- Overview
- Architecture Details
- Disclaimer
- Prerequisites
- Quick Start
- Advanced Configuration
6.1. Optional CloudFormation Parameters - Module Information
7.1 LangChain Orchestrator - FAQ
- Security
- License
In this implementation we demonstrate how to implement a RAG workflow by combining the capabilities of Amazon Kendra with LLMs to create state-of-the-art GenAI ChatBot providing conversational experiences over your enterprise content. To restrict the GenAI application responses to company data , we need to use a technique called Retrieval Augmented Generation (RAG). An application using the RAG approach retrieves information most relevant to the user’s request from the enterprise knowledge base or content, bundles it as context along with the user’s request as a prompt, and then sends it to the LLM to get a GenAI response. LLMs have limitations around the maximum word count for the input prompt, therefore choosing the right passages among thousands or millions of documents in the enterprise, has a direct impact on the LLM’s accuracy. In this particular repository we are going to provide implementation details to deploy a serverless chatbot which can scale to several users, maintain conversational memory, provide source links, has variety of orchestrators which provide multiple ways of Lambda implementation; Simple and Advanced Agents Lambda implemetation with Query rephrasing or disambiguation

The workflow includes the following steps:
-
Financial documents and agreements are stored on Amazon S3, and ingested to an Amazon Kendra index using the S3 data source connector.
-
The LLM is hosted on a SageMaker endpoint.
-
An Amazon Lex chatbot is used to interact with the user via the Amazon Lex web UI. Lex UI can leverage cognito to authentice users.
-
The Amazon DynamoDB is used to hold conversational memory.
-
The solution uses an AWS Lambda function with LangChain to orchestrate between Amazon Kendra, Amazon DynamoDB, Amazon Lex, and the LLM.
-
When users ask the Amazon Lex chatbot for answers from a financial document, Amazon Lex calls the LangChain orchestrator to fulfill the request.
-
Based on the query, the LangChain orchestrator pulls the relevant financial records and paragraphs from Amazon Kendra or pull the information from conversational memory in DynamoDB.
-
The LangChain orchestrator provides these relevant records to the LLM along with the query and relevant prompt to carry out the required activity.
-
The LLM processes the request from the LangChain orchestrator and returns the result.
-
The LangChain orchestrator gets the result from the LLM and sends it to the end-user through the Amazon Lex chatbot.
-
When selecting websites to index, you must adhere to the Amazon Acceptable Use Policy and all other Amazon terms. Remember that you must only use Amazon Kendra Web Crawler to index your own web pages, or web pages that you have authorization to index. To learn how to stop Amazon Kendra Web Crawler from indexing your website(s), please see Configuring the robots.txt file for Amazon Kendra Web Crawler. Abusing Amazon Kendra Web Crawler to aggressively crawl websites or web pages you don't own is not considered acceptable use.
Acceptable usage Policy : https://docs.aws.amazon.com/kendra/latest/dg/data-source-web-crawler.html https://github.com/aws-samples/aws-lex-web-ui/tree/master
-
If you are using Lex Web UI always secure your chat UI with Authentication by setting .

-
Place to help with this in case of RAG use case is to use lower number of max documents, say 1 because Huggingface has a smaller token limit. Apart from that, currently we expect the user to be responsible for the token limit per the model they select. But we're considering options like rolling window of conversation, so we removed old chat conversations from the history - this would then be an additional option in the rapid-ai wizard to select how many historical conversations you want to keep in memory. This would enable users to have longer conversations before the token limit creates issues. However this feature is not implemented yet..
-
Please leverage encryption mechanism provided by the AWS for services meantioned in architecture.

Here are the links that provide more information about protecting data in the services used:
Amazon DynamoDB, Amazon Cloudfront, Amazon Lex, Amazon SageMaker, AWS Lambda, Amazon Kendra.
You need the following to be installed on your local machine to access the EKS cluster and
-
Premission to create IAM role , DynamoDB,deploy Kendra Lex CloudFront, host files in S3 On the AWS account that you will be deploying this kit you will need an IAM User with - Administrator and Programmatic access
-
Infrastructure to deploy the model:
-
Access to deploy your own API if you choose to go down that route
-
Ability to attach Layers to Lambda
-
Git security credentials.
- Choose Launch Stack and (if prompted) log into your AWS account:
These are the currently supported regions. Click a button to launch it in the desired region.
| Region | Launch | CloudFormation Template |
|---|---|---|
| Northern Virginia |  |
us-east-1 |
-
For Stack Name, enter a value unique to your account and region.
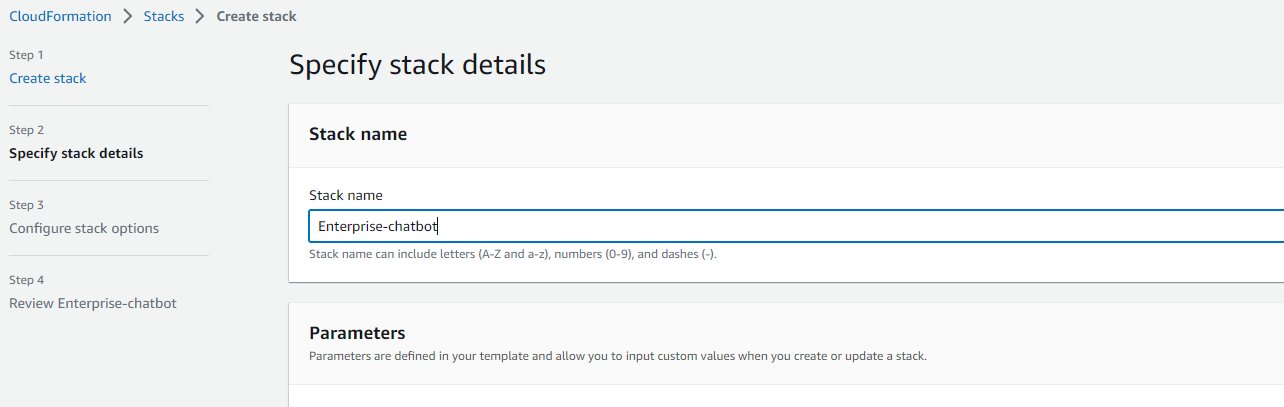
-
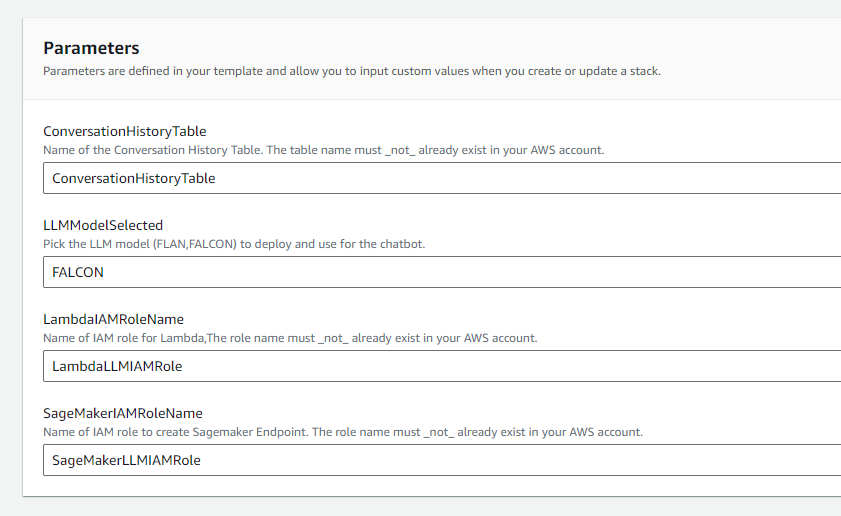
Pick and choose the parameters ,Leave the other parameters as their default values and select Next.
-
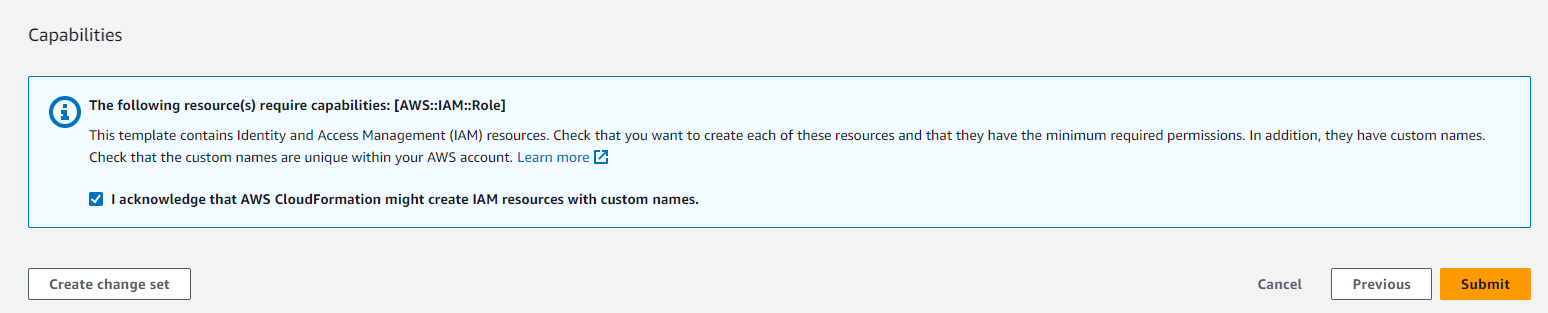
Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
-
Wait for ~20 minutes for AWS CloudFormation to create the necessary infrastructure stack and module containers.
-
After succesfull execution of previous step, deploy and configure Lex Web UI with 'LexV2BotId' & 'LexV2BotAliasId' information from final results of RAG Chatbot(deployed in Step 5) and enable Cognito authentication.
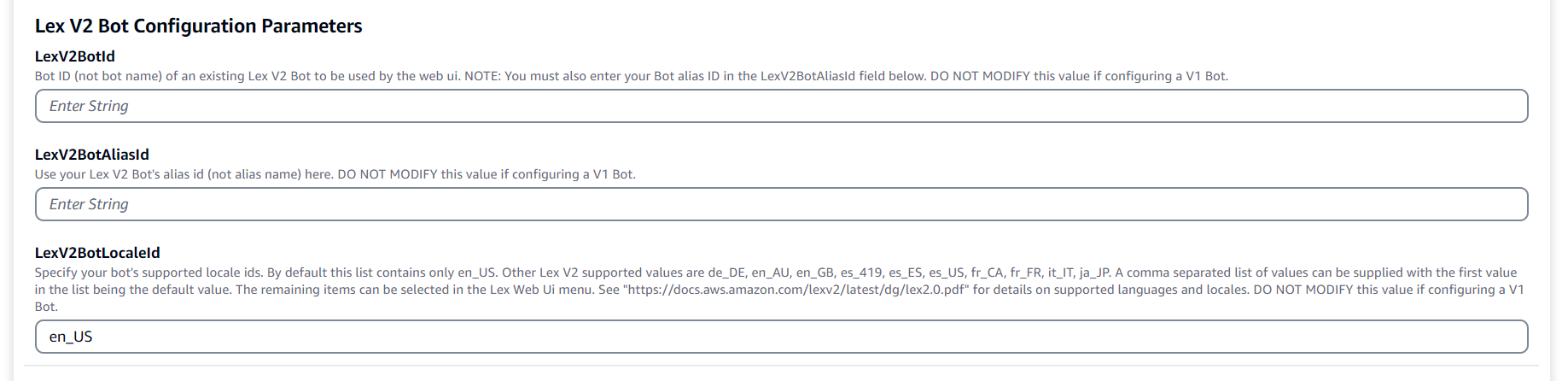




- Pick and choose the LLM


To remove the stack and stop further charges, first select the root stack from the CloudFormation console and then the Delete button. This will remove all resources EXCEPT for the S3 bucket containing job data .
To remove all remaining data, browse to the S3 console and delete the S3 bucket associated with the stack.
Lambda Orchestrator holds the intelligence to co-ordinate tasks across LLM and Kendra Retriever.
-
Simple LangChain Orchestrator : Here, Questions from users will be directly passed on to the Kendra Retriever, and results along with question from Kendra Retriever are fed into LLM . Later LLM's results are sent to End User.
-
Advanced LangChain Orchestrator with LangChain Agents : Kendra will be provided as tool for Langchian Agents (Kendra Tool). Please read through LangChain Agents documentation to learn more. Agents Implementation is made avaialbe for Anthropic Claud and LLAMA2 in this repository.
See CONTRIBUTING for more information.
This project is licensed under the Apache-2.0 License.