This part of the library has only be tested with Python3.6+.
There are few specific dependencies to install before launching a distillation,
you can install them with the command pip install -r requirements.txt.
Use data from SQuAD2.0
First, we will use file extract_json_to_csv.py export data in ./data from file .json to csv. The files will be split, use Microsoft Excel change from file.csv to file.xlsx and translate document in:
https://translate.google.com.vn/?hl=vi&tab=TT#view=home&op=docs&sl=en&tl=vi
and save at ./data/translate (use Microsoft Excel to merge small files together)
Because use translate so data willbe wrong.
Creat database in the format: (id, question, context, answer, answer_start, c_di, impossible): creat_database.py
Insert data from excel (translated) to database: Insert_excel_to_database.py
Finally, Use flask_edittext.py to Edit data wrong
Link: "http://ai.nccsoft.vn:6006/random/id"
Purpose: edit data (Here is: Context and Quesion) correct if translated wrong or not reasonable
After run flask_edittext.py
Interface:
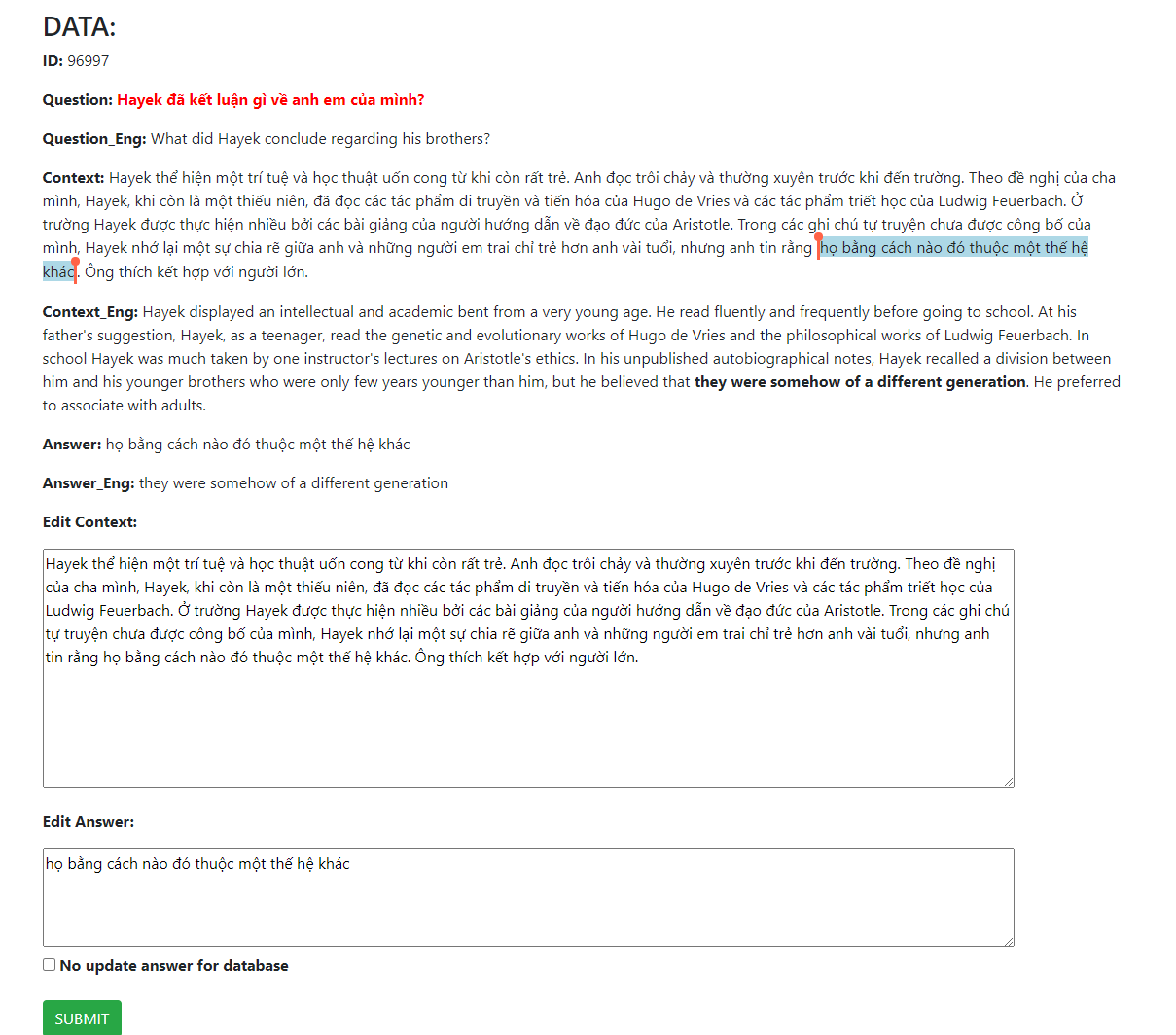
-
Question,Context,Answer: data has been translated fromQuestion_Eng,Context_Eng,Answer_Eng -
First, Check content of
Contextand collate withContext_Eng. If content reasionable, please not edit; else Edit atEdit_ConText -
Second, Use the slider bar (or edit directly at textarea of
Edit_Answer)to change the contentAnswer

- And content is changed display at textarea of
Edit Answer

- Collate with the answers highlighted in
Context_Engto ensure accuracy:

- Finally, click
Submitto savedatabase_train.db(table dataset_correction)
- If do not want save
Edit Answerto the database, tickNo update answer for database.