由于之前一直想爬取花瓣网(http://huaban.com/partner/uc/aimeinv/pins/) 的图片,又迫于没时间,所以拖了很久。
鉴于最近在学go语言,就刚好用这个练手了。
进入网站后,首页大概是这个样子
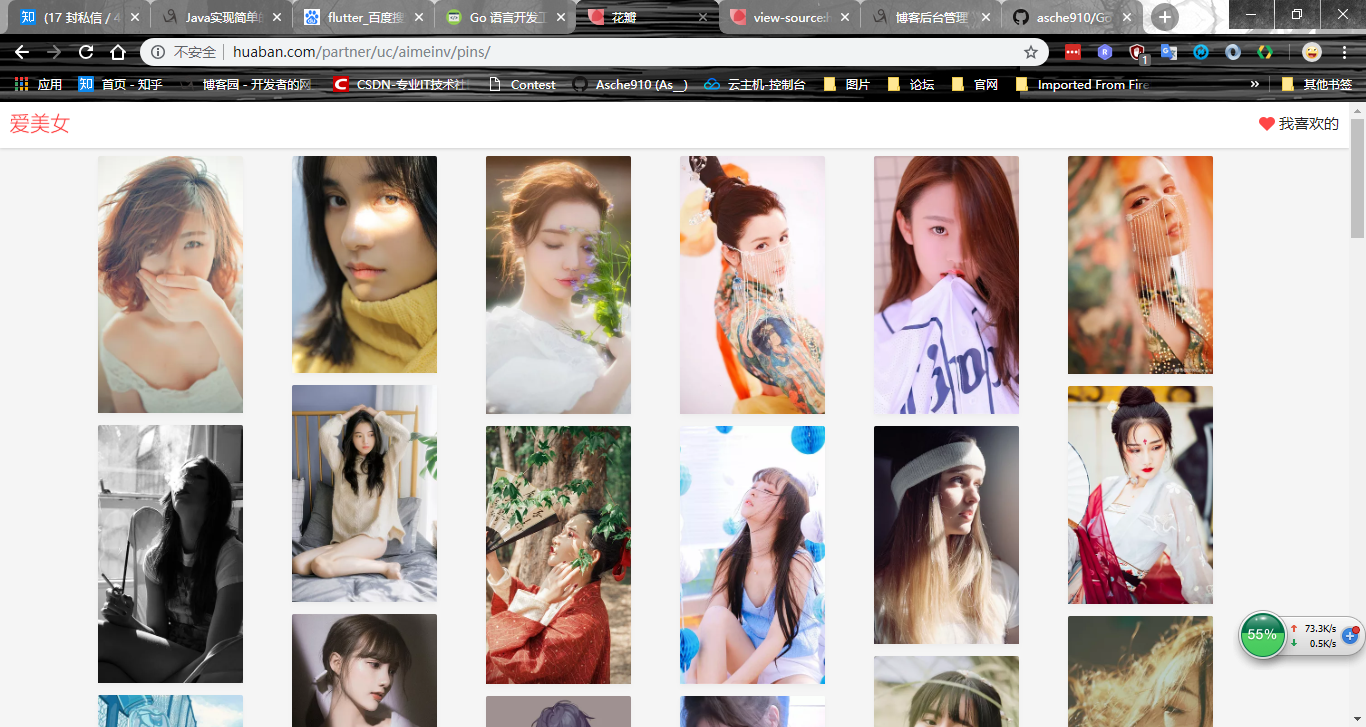
网站采用的流式布局,动态加载。未经渲染的初始页面源代码中包含有20张图片的相关信息。 每张图片有它的pin_id和key, pin_id差不多就是id,而key应该是文件的特性码,由此key拼接url可以直接得到图片的地址。
使用了动态加载,鉴于这个比较简单,就没必要用无头浏览器了, 直接需要抓包分析,来手动模拟翻页请求。
翻页的一个实例:
http://huaban.com/partner/uc/aimeinv/pins/?max=2117952645&limit=8&wfl=1
有三个参数max就是图片的id, limit是指定了返回图片的数量,而那个wfl就不知道了,变成0好像也没啥变化,就不管它了。
这里我想,要是直接把limit变成一个很大的数,翻页的过程不就省略了吗😂,于是就试了个800。结果我的妈呀,它还真返回了这么多。。。
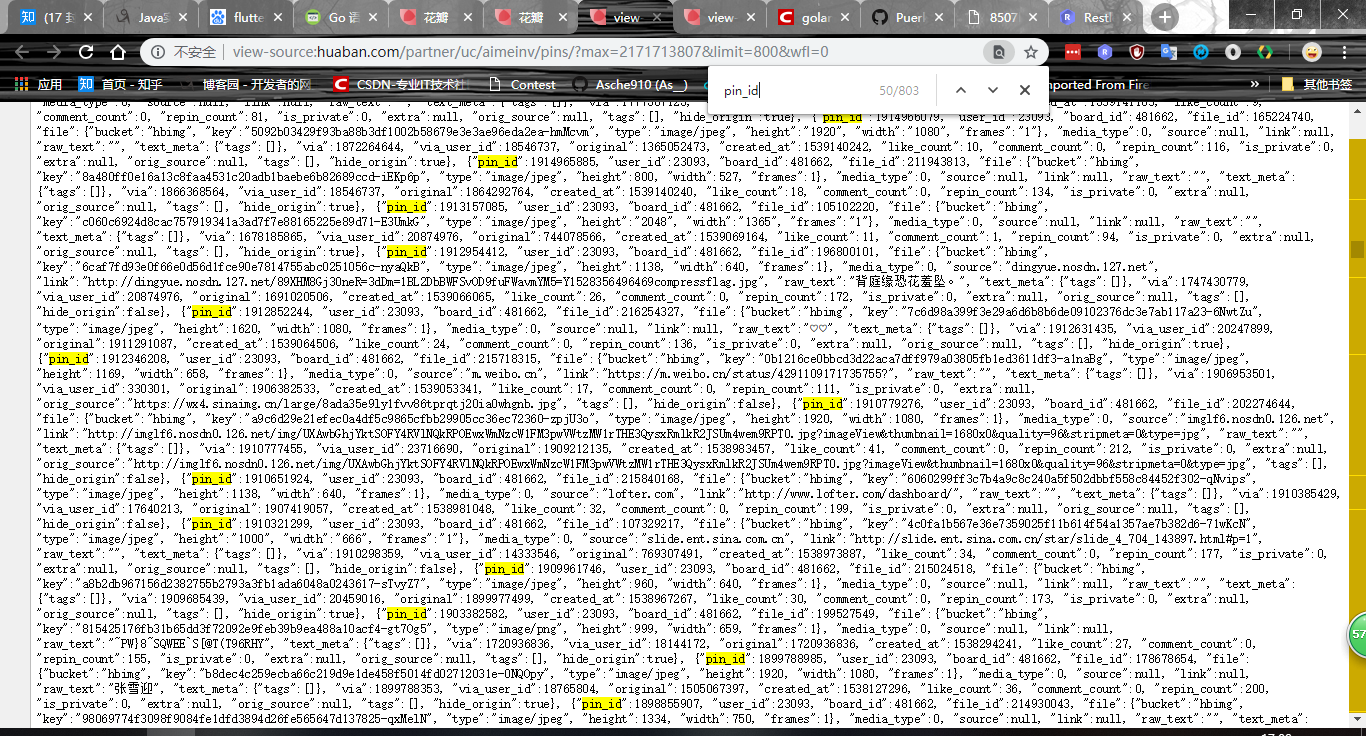
不过作为一个上进的程序员(●'◡'●),怎么能采取这种方法呢。于是继续研究,发现那个max是当前页最后一张图片的id,这样的话就好办了。
首先由url获取网页返回的内容
func getHtml(url string) string{
resp, err := http.Get(url)
if err != nil {
fmt.Println("A error occurred!")
}
defer resp.Body.Close()
htmlBytes, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
return string(htmlBytes)
}然后解析该网页,包括下载该页中的图片,以及得到max值用于翻页。抓包时发现浏览器中返回的是json,我自己也试着加上Accept头,接受json类型,但返回的仍然是html,估计是少了什么header,这里我也懒得去尝试缺少啥头部了,直接对返回的html页面解析,就像第一次打开首页那样。另外由于key都位于script标签内,所以就不太适合用goquery等库了,直接用正则解析吧
func parsePage(strHtml string) string{
// 利用正则爬取页面中图片的key
reg := regexp.MustCompile("\"key\":\"(.*?)\"")
keys := reg.FindAllStringSubmatch(strHtml, -1)
// 利用正则爬取页面中图片的pin_id
rege := regexp.MustCompile(`"pin_id":(\d+),`)
ids := rege.FindAllStringSubmatch(strHtml, -1)
for i := 0; i < len(keys) ; i++ {
key := keys[i][1]
// 过滤掉非图片类型的key
if len(key) < 46{
continue
}
fmt.Println(parseKey(key))
downImg(parseKey(key))
count++
}
// 得到用于翻页的id
fmt.Println(ids[len(ids)-1][1])
return ids[len(ids)-1][1]
}其中downImg()是图片下载函数
// 图片下载函数
func downImg(url string) {
// 处理前缀为//的url
if string([]rune(url)[:2]) == "//" {
url = "http:" + url
fmt.Println(url)
}
// 解决文件无图片格式后缀的问题
fileName := path.Base(url)
if !strings.Contains(fileName, ".png") {
fileName += ".png"
}
resp, err := http.Get(url)
if err != nil {
fmt.Println("A error occurred!")
return
}
defer resp.Body.Close()
reader := bufio.NewReaderSize(resp.Body, 32*1024)
file, _ := os.Create(BasePath + fileName)
writer := bufio.NewWriter(file)
written, _ := io.Copy(writer, reader)
fmt.Printf("Total length: %d\n", written)
}关键的main函数是
func main() {
fmt.Println("Spider Start: ------------------------------>")
html := getHtml(HuabanUrl)
for i := 0; i < PageNum + 1; i++ {
id := parsePage(html)
html = getHtml(nextPage(id))
}
fmt.Println("任务完成,共计下载:", count)
}运行截图
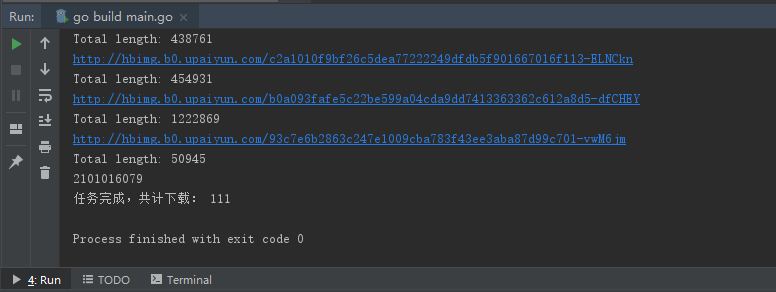
及成果截图(不是缩略图哦(●'◡'●))