The official code for Rethinking the Distribution Gap of Person Re-identification with Camera-based Batch Normalization. It implements the fundamental idea of our paper: aligning all training and testing cameras. This code is based on an early version of Cysu/open-reid.
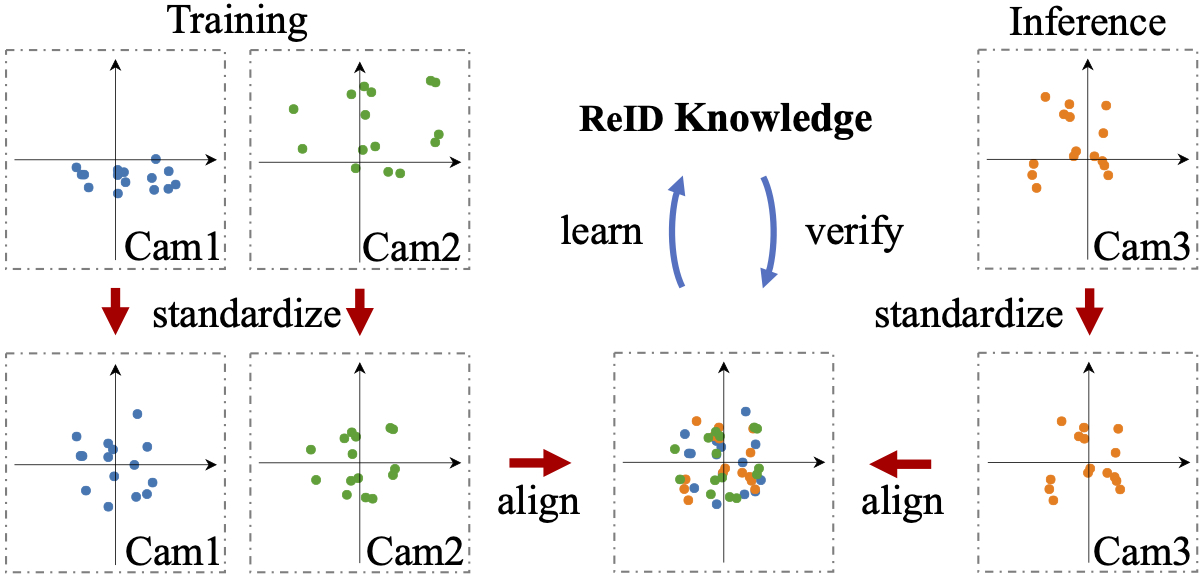
The goal of our code is to provide a generic camera-aligned framework for future researches. Thus, the fundamental principle is to make the entire camera alignment process transparent to the neural network and loss functions. To this end, we make two major changes.
First: we avoid customizing the BatchNorm layer. Otherwise, the forward process will require additional input for identifying camera IDs. Given that the nn.Sequential module is widely used in PyTorch, a customized BatchNorm layer will lead to massive changes in the network definition. Instead, we turn to use the official BatchNorm layer. For the training process, we can simply use the official BatchNorm implementation and feed the network with images from the same camera. In this stage, the collected running_mean and running_var are directly ignored since they will always be overridden in the testing stage. Thus, the BN parameter momentum can be set to any value. For the testing process, we change the default definition of BatchNorm layers from:
nn.BatchNorm2d(planes, momentum=0.1)to:
nn.BatchNorm2d(planes, momentum=None)Note:
In PyTorch, Momentum=None is not equivalent to Momentum=0.0. It calculates the cumulative moving average. Please check https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html for more details.
Then, given several mini-batches from a specific camera, we simply set the network to the Train mode and forward all these mini-batches. After forwarding all these batches, the running_mean and running_var in each BatchNorm layer are the statistics for this exact camera. Then, we simply set the network to the Eval mode and process images from this specific camera.
Second: during training, we need a process of re-organizing mini-batches. With a tensor sampled by an arbitrary sampler, we split this tensor by the corresponding camera IDs and re-organize them as a list of tensors. It is achieved by our customized Trainer. Then, our DataParallel forwards these tensors one by one, assembles all outputs, and then feeds them to the loss function in the same way of the conventional DataParallel.
1. Download Market-1501, DukeMTMC-reID, and MSMT17 and organize them as follows:
. +-- data | +-- market | +-- bounding_box_train | +-- query | +-- bounding_box_test | +-- duke | +-- bounding_box_train | +-- query | +-- bounding_box_test | +-- msmt17 | +-- train | +-- test | +-- list_train.txt | +-- list_val.txt | +-- list_query.txt | +-- list_gallery.txt + -- other files in this repo
Note: For MSMT17, we highly recommend the V1 version. Our experiments show that the noises introduced in the V2 version affect the performance of both the fully supervised learning and direct transfer tasks.
2. Install the required packages
pip install -r requirements.txtNote: Our code is only tested with Python3.
3. Put the official PyTorch ResNet-50 pretrained model to your home folder: '~/.torch/models/'
1. Train a ReID model
Reproduce the results in our paper
CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0 \
python train_model.py train --trainset_name market --save_dir='market_demo'Note that our training code also supports an arbitrary number of GPUs.
CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0,1,2,3 \
python train_model.py train --trainset_name market --save_dir='market_demo'However, since the current implementation is immature, the ratio of speedup is not good. Any advice about the parallel acceleration is welcomed.
2. Evaluate a trained model
CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0 \
python test_model.py test --testset_name market --save_dir='market_demo'To reproduce our reported performance, each experiment should be conducted 10 times.
You can download our trained models via Google Drive.
If you use our code in your paper, please kindly use the following BibTeX entry.
@inproceedings{zhuang2020rethinking,
title={Rethinking the Distribution Gap of Person Re-identification with Camera-Based Batch Normalization},
author={Zhuang, Zijie and Wei, Longhui and Xie, Lingxi and Zhang, Tianyu and Zhang, Hengheng and Wu, Haozhe and Ai, Haizhou and Tian, Qi},
booktitle={European Conference on Computer Vision},
pages={140--157},
year={2020},
organization={Springer}
}