Optimize nested data query performance on Amazon S3 data lake or Amazon Redshift data warehouse using AWS Glue
The bulk of the of the data generated today is unstructured and, in many cases, composed of highly complex, semi-structured and nested data. Decision makers in every organization need fast and seamless access to analyze these data sets to gain business insights and to create reporting. Amazon Redshift, a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing Business Intelligence (BI) tools, allows you to query petabytes of structured and semi-structured data across your data warehouse and your data lake.
As an example of a highly nested json file that uses multiple constructs such as arrays and structs, we are using an open data set from the New York Philharmonic performance history repository. A sample json snippet from this data set illustrates below an array of structs, with multiple nesting levels:
{
"programs": [{
"id": "46ba9c05-6400-4337-96a1-95a91ae0f330-0.1",
"programID": "10254",
"orchestra": "New York Symphony",
"season": "1926-27",
"concerts": [{
"eventType": "Subscription Season",
"Location": "Manhattan, NY",
"Venue": "Carnegie Hall",
"Date": "1926-10-02T05:00:00Z",
"Time": "8:30PM"
}],
"works": [{
"ID": "10208*",
"composerName": "Low,",
"workTitle": "INTERNATIONAL",
"conductorName": "Shaeffer, Joseph",
"soloists": [{
"soloistName": "Freiheit Gesangs Farein of New York",
"soloistInstrument": "Chorus",
"soloistRoles": "S"
}]
},
{
"ID": "10209*",
"composerName": "Edelshtadt,",
"workTitle": "VACHT UF",
"conductorName": "Shaeffer, Joseph",
"soloists": [{
"soloistName": "Freiheit Gesangs Farein of New York",
"soloistInstrument": "Chorus",
"soloistRoles": "S"
}]
}
]
}]
}
AWS blog posts on nested JSON with Amazon Athena and Amazon Redshift Spectrum cover in great detail on how to efficiently query such nested dataset . Here, we’ll describe an alternate way of optimizing query performance for nested data ensuring simplicity, ease of use, and fast access for end-users, who need to query their data in a relational model without having to worry about the underlying complexities of different levels of nested unstructured data.
We use AWS Glue, a fully managed serverless extract, transform, and load (ETL) service, which helps to flatten such complex data structures into a relational model using its relationalize functionality, as explained in this AWS Blog. Here, we will expand on that and create a simple automated pipeline to transform and simplify such a nested data set.
Let us now describe how we process the data. The following architecture diagram highlights the end-to-end solution. We build an AWS Glue Workflow to orchestrate the ETL pipeline and load data into Amazon Redshift in an optimized relational format that can be used to simplify the design of your dashboards using BI tools like Amazon QuickSight:

Below is the simple execution flow for this solution, which you may deploy with CloudFormation template:
- The source data is ingested into Amazon S3.
- At a scheduled interval, an AWS Glue Workflow will execute, and perform the below activities:
a) Trigger an AWS Glue Crawler to automatically discover and update the schema of the source data.
b) Upon a successful completion of the Crawler, run an ETL job, which will use the AWS GlueRelationalizetransform to optimize the data format. When a data structure includes arrays, the relationalize transform extract these as separate tables and adds all the necessary keys to join back to the parent table. This job also loops through the tables and standardizes the table and column names. Optionally, it also joins the columns together in a wide, fully denormalized table.
c) As a final step, it loads the data into an Amazon Redshift Cluster, and also into an Amazon S3 data lake in columnar file format, Apache Parquet. - Now, we can visualize the data in Redshift or Athena with simple SQL queries.
Once the stack is successfully deployed, you can review and then launch your ETL pipeline
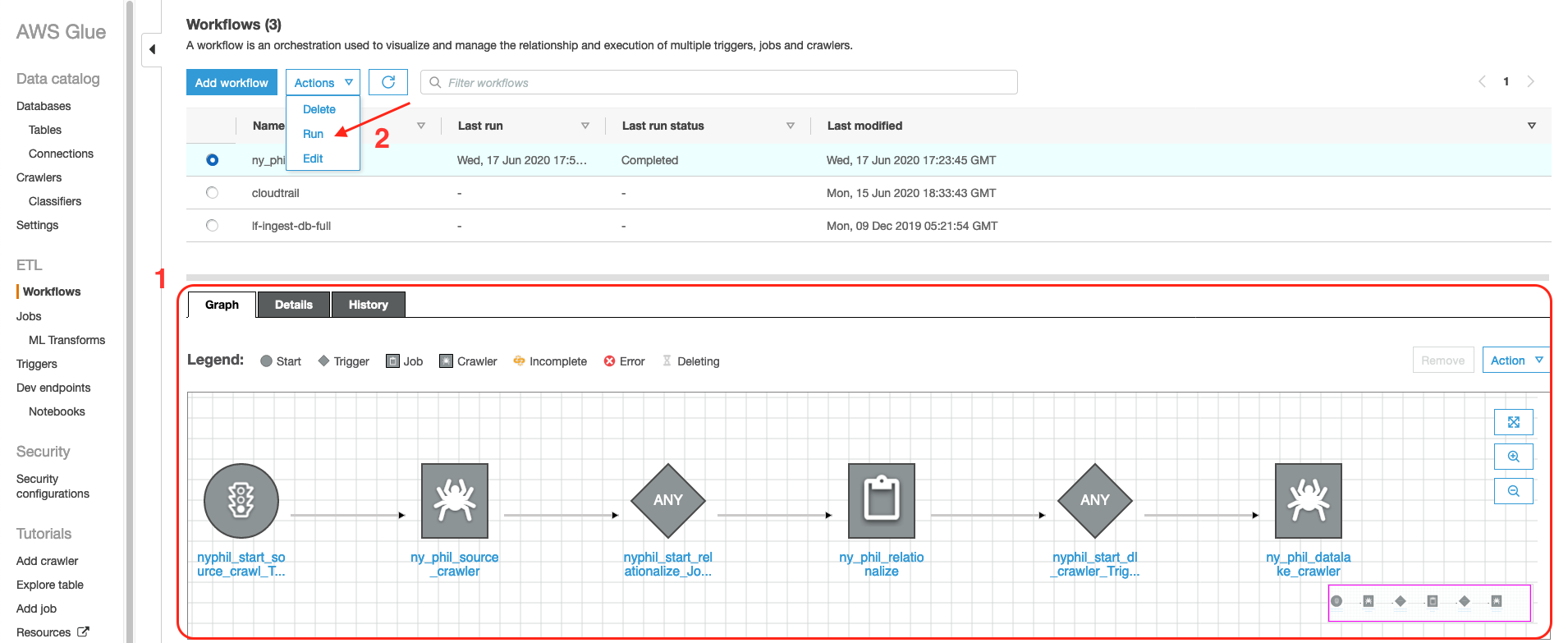
- Log in to the AWS Glue console.
- Choose Workflows , select the workflow created by the AWS Cloudformation stack (ny_phil_wf), and then review the Graph and the various steps involved.
- Run the workflow.
- Visualize data with simple SQL queries to analyze answer to questions like “Who were the top three Chorus soloists at New York Symphony?”

SELECT count(1) event_count,
s.soloistname
FROM ny_phil.programs p
INNER JOIN ny_phil.programs_works w
ON p.programs_works_sk = w.programs_works_sk
INNER JOIN ny_phil.programs_works_soloists s
ON w.programs_works_soloists_sk = s.programs_works_soloists_sk
WHERE p.orchestra = 'New York Symphony'
AND s.soloistinstrument = 'Chorus'
AND s.soloistroles = 'S'
GROUP BY s.soloistname
ORDER BY 1 DESC
LIMIT 3;

See CONTRIBUTING for more information.
This library is licensed under the MIT-0 License. See the LICENSE file.