easily be stored and, as necessary, deployed into production.
In this notebook, we will -
- Load our
traindataset from SILVER Zone - Use MLflow to create a Logistic Regression ML Pipeline
- Explore the run details using MLflow integration in Databricks
Operationalizing machine learning models in a consistent and reliable manner is one of the most relevant technical challenges in the industry today.
Docker, a tool designed to make it easier to package, deploy and run applications via containers is almost always involved in the Operationalization/Model serving process. Containers essentially abstract away the underlying Operating System and machine specific dependencies, allowing a developer to package an application with all of it's dependency libraries, and ship it out as one self-contained package.
By using Dockerized Containers, and a Container hosting tool - such as Kubernetes or Azure Container Instances, our focus shifts to connecting the operationalized ML Pipeline (such as MLflow we discovered earlier) with a robust Model Serving tool to manage and (re)deploy our Models as it matures.
We'll be using Azure Machine Learning Service to track experiments and deploy our model as a REST API via Azure Container Instances.

Pre-requisite: You should have run 02-extract-transform-load to have the validation data ready to go in SILVER Zone, and 04-train-model-pipelines to have the model file stored on the Databricks cluster.
In this notebook, we will -
- Batch score
test_validationSILVER Zone data via our MLflow trained Linear Regression model - Use MLflow and Azure ML services to build and deploy an Azure Container Image for live REST API scoring via HTTP