
Effortlessly run LLM backends, APIs, frontends, and services with one command.
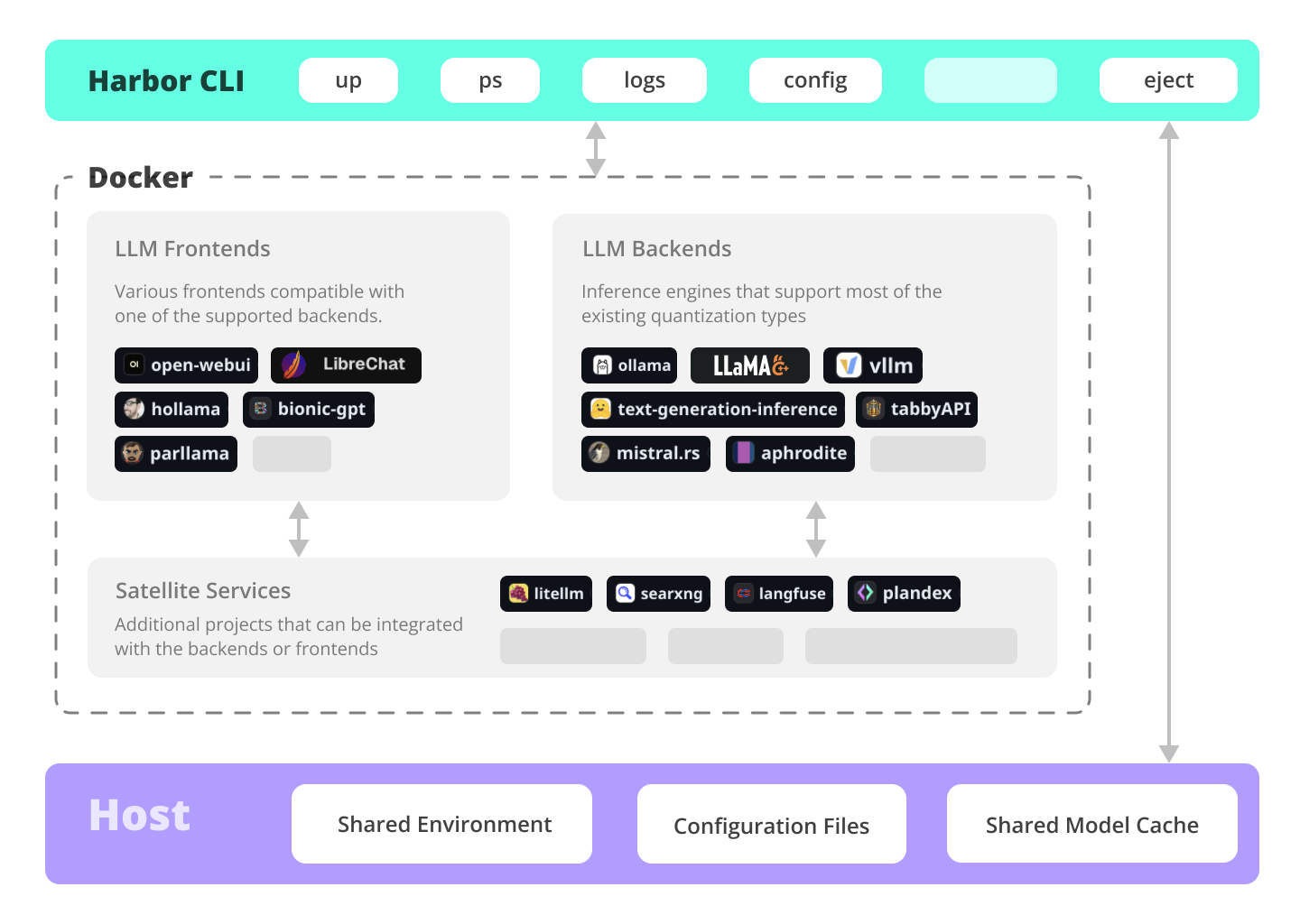
Harbor is a containerized LLM toolkit that allows you to run LLMs and additional services via a concise CLI.
# Run Harbor with additional services
# Running SearXNG automatically enables Web RAG in Open WebUI
harbor up searxng
# Run additional/alternative LLM Inference backends
# Open Webui is automatically connected to them.
harbor up llamacpp tgi litellm vllm tabbyapi aphrodite
# Run different Frontends
harbor up librechat bionicgpt hollama
# Use custom models for supported backends
harbor llamacpp model https://huggingface.co/user/repo/model.gguf
# Shortcut to HF Hub to find the models
harbor hf find gguf gemma-2
# Use HFDownloader and official HF CLI to download models
harbor hf dl -m google/gemma-2-2b-it -c 10 -s ./hf
harbor hf download google/gemma-2-2b-it
# Where possible, cache is shared between the services
harbor tgi model google/gemma-2-2b-it
harbor vllm model google/gemma-2-2b-it
harbor aphrodite model google/gemma-2-2b-it
harbor tabbyapi model google/gemma-2-2b-it-exl2
harbor mistralrs model google/gemma-2-2b-it
harbor opint model google/gemma-2-2b-it
# Convenience tools for docker setup
harbor logs llamacpp
harbor exec llamacpp ./scripts/llama-bench --help
harbor shell vllm
# Tell your shell exactly what you think about it
# courtesy of Open Interpreter
harbor opint
# Use fabric to LLM-ify your linux pipes
cat ./file.md | harbor fabric --pattern extract_extraordinary_claims | grep "LK99"
# Access service CLIs without installing them
harbor hf scan-cache
harbor ollama list
# Open services from the CLI
harbor open webui
harbor open llamacpp
# Print yourself a QR to quickly open the
# service on your phone
harbor qr
# Feeling adventurous? Expose your harbor
# to the internet
harbor tunnel
# Config management
harbor config list
harbor config set webui.host.port 8080
# Eject from Harbor into a standalone Docker Compose setup
# Will export related services and variables into a standalone file.
harbor eject searxng llamacpp > docker-compose.harbor.yml
# Gimmick/Fun Area
# Argument scrambling, below commands are all the same as above
# Harbor doesn't care if it's "vllm model" or "model vllm", it'll
# figure it out.
harbor vllm model # harbor model vllm
harbor config get webui.name # harbor get config webui_name
harbor tabbyapi shell # harbor shell tabbyapi
# 50% gimmick, 50% useful
# Ask harbor about itself
harbor how to ping ollama container from the webui?- Docker
- Optional NVIDIA Container Toolkit
- git
- bash-compatible shell
- Runs the install script directly from the internet (make sure you trust the source)
- Will clone the Harbor repository to your home directory
- Will write to your shell profile to add bin folder to the path
curl https://av.codes/get-harbor.sh | bashSame as above, just done by you.
git clone https://github.com/av/harbor.git && cd harbor
# [Optional] make Harbor CLI available globally
# Creates a symlink in User's local bin directory
# Adds the bin folder to the path
./harbor.sh ln
# Start default services
# Initial download of the docker images might take a while
# If you have container toolkit installed, GPU will
# be automatically used for supported services.
harbor up
# [Optional] open Webui in the browser
harbor openNote
First open will require you to create a local admin account. Harbor keeps auth requirement by default because it also supports exposing your local stack to the internet.
- Harbor CLI Reference
Read more about Harbor CLI commands and options. - Harbor Services
Read about supported services and the ways to configure them. - Harbor Compose Setup
Read about the way Harbor uses Docker Compose to manage services. - Compatibility
Known compatibility issues between the services and models as well as possible workarounds.
Open WebUI ⦁︎ LibreChat ⦁︎ HuggingFace ChatUI ⦁︎ Hollama ⦁︎ parllama, BionicGPT
Ollama ⦁︎ llama.cpp ⦁︎ vLLM ⦁︎ TabbyAPI ⦁︎ Aphrodite Engine ⦁︎ mistral.rs ⦁︎ openedai-speech ⦁︎ Parler ⦁︎ text-generation-inference ⦁︎ LMDeploy ⦁︎ AirLLM
SearXNG ⦁︎ Dify ⦁︎ Plandex ⦁︎ LiteLLM ⦁︎ LangFuse ⦁︎ Open Interpreter ⦁︎ cloudflared ⦁︎ cmdh ⦁︎ fabric ⦁︎ txtai RAG ⦁︎ TextGrad ⦁︎ Aider
- Convenience factor
- Workflow/setup centralisation
If you're comfortable with Docker and Linux administration - you likely don't need Harbor per se to manage your local LLM environment. However, you're also likely to eventually arrive to a similar solution. I know this for a fact, since I was rocking pretty much similar setup, just without all the whistles and bells.
Harbor is not designed as a deployment solution, but rather as a helper for the local LLM development environment. It's a good starting point for experimenting with LLMs and related services.
You can later eject from Harbor and use the services in your own setup, or continue using Harbor as a base for your own configuration.
This project consists of a fairly large shell CLI, fairly small .env file and enourmous (for one repo) amount of docker-compose files.
- Manage local LLM stack with a concise CLI
- Convenience utilities for common tasks (model management, configuration, service debug, URLs, tunnels, etc.)
- Access service CLIs (
hf,ollama, etc.) via Docker without install - Services are pre-configured to work together (contributions welcome)
- Host cache is shared and reused ⦁︎ Hugging Face, ollama, etc.
- Co-located service configs
- Eject to run without harbor with
harbor eject