The project is written in C# and uses ASP.NET Core - a cross-platform, high-performance, open-source framework. Currently supported storage is Azure Table Storage. The solution runs on Windows, MacOS and Linux.
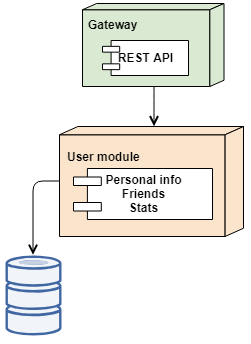
The current system is very simple. The achitecture is split into 3 layers vertically - the server or the gateway, business logic and storage (top-down). Since the current requirement is to handle a small amount of data at 15k+ requests per seconds, the data was modeled to be one table to make sure that every operation is achieved via 1-2 roundtrips to the storage.
User
- id: uuid
- name: string
- friends: uuid[]
- gamesPlayed: int
- highscore: int
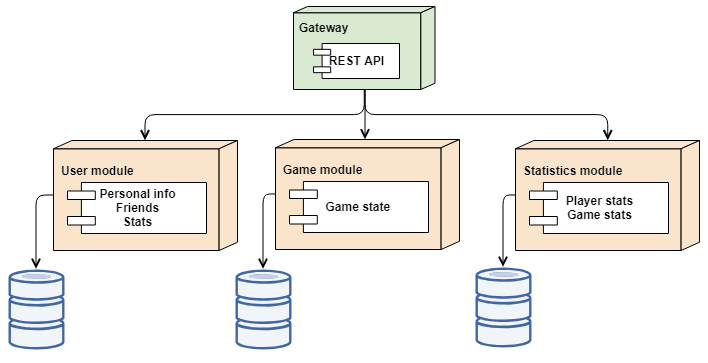
The current system is too simple for showing a full potential of the architecture. The figure above shows a possible future system, that could evolve once further requirements are known. The system is a monotlith but divided into separate modules. Each module has a single responsibility and own storage.
Eventually game state will likely be stored in another module responsible for coordinating games. The current state object doesn't really fit this description, because the current data - highscore and games played - is not a game state, but an aggregated statistic of an individual player. Thus the 2 fields are currently fields on user entity.
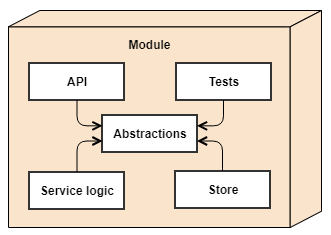
Each module is further broken down into several components. A typical module has 5 components, that are shown in the figure above. Abstractions contain the interfaces to the services the module provides, the data it accepts and returns, as well as interfaces to the storages the service is using. Service logic and the store implements those abstractions, while API and test components consume them. Modules also talk with one another, but only via the interfaces defined in the abstractions. No module can ever access other module internals, including know anything about the storage it uses.
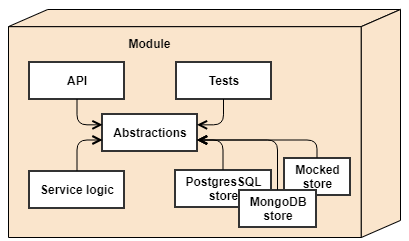
Abstractions can have multiple implementations. That is especially common for stores. It is typical to have a persistent store for production and development, while use in-memory or mock store for testing.
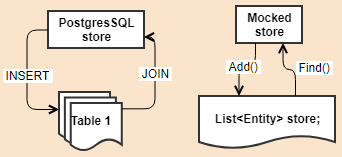
Storage entities and database technology are strictly encapsulated in the store implementations, where even the service logic doesn't know how the data it asks to save is stored. It can be stored as simply as an in-memory object reference in a list, or as complicated as a normalized data in a dozen of tables somewhere in the cloud.
The gateway server aggregates the modules into a monolith and exposes REST API to the public. The architecture, however, is extremely flexible. Modules get dependencies via dependency injection. Since dependencies are referenced via abstractions, actual implementations can be either a reference to an instance within the same module or a reference to a client library, which communicates with the dependency on another machine via REST or other form of RPC. Such architecture allows to run each module on individual machines if there is a need. All that will require little source code changes.
Given the scale requirements it is important to choose the right database technology to ensure the future scale. As a single developer I want a managed database service, that will allow me to focus on developing the application. As a result, setting up a database server in a VPS or a virtual machine is out of question. The friend of mine also wants a budget backend, which means any cloud hosted RDBMS is also out of question. A flavor of NoSQL data store seems to be the best option. I looked at three cloud providers - AWS, Google Cloud and Microsoft Azure.
SimpleDB is a high-available NoSQL data store. However, it has slow writes (up to 25 entries at a time) and tight limits, such as up to 1KB reads per request and up to 10GB of data storage per domain. That's a no-go.
DynamoDB is another AWS document store, but also with tight read/write limitations that are not too far away from the 15k+ requests per second. DynamoDB offers up to 10,000 capacity units per table and up to 20,000 capacit units per account (EU region). That will serve initially, but leaves no room for scale.
Cosmos DB is a document NoSQL store with infinite scale. It is globally distributed and ensures single-digit millisecond latencies at the 99th percentile. Accounts have no upper limit on throughput and support >10 million operations/s per table. By default all the data it stores is indexed providing superb query flexibility. It also provides a protocol compatibility with many other database systems, such as MongoDB, Cassandra, Table Storage, etc, which means favorite tools from other database vendors can be used to interact with Cosmos DB. It almost sounds too good to be true. However, it's pricing model is on the higher end. Cosmos DB charge for request units (RU) per collection. A minimum RU per collection costs approximately $25 per month. That is the main criteria making me look further.
Table Storage is a scalable key-value store designed for large data. A single account can handle up to 20,000 requests per second. A huge selling point of Table Storage is pricing - $0.07/GB per month and $0.00036 per 10,000 transactions for tables. Any type of operation against the storage is counted as a transaction, including reads, writes, and deletes. Cosmos DB supports Table Storage protocol, which makes moving from one to the other a trivial matter.
Cloud Datastore is a NoSQL document store similar to DynamoDB in terms of features, but closer to Cosmos DB in terms of throughput and scale. The pricing is $0.18/GB per month. All that makes it a very competitive choice for the project.
Azure Table Storage. It fits the current requirements and it allows to upgrade to a much more advanced Cosmos DB if more is needed. It was a hard choice between Table Storage and Google Cloud Datastore. However, multi-master, globally distributed, infinite throughput, everything is indexed Cosmos DB - can't say no to that. If not Cosmos DB I would have went with Google Cloud Datastore.
Install .NET Core 2.0.
cd src/SyboChallenge.Server.Gateway
dotnet restore
dotnet build
Every module contains a test project. The current source code doesn't have complex logic, therefore most of the tests are integration tests. Modules are tested in isolation. If it has a dependency service from another module, the test project provides mocked services.
To run tests run dotnet test from the root directory.
dotnet run
Visit http://localhost:50519/user to list the users.
You can also open the project in Visual Studio on MacOS or Windows, so that you don't need to do build, test and run steps from a command line.
Create a docker image: docker build -t sybo-gateway .
Run docker image: docker run -p 8080:80 sybo-gateway
SyboChallenge.Server.Gateway has Application Insights configured, which collects a lot of runtime information, such as API response times, unhandled exceptions, various machine parameters, etc. It is able to notice and inform any unusual activity, such as increased latency, increased number of certain HTTP status codes.
Architecturally the service is very well able to scale horizontally. However, the current database write routines were not written with concurrency control in mind. As a result, it is very much possible to end up with duplicate data when writing the database in parallel. For example, when resolving user by name, the user module first tries to find such user and inserts a new one if it doesn't exist. It is very possible that multiple instances will try to resolve the same name concurrently and both will insert a user with identical name. The race condition can be mitigated in several ways:
- Add a unique constraint at the database level. That will make the database server return a conflict error on duplicate insert. The application can handle such an error by either propagating the error all the way back to the client or by attempting to query an existing data in the database and continue the execution path as if the data was found at the very beginning.
- UPSERT instead of INSERT. Even though semantically UPSERT is different from approach #1, for immutable data, such as user names, it is practically the same.
Mutable data additionally has to control concurrent updates. A typical approach is to use an entity tag (ETag), which acts as data version. Updating data requires etag to be passed by the client, which indicates the revision of the data it is modifying. A conflict occurs if the revision in the database differs from the passed one.
The game client of this backend has a REST API design built-in and therefore dictates the design of the backend. I would like to propose to use a REST API standard, such as OData. OData stands for Open Data Protocol. It is an ISO/IEC approved, OASIS standard that defines a set of best practices for building and consuming RESTful APIs.
It offers several advantages over a custom made REST API, such as the one I built for the game client.
- It is an open standard and ensures consistent and clean API. Server OData libraries are able to validate the API to make sure that the registered endpoints and entity collections comply with the standard.
- It provides a machine-readable description of the data model of the API, called OData metadata. It enables the use of powerful generic client proxies and tools to consume the API. As an example, there are tools that can consume the metadata and generate API client code for dozens of programming language. On top of that, popular office suits, such as Microsoft Excel and LibreOffice Calc can use OData API as a data source.
- It provides a standardized query option syntax, which allow clients to tailor the requests and their responses to their needs. Such as specify data filters, ordering, paging, property selection and transformation, etc.
The REST API is available at: https://sybo-gateway.azurewebsites.net/