This project allows for the usage of Keras on a jupter notebook in Nautilus (as an importable package). With this project, we are able to train keras models on the Nautilus cloud.
These instructions will get you a copy of the project up and running on your namespace.
Nautilus namespace Nvidia GPU
The project has the following components:
- Dockerfile (Dockerfile)
- Continous Integration Yaml (.gitlab-ci.yml)
- An example jupter notebook (ClassificationExample.ipynb)
- Nautilus deployment Yaml (kerasDeloyment.yaml)
This file is used to make the enviroment necessary to run Keras on Jupyter Notebook. Unless
truely needed, please avoid editing this file.
This file is used to utilize gitlab's continous integration feature. Nautilus uses kaniko instead of docker, which can be changed back into using a docker image by replacing the current .gitlab-ci.yml with the "dockerBased-ci.yml" file.
This was the notebook I used to train an wildfire classification model. The structure and import commands can be used to utilize keras in
other notebooks. I will go over the specific details below.
If you are planning to use this implementation on another Nautilus namespace, this portion of the readme is especially important. Here are the important aspects of this yaml:
-
Changing namespace address
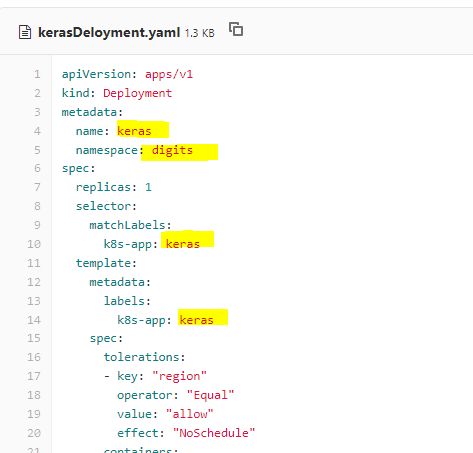
Change the name and the namespace entries to the current working namespace and a suitable name -
Change the resource requests
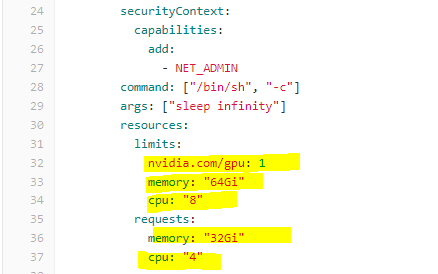
Change the numbers to suit the task -
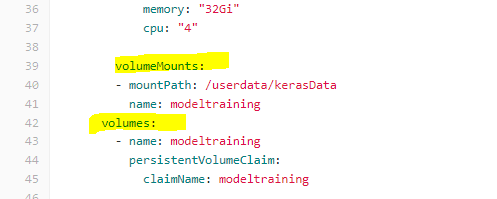
Mount volumne
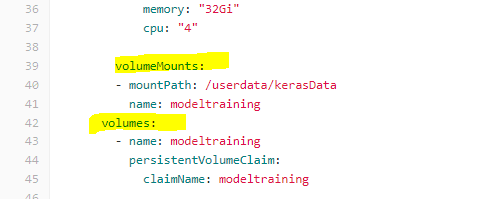
Very important for crash-resistance. I highly recommend saving all work onto mounted directory -
Choose GPU type
If doing intensive training, choose larger/more expensive GPUs




-
Go into kerasDeloyment.yaml file
-
Choose the RAW file format
-
copy url of RAW file
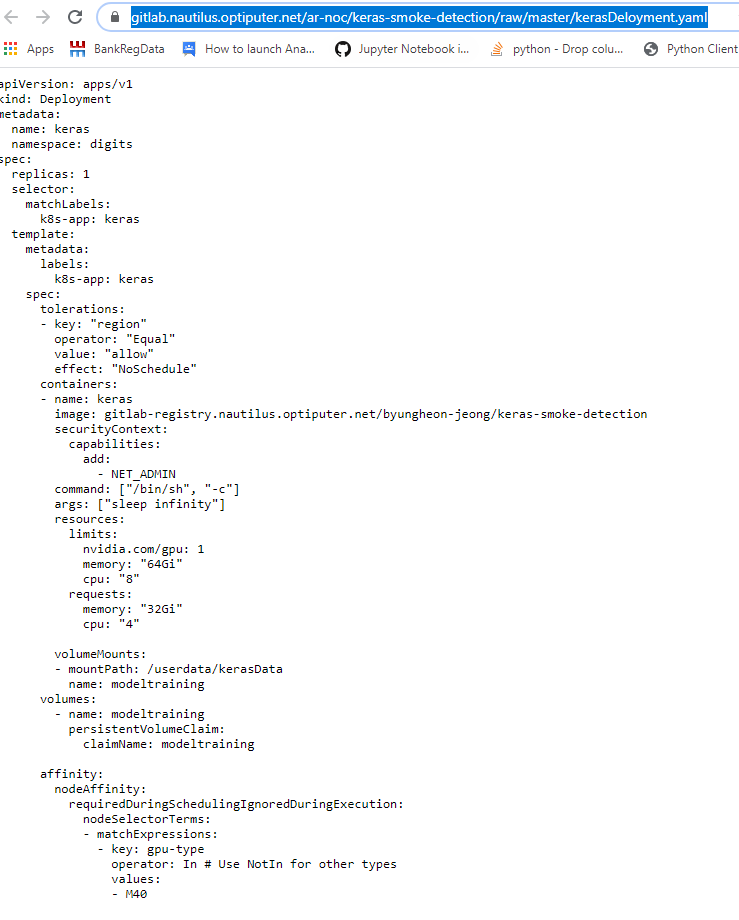
-
execute yaml file on nautilius namespace

-
exec into nautilus pod
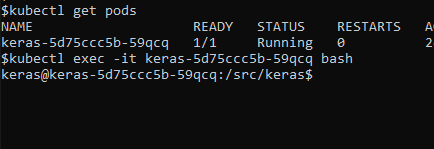
-
Navigate to /userdata/kerasData and Start Jupyter Notebook
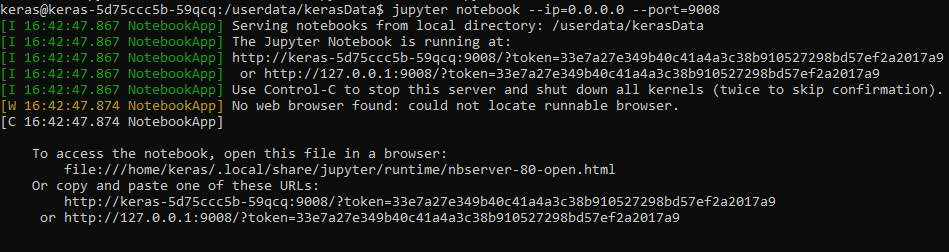
Note: The port number choice does not matter, as long as there are not other processes running on that port. If a port is already in use, jupyter will automatically assign another port. Make sure to match the port number in the next step

What happens when a wrong port is chosen -
Go to your computer terminal and start port-forward, matching the port in the pod

-
Go to the localhost address

-
Test for keras Create a new notebook or use the ClassificationExample.ipynb file








- Run the following tests
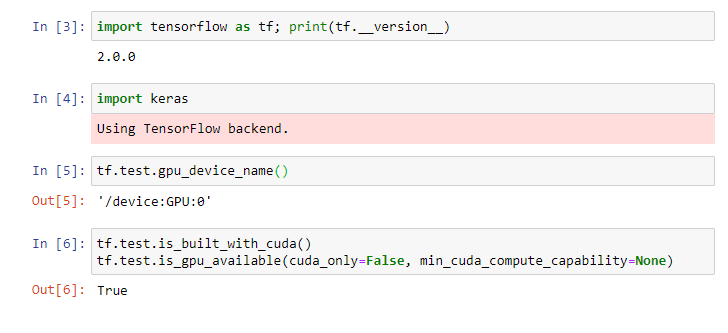

Make sure that the outputs return True or some name.
You are now ready to use Keras on a jupyter notebook hosted on Kubernetes
In order to prevent Keras from assigning too much GPU memory and stalling training efforts later on, run this:

If you see an error, shutdown the network server and try again

If you see nvidia-smi memory allocation at 0/- you have suceeded in reseting the GPU

Please refer to Keras Documentation for instructions and information
I used the notebook for the following:
- Training a CNN on the notebook for reference
- Using a LearningRateFinder to find the optimal learning rate
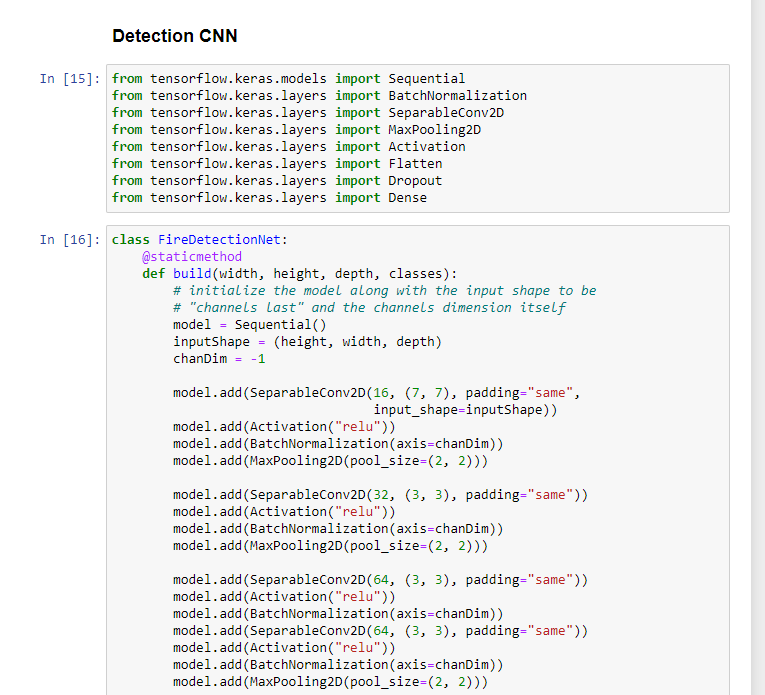
- Write the network using Keras layers
- Set the paths
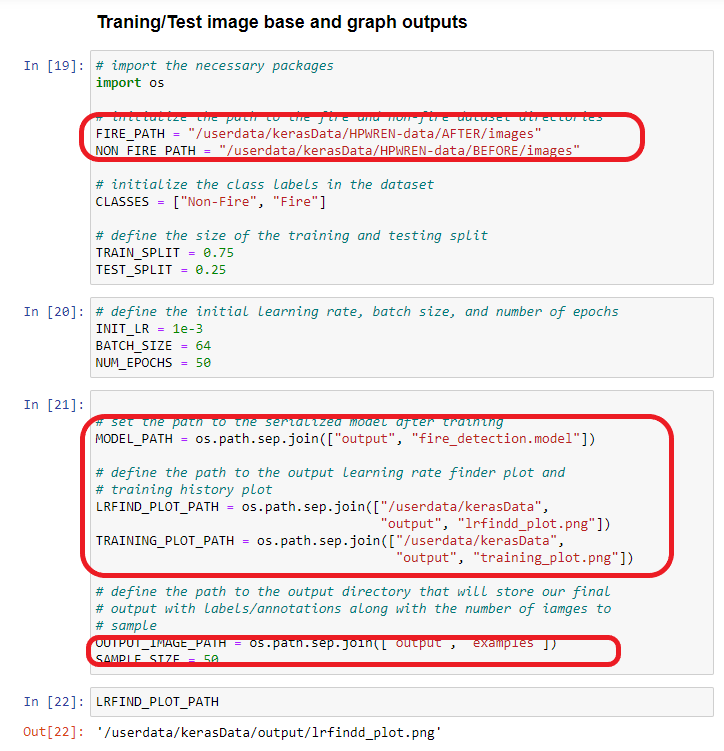
The following must be set


- FIRE_PATH = Path of the directory with the fire images
- Non_FIRE_PATH = Path of the directory with images without fire
- MODEL_PATH = Path where the saved model file should go
- LRFIND_PLOT_PATH = Where the learning rate finder graph should go
- TRAINING_PLOT_PATH = Where the training plot graph (loss & accuracy graphs) shoud go
- Loading Data There shouldn't be a need to edit this, unless another data loading solution is desired. This section also splits the data into training
- Image Load Tester Tests the images to see if the loading worked
- Model Initialization
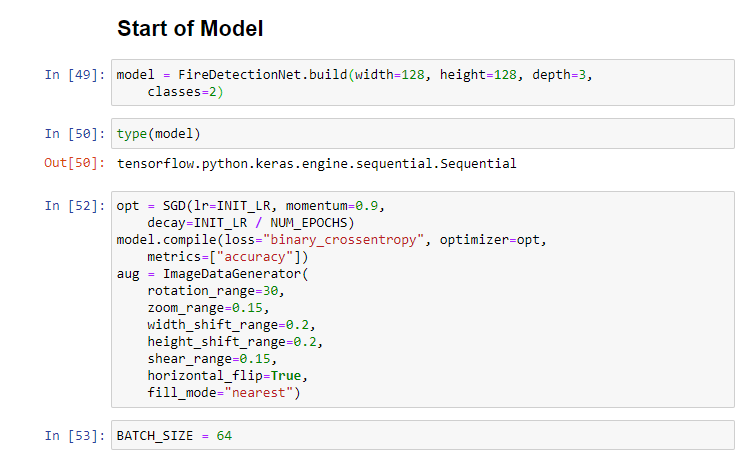

- The width, height and depth is the data format. Classes are the number of condiitons in the data. In our case: ["Fire", "Not-Fire"]
- Change the optimization function if you know what you are doing. We are using a starndard SDG
- Learning Rate Finder
Run to find the place where the Network starts to learn

More information is availbe here pyimagesearch


Finally, fill out the INIT_LR from what you learned from above

7. Train

8. Get results

You will find the accuracy measures in the table. Find the model in fire_detection.model
- Byungheon Jeong - byungheon-jeong
- Spence Chen - Spencer
- Isaac Nealey - Isacc
- John Graham - John
- The Dockerfile is from the Dockerhub of the Keras team
- The Fire CNN and the Learning Rate finder is adapted from Adrain's excellent blog on first-detection - Pyimagesearch