Prerequisite:
- Amazon Bedrock model access
- Deploy Embedding and Text Generation Large Language Models with SageMaker JumpStart
- Create OpenSearch Domian. This solution uses IAM as master user for fine-grained access control.
This example notebook guides you through the process of utilizing Amazon Textract's layout feature. This feature allows you to extract content from your document while maintaining its layout and reading format. Amazon Textract Layout feature is able to detect the following sections:
- Titles
- Headers
- Sub-headers
- Text
- Tables
- Figures
- List
- Footers
- Page Numbers
- Key-Value pairs
Here is a snippet of Textract Layout feature on a page of Amazon Sustainability report using the Textract Console UI:

The Amazon Textract Textractor Library is a library that seamlessly works with Textract features to aid in document processing. You can start by checking out the examples in the documentation. This notebook utilizes the Textractor library to interact with Amazon Textract and interpret its response. It enriches the extracted document text with XML tags to delineate sections, facilitating layout-aware chunking and document indexing into a Vector Database (DB). This process aims to enhance Retrieval Augmented Generation (RAG) performance.

-
Upload multi-page document to Amazon S3.
-
Call Amazon Textract Start Document Analysis api call to extract Document Text including Layout and Tables. The response provides structured text aligned with the original document formatting and the pandas tables of each table detected in the document.
-
Enrich this extracted text further with XML tags indicating semantic sections, adding contextual metadata through the Textractor library.
-
The textrcat library extracts tables in plain text, maintaining their original layout. However, for improved processing and manipulation, it's advisable to convert them to CSV format. This method replaces the plain text tables with their CSV counterparts obtained from Textract's table feature.
-
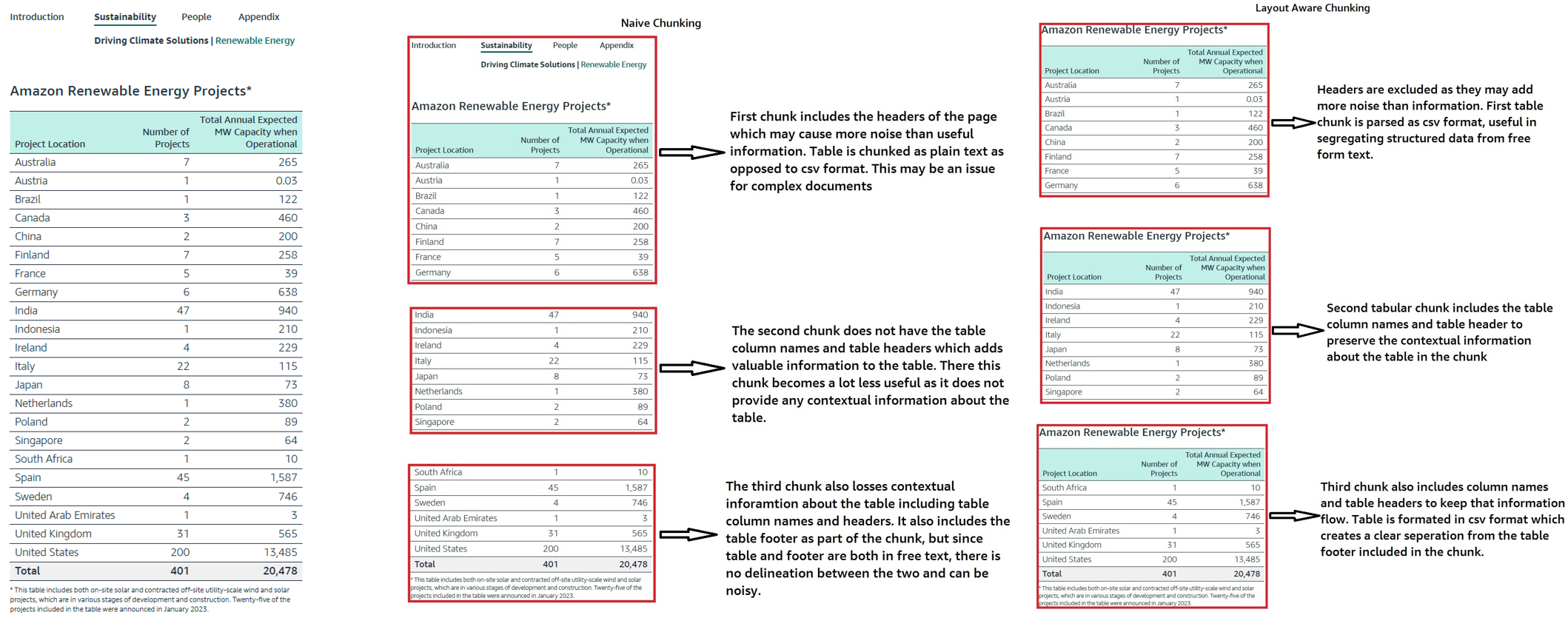
In this approach, the extracted text is segmented based on document title sections, the highest hierarchy level in a document. Each subsection within the title section is then chunked according to a maximum word threshold. Below outlines our approach to handling the chunking of subsection elements.:
- Tables: Tables are chunked row by row until the maximum number of alphanumeric words is reached. For each table chunk, the column headers are added to the table along with the table header, typically the sentence or paragraph preceding the table in the document. This ensures that the information of the table is retained in each chunk.
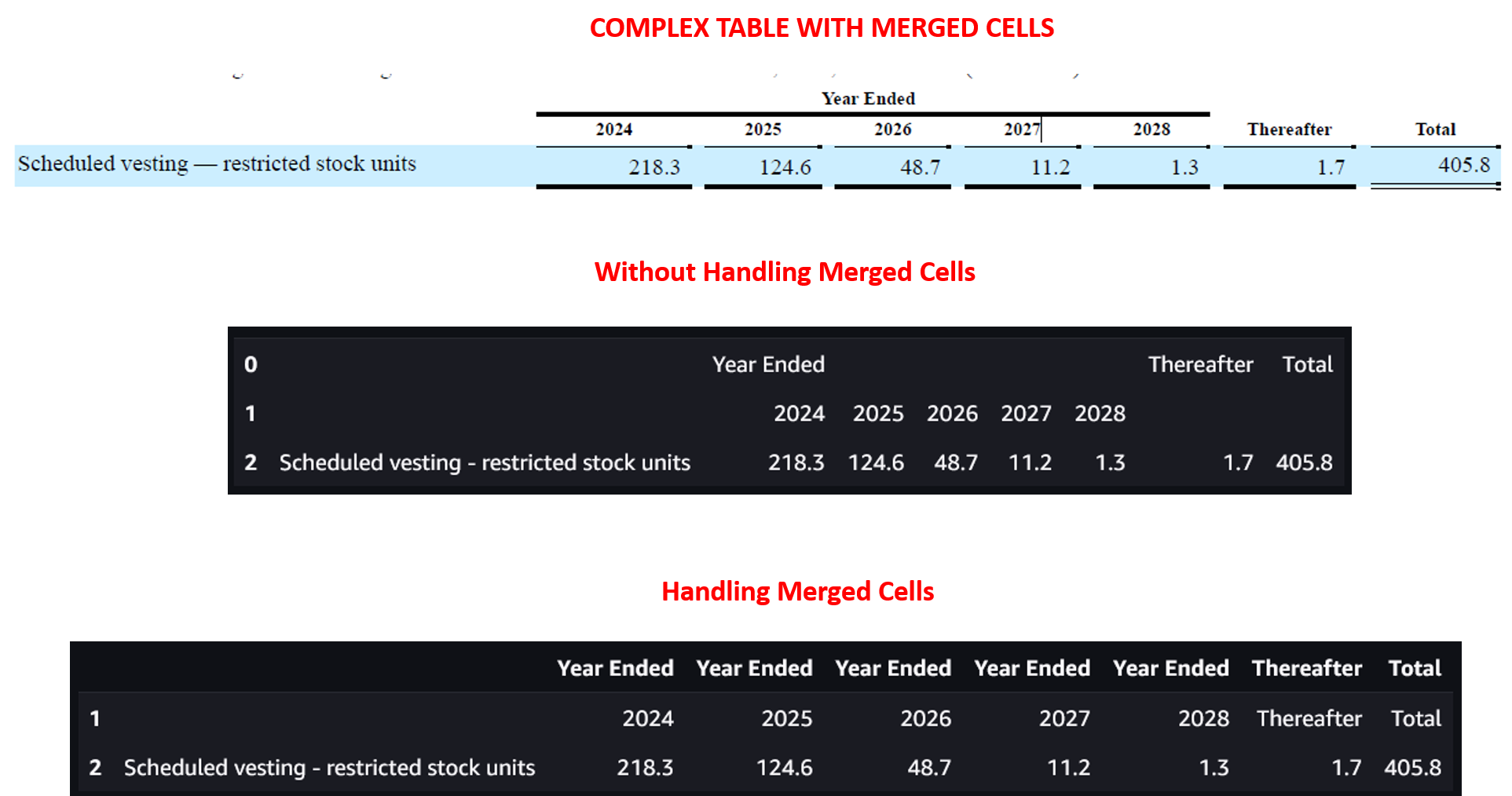
To handle tables with merged cells, this solution first unmerges any merged cell ranges, then duplicates the original merged cell value into each of the corresponding individual cells after unmerging.
- List: Chunking lists found in documents can be challenging. Naive chunking methods often split list items by sentence or newline characters. However, this approach presents issues as only the first list chunk typically contains the list title, which provides essential information about the list items. Consequently, subsequent list chunks become obsolete. In this notebook, lists are chunked based on their individual list items. Additionally, the header of the list is appended to each list chunk to ensure that the information of the list is preserved in each chunk.

- Section and subsection: The structure of a document can generally be categorized into titles, sections, and paragraphs. A paragraph is typically the smallest unit of a document that conveys information independently, particularly within the context of a section or subsection header. In this method, text sections are chunked based on paragraphs, and the section header is added to each paragraph chunk (as well as tables and lists) within that section of the document.

-
We save (in S3, but can be any other database) the corresponding header section and chapter of the chunks, to create a child-parent-grandparent hierarchy (chunk-section-chapter). This sets the foundation for implementing advanced retrieval techniques like Small2Big, Graph query etc. Metadata is appended to each respective chunk during indexing, encompassing:
- The entire CSV tables detected within the chunk.
- The section header ID associated with the chunk.
- The section title ID linked to the chunk.
When retrieving a passage based on hybrid search (combining semantic and text matching), there's flexibility in the amount of content forwarded to the LLM. Some queries may necessitate additional information, allowing users to choose whether to send the corresponding chunk section header or section chapter based on the specific use case.





In the RAG process, we retrieve the top K=n similar passages from the Vector Database (Amazon OpenSearch Service). Subsequently, we generate a prompt template using any hierarchical section of the retrieved passages, indexed as metadata. This flexibility allows us to adjust the quantity of information forwarded to the LLM, facilitating the generation of contextual answers.