This was made as a part of Machine Learning course at IIIT,Delhi. Link to blog
We are using the GTZAN dataset which contains a total of 1000 audio files in .wav format divided into 10 genres. Each genre has 100 songs of 30-sec duration. Along with the audio files, 2 CSV files containing features of the audio files. The files contain mean and variance calculated over multiple features that can be obtained from an audio file. The other file has the same composition, but the songs were divided into 3-second audio files.

We convert every audio file to signals with a sampling rate to analyze its characteristics. Every waveform has its features in ttwo forms:
- Time domain- nothing much information about music quality can be extracted and explored apart from visual distinction in the waveforms


- Frequency domain which we get after fourier transform of two types: Spectral features and Rhythm features





MFCC and Rhythm feature plots provide a matrix based information for the unique features. Both the features have been mapped with the duration of the music file.
After extraction of features, all columns were not null. So extra values were not added. Why is it important to preprocess the data?
- The variables will be transformed to the same scale.
- So that all continuous variables contribute equally
- Such that no biased results
- PCA very sensitive to variances of initial variables If large variance range difference between features , the one with larger range will dominate
- The boxplots of each feature shows some features have very large differences in their variances.
- PCA with both normalisation(minMaxScaler) and standardisation(StandardScaler) is done and difference noted.
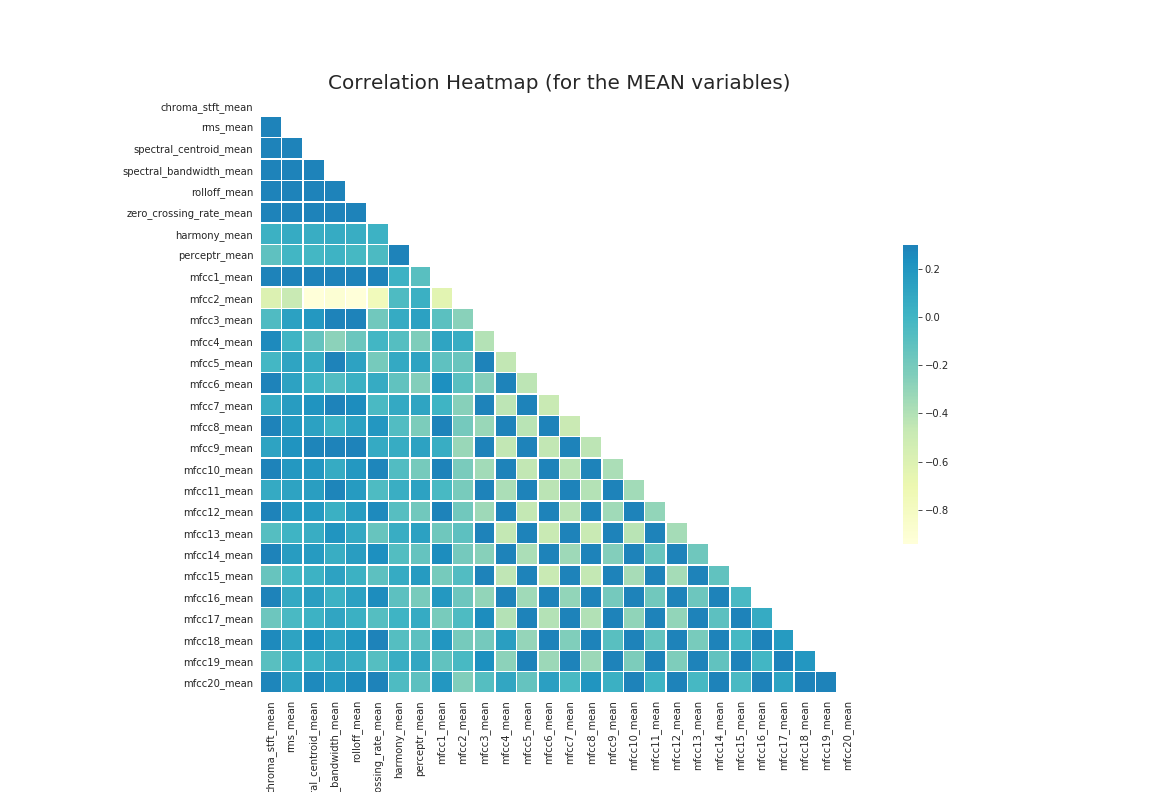
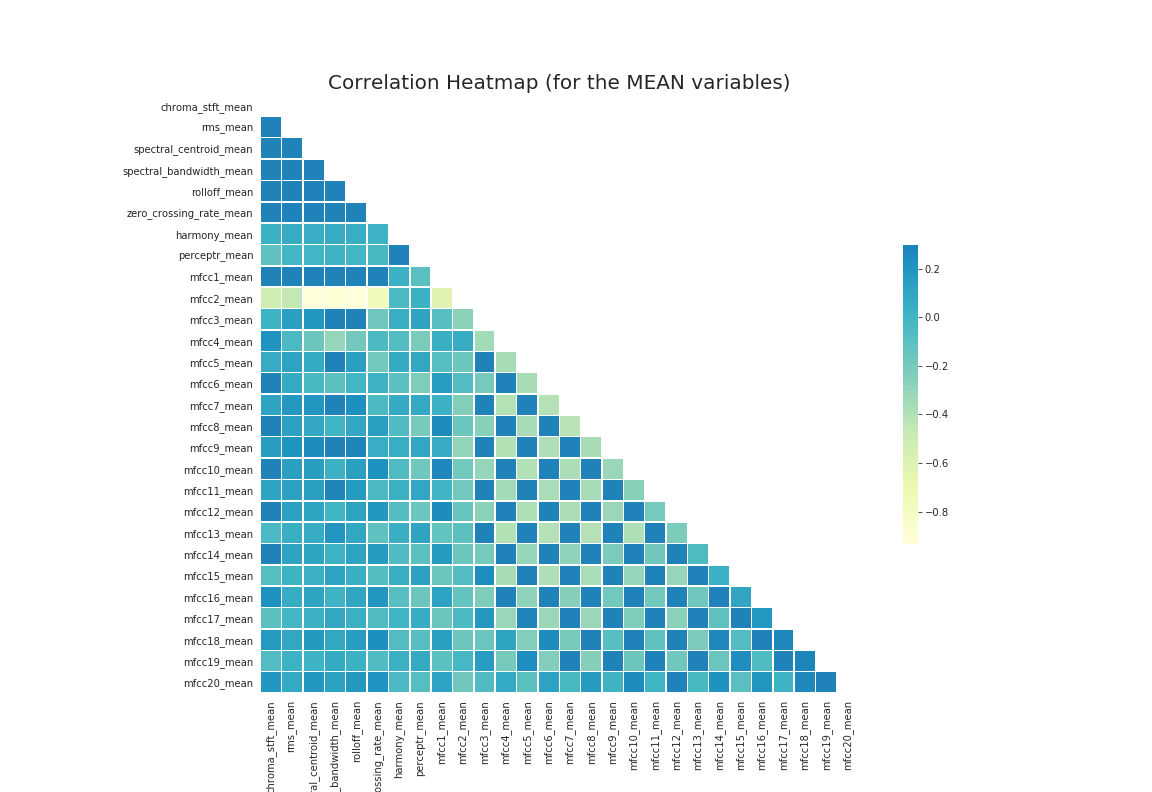
Feature extraction -> correlation matrix -> PCA
- With 30 secs sample

- With 3 secs sample

- Less outliers/ variance for some classes found in principal components:






- pca.explained_variance_ratio_=[0.20054986 0.13542712] Shows pc1 holds 20% percent of the data, pc2 holds 13% of the data
- Big clusters of metal , rock, pop ,reggae, classical can be seen.
- Jazz ,country, are separable to one extent.
- Hip-hop,disco,blues are very dispersed and can’t be seen
- Majority are easily separable classes
- Decided to proceed to modelling phase by using 3 sec sampled feature set with standardization as it aggregated the genres into more linearly separable clusters than normalisation
This model is a predictive analysis algorithm based on the concept of probability. GridSearchCV was used to pass all combinations of hyperparameters one by one into the model and the best parameters were selected.
Without Hyperparameter tuning:


| Metric | Value |
|---|---|
| Accuracy score | 0.67267 |
| Precision | 0.74126 |
| Recall | 0.74098 |
Using Hyperparameter tuning:


| Metric | Value |
|---|---|
| Accuracy score | 0.70504 |
| Precision | 0.70324 |
| Recall | 0.71873 |
Took SGD as baseline model and performed hyperparameter tuning for a better performance.Though difference werent that great even after HP tuning.
Without Hyperparameter tuning:

| Metric | Value |
|---|---|
| Accuracy score | 0.6126126126126126 |
| Precision | 0.6142479131341332 |
| Recall | 0.6172558275062101 |
With Hyperparameter tuning:


| Metric | Value |
|---|---|
| Accuracy score | 0.6441441441441441 |
| Precision | 0.6386137102787109 |
| Recall | 0.6421140902032518 |
We used a Simple Naive Bayes classifier, one vs Rest Naive Bayes as baseline models. Then used Hyperparameter testing to get better performance.
Without Hyperparameter tuning:


| Metric | Value |
|---|---|
| Accuracy score | 0.48598598598598597 |
| Precision | 0.4761542269197442 |
| Recall | 0.4902979078811803 |
With Hyperparameter tuning:


| Metric | Value |
|---|---|
| Accuracy score | 0.5155155155155156 |
| Precision | 0.49864157768533374 |
| Recall | 0.5050696700999591 |
This model almost outperformed compared to Gaussian NB models. As we can see , after HP tuning , correlation between the features has decreased, some had even 0 correlation.
Without Hyperparameter tuning:


| Metric | Value |
|---|---|
| Accuracy score | 0.8603603603603603 |
| Precision | 0.8594536380364758 |
| Recall | 0.8583135066852872 |
Using hyperparameter tuning :


| Metric | Value |
|---|---|
| Accuracy score | 0.9059059059059059 |
| Precision | 0.9073617032054686 |
| Recall | 0.905944266718195 |
Best params: {'metric': 'manhattan', 'n_neighbors': 1, 'weights': 'uniform'}
- Took DT as baseline model which didnt give great results, with accuracy around 65%.

| Metric | Value |
|---|---|
| Accuracy score | 0.637758505670447 |
| Precision | 0.6396387192624916 |
| Recall | 0.6376582879474517 |
- Used ADA boosting which reduced the performance(rock,pop,disco)

| Metric | Value |
|---|---|
| Best parameters | n_estimators=100 |
| Accuracy score | 0.5010006671114076 |
| Precision | 0.48730102839842837 |
| Recall | 0.4992406459587978 |
- Then gradient boosting which increased the accuracy exponentially.

| Metric | Value |
|---|---|
| Best parameters | n_estimators=100 |
| Accuracy score | 0.8238825883922615 |
| Precision | 0.8266806080093154 |
| Recall | 0.8232200760446549 |
- CatBoost was having high AUC for all genres unlike gradient which had low accuracy for some genres

- Cat boost outperformed ensemble methods. Gradient boost was close enough with 82% accuracy, rest all were in between 50-60%
| Metric | Value |
|---|---|
| Best parameters | loss function:”Multiclass” |
| Accuracy score | 0.8972648432288192 |
| Precision | 0.8979267969111706 |
| Recall | 0.8972734276109252 |
- As shown here RF was having around 80% accuracy but XGB boosting reduced the accuracy to 75%

| Metric | Value |
|---|---|
| Best parameters | n_estimators=1000 max_depth=10 |
| Accuracy score | 0.8038692461641094 |
| Precision | 0.805947955999254 |
| Recall | 0.8026467091527609 |
- Cross Gradient Boosting on Random Forest reduced the accuracy , it even reduced precision ,recall to large extent.

| Metric | Value |
|---|---|
| Best parameters | objective= 'multi:softmax' |
| Accuracy score | 0.7505003335557038 |
| Precision | 0.7593347049139745 |
| Recall | 0.7494976488750396 |
- Correlation matrix shows there is very less correlation among variables


- Best performed model among all DT and RF models with every genre was classified with atleast 85+% accuracy
- Genres like classical,hiphop had even 100% accuracy
- XGBoost improves upon the basic Gradient Boosting Method framework through systems optimization and algorithmic enhancements.
- Evaluations
| Metric | Value |
|---|---|
| Best parameters | learning rate:0.05, n_est =1000 |
| Accuracy score | 0.9072715143428952 |
| Precision | 0.9080431364823143 |
| Recall | 0.9072401472896423 |
This model is an Artificial Neural Network involving multiple layers and each layer has a considerable number of activation neurons. The primary training included random values of hyperparameters except the activation function . This initiation reflected overfitting in the data for different activation functions :

| Activation | Training Accuracy | Testing Accuracy |
|---|---|---|
| relu | 0.9887142777442932 | 0.5206666588783264 |
| sigmoid | 0.941428542137146 | 0.4970000088214874 |
| tanh | 0.9997143149375916 | 0.49266666173934937 |
| softplus | 0.9991428852081299 | 0.5583333373069763 |
From the following graph, we choose softplus to be the best activation function, considering softmax to be fixed for output
Upon looking the graph, we can conclude a very high variance in testing and training accuracy and so we know that our model is overfitting. In fact the testing loss starts to increase which indicates a high cross entropy loss. This will be dealt later. For now we see that softplus, relu and sigmoid, all 3 have performed similar on training and testing set thus we will go with softplus since it provides a little less variance than others.
- Learning rate
activation = softmax
no. of hidden layers = 3; neurons in each = [512,256,64]
activation of output layer is fixed to be softmax epochs = 100

| Learning Rate | Training Accuracy | Testing Accuracy |
|---|---|---|
| 0.01 | 0.4044285714626312 | 0.335999995470047 |
| 0.001 | 0.9888571500778198 | 0.5666666626930237 |
| 0.0001 | 0.9684285521507263 | 0.5513333082199097 |
| 0.00001 | 0.7134285569190979 | 0.4996666610240936 |
From the above graphs we see that 0.01 definitely results in over convergence and bounces as reflective from the accuracy graph. 0.001 has a very high variance and loss increases margianally with low acuracy so it isn't appropriate as well.
The best choice for alpha is either 0.0001 or 0.00001.
0.00001 has a relatively low variance and loss converges quickly with epochs but accuracy on training and testing set is pretty low.
0.0001 has a better performance but variance is very high
- no.of hidden layers
activation = softmax
learning rate = 0.0001
activation of output layer is fixed to be softmax epochs = 100

| Number of layers | Training Accuracy | Testing Accuracy |
|---|---|---|
| 2 | 0.9782857298851013 | 0.5383333563804626 |
| 3 | 0.9869999885559082 | 0.5443333387374878 |
| 4 | 0.9921428561210632 | 0.5506666898727417 |
In conclusion, increasing or decreasing the number of layers have no effect on variance. This is because we have too many neurons per layer. So we take 3 layers and reduce the number of neurons.
- Number of neurons
activation = softmax
learning rate = 0.0001
number of layers = 3
activation of output layer is fixed to be softmax epochs = 100
drop out probability = 0.3
alpha = 0.001

| Number of neurons | Training Accuracy | Testing Accuracy |
|---|---|---|
| [512, 256, 128] | 0.9984285831451416 | 0.563666641712188 |
| [256, 128, 64] | 0.915142834186554 | 0.5149999856948853 |
| [180, 90, 30] | 0.7991428375244141 | 0.503000020980835 |
| [128, 64, 32] | 0.6991428732872009 | 0.4900000095367431 |
Now for the same neuron set, we apply regularization and neuron dropout to find any change in the variance for high number of neurons with reducing the number of neurons
- regularization and decomposition

| Number of neurons | Training Accuracy | Testing Accuracy |
|---|---|---|
| [512, 256, 128] | 0.6759999990463257 | 0.5830000042915344 |
| [256, 128, 64] | 0.5278571248054504 | 0.5189999938011169 |
| [180, 90, 30] | 0.43642857670783997 | 0.4629999995231628 |
| [128, 64, 32] | 0.386428564786911 | 0.4203333258628845 |
So in conclusion, if we have high number of neurons per layer, then applying regularization techniques will increase the accuracy and decrease the variance overall. If we do not apply any regularization techniques then we can have moderate number of neurons to have a decent accuracy on training and testing set with low accuracy.
From all our analysis and extra experimentation we conclude our model with following metrics:
- activation : softmax
- learning rate : 0.0001
- number of hidden layers = 3
- number of neurons in each layer = [512,256,128]
- epochs = 100
- regularization and dropout true

Precision on the model : 0.5774000692307671
Recall on the model : 0.583
F1score on the model : 0.5801865223684216
Accuracy on the model : 0.6130000042915345

Even after hyperparameter tuning, the best accuracy is just above 60%. The reason is simply because of overfitting and underperformance due to inability to pick up each feature. This creates amazing accuracy on the training set but always misses out on the testing set.
This model outperformed every other model and gave the best accuracy. Manual hyperparameter tuning was done. Linear, polynomial and RBF kernel were compared using confusion matrix.


| Metric | Value |
|---|---|
| Best parameters | C=1.0,kernel='linear',random_state=0 |
| Accuracy score | 0.70672342343265456 |
| Precision | 0.7180431364823143 |
| Recall | 0.71234655872896242 |


| Metric | Value |
|---|---|
| Best parameters | C=1.0,kernel='poly',degree=7 |
| Accuracy score | 0.88242715143428952 |
| Precision | 0.8780431364823143 |
| Recall | 0.87035601472896557 |


| Metric | Value |
|---|---|
| Best parameters | C=200,kernel='rbf',gamma=4 |
| Accuracy score | 0.9424715143428952 |
| Precision | 0.939297323879391 |
| Recall | 0.9372401472896423 |
- SVMs performed the best among all classifiers with 94% accuracy
- Gaussian outperformed polynomial kernel in almost all iterations
- XGB classifiers were the best among all ensembling methods with 90% accuracy.
- Since genre classes were balanced , the tradeoff between precision and recall was less observed.
- Among all KNN,DT and ensemble classifiers , precision was more than recall
- While in case of LR,SGD,NB,MLP,SVM recall was observed more than precision.