Small Python utility which helps you parse and analyze the tweets from Twitter without using the twitter API. This script contain methods which helps you analyze the statistics of tweets including semantics using Deep Learning Recurrent Neural Network algorithms based on Keras, Theano, and/or TensorFlow.
Because the official Twitter API has restrictions on the quantities of API calls and the amount of tweets returned.
For parsing:
- Firefox;
- Selenium. To install run:
pip install selenium - NLTK (optional). To install:
pip install nltk
For Deep Learning:
- Keras. To install:
pip install keras - Theano. To install
pip install theano - h5py. To install:
pip install h5py - csv. To install:
pip install csv - numpy. To install:
pip install numpy
If you don't know what is pip, please, refer to documentation, or Github page.
First, clone the repository:
git clone https://github.com/pycckuu/non-api-twitter-parser.git
In command line open the folder and run python. In python shell import the module:
In [1]: import twitter_parserNow, go to the Twitter advanced search page and fill in form's fields in which you are interested in, hit 'Search' button. When the page is loaded you can adjust the parameters: for instance, you may select 'News' tab if you are interested in news related tweets. When everything is set and the Twitter advanced search page loads the desired result, you need to copy the URL address from your browser. Now, run the scrapper with the URI as a string:
In [2]: twitter_parser.scrape_page('https://twitter.com/search?f=news&vertical=news&q=water&src=typd&lang=en')It will load Firefox browser and perform scrolling of the page every 0.5 second to load new content. After some time, when you think that it is enough information on the Firefox page, you need to interrupt the script, select all the content in Firefox page (ctrl-A), copy it (ctrl-C) and paste the text (ctrl-V) into txt file, save txt-file in data folder (you may see as an example txt-files already saved there for you, don't forget to delete them before you start scrapping). You can perform this operation several times depending on your needs.
When all tweets of interest are saved into the data folder, you may run the parser:
In [3]: prsd_tweets = twitter_parser.parse_folder()By default, the script will search for text files in data folder, but you may specify any folder as input parameter for the method. The script will output some basic info about found files, total amount of parsed tweets and 50 most common words in tweets:
Found files
Data/dec13-dec6.txt
Data/dec17-dec14.txt
Data/dec30-dec18.txt
Data/dec5-nov30.txt
Total amount of tweets: 28069
Fifty most common words in tweets:
[('water', 30549), ('news', 3557), ('nov', 1703), ('flint', 1041), ('conservation', 958), ('drinking', 896), ('california', 815), ('crisis', 794), ('clean', 771), ('world', 754), ('watkins', 714), ('alyssa', 711), ('city', 710), ('hot', 692), ('climate', 668), ('video', 649), ('state', 624), ('drink', 611), ('drought', 606), ('supply', 602), ('yukohill', 574), ('health', 510), ('us', 508), ('flood', 508), ('energy', 485), ('levels', 481), ('global', 481), ('michigan', 479), ('food', 468), ('india', 452), ('main', 451), ('people', 447), ('wendy', 440), ('epa', 432), ('emergency', 427), ('change', 416), ('break', 416), ('floods', 403), ('air', 389), ('one', 360), ('finds', 359), ('tap', 359), ('power', 354), ('social', 353), ('uk', 350), ('first', 346), ('chennai', 346), ('home', 337), ('media', 335), ('today', 334)]
Also, script will return all parsed tweets into the variable prsd_tweets which is list of python dictionaries. The keys are
- 'id' = ID of the tweet;
- 'date' = date of the tweet as a datetime object;
- 'text' = message of the particular tweet as a string;
- 'emo' = sentiment: if '-1' - undefined. See 'Semantics'.
You may estimate daily count of words. You may pass words as a list and in this case the script will return the sum of words in the list as in example with ['world','global']:
In [4]: region = {}
In [5]: region['UK'] = twitter_parser.daily_count_words(['uk'], prsd_tweets)
In [6]: region['US'] = twitter_parser.daily_count_words(['us'], prsd_tweets)
In [7]: region['California'] = twitter_parser.daily_count_words(['california'], prsd_tweets)
In [8]: region['India'] = twitter_parser.daily_count_words(['india'], prsd_tweets)
In [9]: region['World'] = twitter_parser.daily_count_words(['world','global'], prsd_tweets)It is convenient to save the data as Pandas DataFrame:
In [10]: import pandas as pd
In [11]: df1 = pd.DataFrame(region)
In [12]: df1[-10:]The script will return the data frame (for instance last 10 elements):
| California | India | UK | US | World | |
|---|---|---|---|---|---|
| 2015-12-21 | 62 | 7 | 5 | 152 | 35 |
| 2015-12-22 | 60 | 2 | 28 | 154 | 27 |
| 2015-12-23 | 18 | 5 | 10 | 122 | 10 |
| 2015-12-24 | 7 | 5 | 8 | 94 | 15 |
| 2015-12-25 | 30 | 3 | 3 | 69 | 12 |
| 2015-12-26 | 26 | 12 | 42 | 95 | 41 |
| 2015-12-27 | 14 | 25 | 50 | 155 | 22 |
| 2015-12-28 | 19 | 13 | 49 | 152 | 27 |
| 2015-12-29 | 33 | 6 | 26 | 183 | 32 |
| 2015-12-30 | 7 | 1 | 4 | 47 | 8 |
And you can easily plot graphs:
In [12]: df1.plot(kind='area')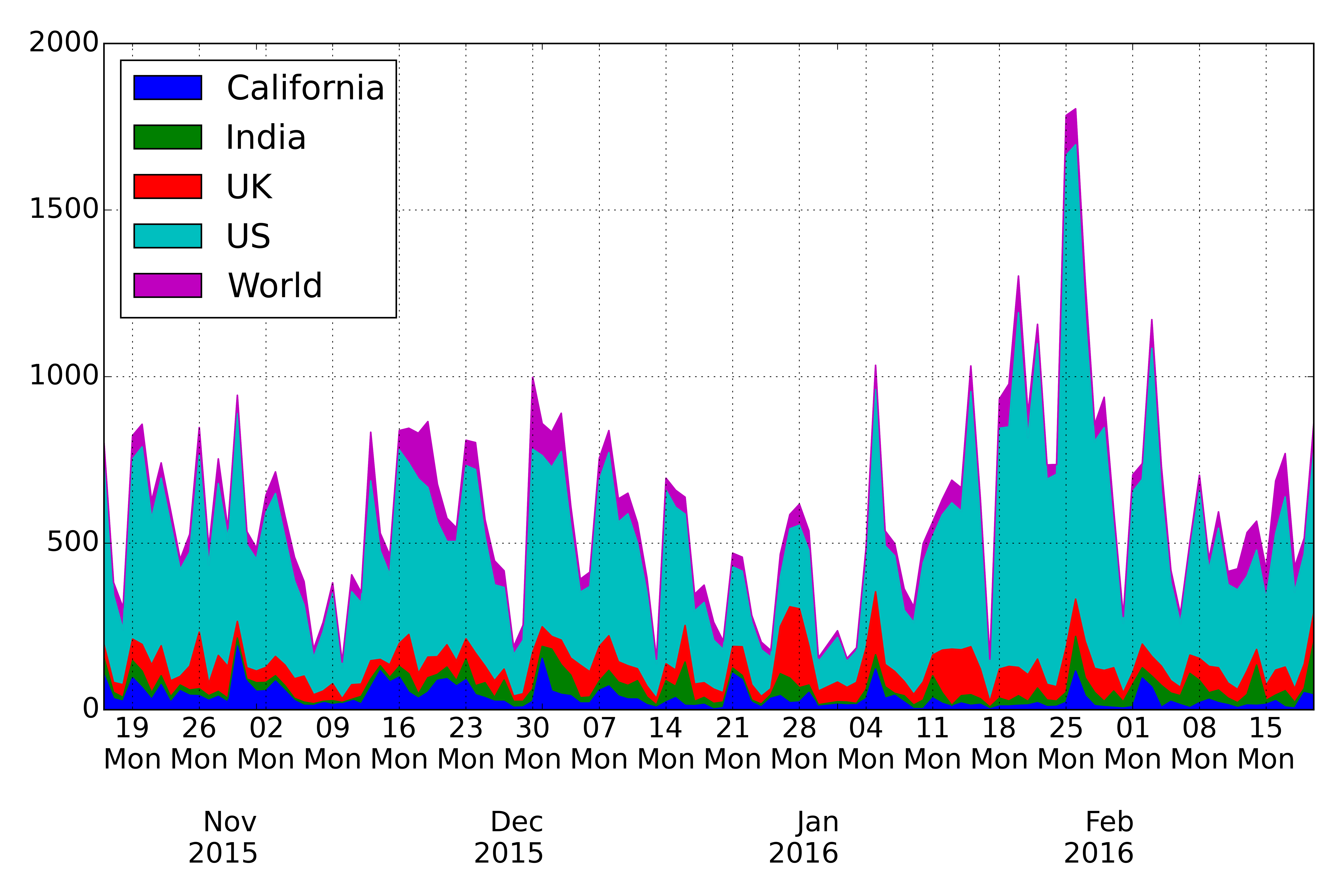
Now, you may perform the semantics analysis. Unzip the Stanford tweets database stanford_train_data.zip, which is in the folder of repository. Run the model:
In [13]: import twitter_semantics
In [14]: prsd_tweets, m = twitter_semantics.semantic_analysis(prsd_tweets)It will perform the training of neural network. If you don't want to wait long you may use already trained Keras weights. Download them using this link and put file in the repository root folder. Run the script again:
In [15]: prsd_tweets, m = twitter_semantics.semantic_analysis(prsd_tweets)The script will update the emo key of dictionaries prsd_tweets much faster without learning of the model. As the output you will see the following:
Found file 'weights.h5' in root folder
Running semantics analysis with preloaded weights
If you want to re-train the model, please, delete 'weights.h5' file and run this method again
For different weight file::: Please, pass the filepath as second argument
Reading Stanford Semantics Database
Found 1600000 entries
Preparing tweets
Compiling Keras model...
Loading Weights from file 'weights.h5'
Updating parsed tweets
Predicting sentiments...
[28068/28068]:100%
Now, to see that 'emo' key is updated, just run:
In [16]: prsd_tweets[0]this will output:
{'date': datetime.datetime(2015, 12, 13, 0, 0),
'emo': 0.5551493763923645,
'id': 0,
'text': 'Nutella, rice crackers, instant noodles, flavored mineral water, and breakfast biscuits are all on on the list... http://fb.me/72ugXjppE'}
You may count positive, tolerant and negative sentiment of the tweets containing list of words by:
In [17]: s = twitter_semantics.daily_count_semantics_for_words(['world','global'],prsd_tweets)It will count sentiment of the tweets containing words world and global. Again, for convenient use you may created the Pandas DataFrame:
In [18]: df_s = pd.DataFrame(s)
In [19]: df_s[-10:]You will see the result:
| negative | positive | tolerant | |
|---|---|---|---|
| 2015-12-21 | NaN | 37 | 36 |
| 2015-12-22 | NaN | 26 | 17 |
| 2015-12-23 | NaN | 13 | 20 |
| 2015-12-24 | NaN | 7 | 20 |
| 2015-12-25 | NaN | 11 | 6 |
| 2015-12-26 | NaN | 23 | 20 |
| 2015-12-27 | NaN | 37 | 30 |
| 2015-12-28 | NaN | 44 | 39 |
| 2015-12-29 | NaN | 37 | 23 |
| 2015-12-30 | NaN | 19 | 6 |
Now, you may build graphs of polarity of tweets:
In [20]: df_s.fillna(0, inplace=True)
In [21]: df_sa = pd.DataFrame()
In [22]: df_sa['Negative'] = df_s['negative']/(df_s['negative']+df_s['positive']+df_s['tolerant'])*100
In [23]: df_sa['Tolerant'] = df_s['tolerant']/(df_s['negative']+df_s['positive']+df_s['tolerant'])*100
In [24]: df_sa['Positive'] = df_s['positive']/(df_s['negative']+df_s['positive']+df_s['tolerant'])*100
In [25]: df_sa.plot(kind='area',colormap='winter')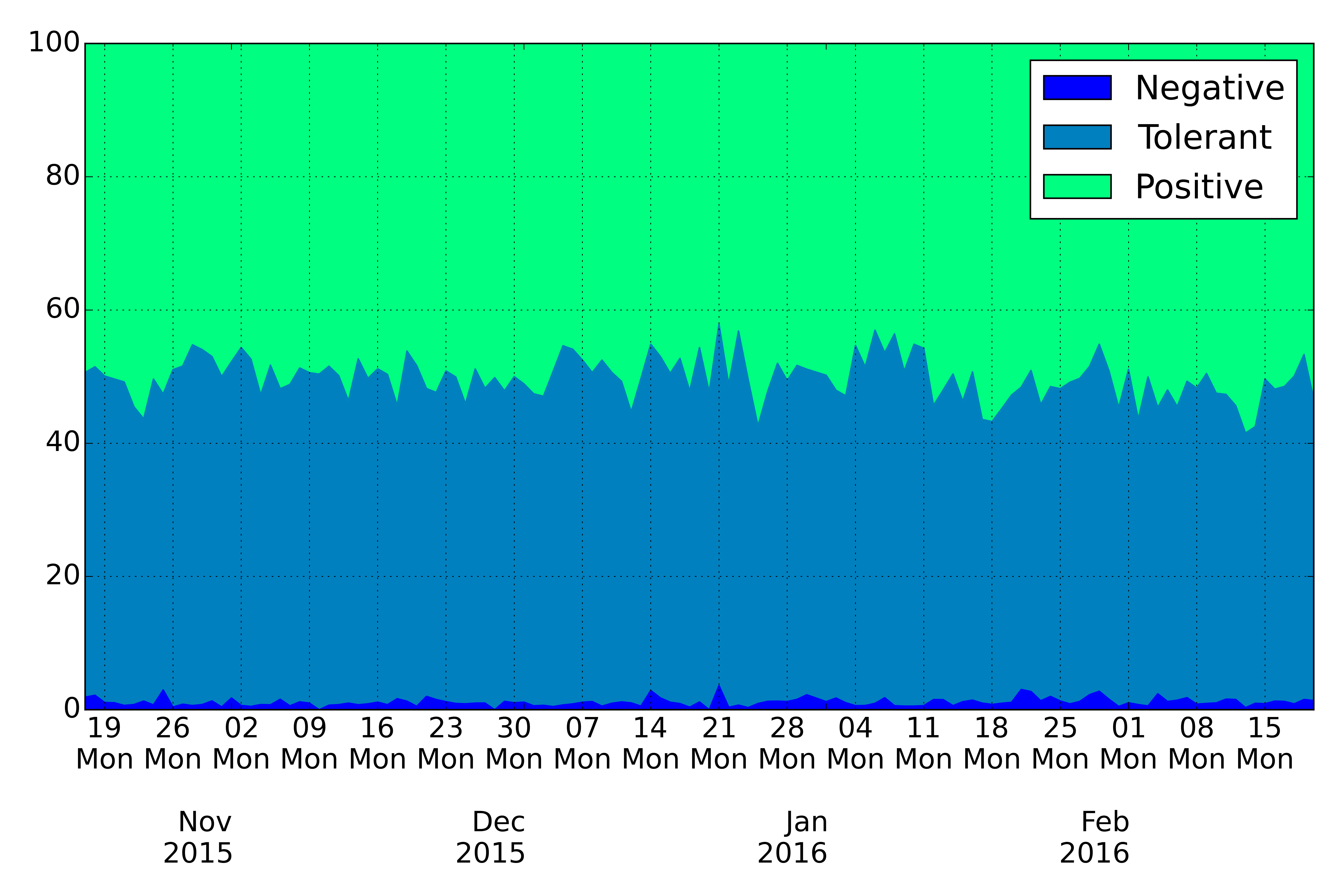
- It doesn't matter how many txt-files will be in data folder, the utility will load them all;
- The code of this example you may find in Jupyter (iPython) notebook Visualisation.ipynb.
- You may exclude words, which are in the Brown Corpus of NLTK library, from most common word counting. you need to to install NLTK (
pip install nltk), download the Brown Corpus dictionary:
In [26]: import nltk
In [27]: nltk.download()Select The Brown dictionary and download it. Then, you may run parsing method:
In [28]: prsd_tweets = twitter_parser.parse_folder(nltk_lib=True)Please, contact me, if you know how to improve or have ideas about some cool features. Generally, I expect collaborators to create the pull request with new feature/improvement!
Copyright (c) 2016 Igor Markelov
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.