In this project, we aim to detect drivable areas using python, pytorch, opencv etc. technologies.


As a result of labeled the images, we obtain json files. These Json files contain the exterior point locations of the freespace class. In our annotation files, json files have the structure as in the following;

It was determined which pixel belongs to which object. Json files were converted to mask images in order to determine the locations with freespace in the image.
The fillPoly function of the cv2 library was used to draw a mask.
cv2.fillPoly(mask,np.array([obj['points']['exterior']]),color=1)
Mask example;

You can find the line by line explanations of the codes of this section from the json2mask.py file.
In this section, the masks were displayed on the images with 50% opacity to make sure the created masks were correct. The pixels specified as freespace in mask are color-coded (255,0,125) on the image.
img[mask==1 ,:] = (255, 0, 125)
Mask on image example;

You can access the complete code in the mask_on_image.py file.
Image and masks are used as input data in the model. We need to prepare input data to train the model.
Image Normalization is a process in which we change the range of pixel intensity values to make the image more familiar or normal to the senses.
img=cv2.imread(image)
norm_img = np.zeros((1920,1208))
final_img = cv2.normalize(img, norm_img, 0, 255, cv2.NORM_MINMAX)
We need to resize the images to be used in the model to be the same size.
output_shape = (224, 224)
img=cv2.resize(final_img,tuple(output_shape))
The model accepts the data transposed and in tensor type.
def torchlike_data(data):
n_channels = data.shape[2]
torchlike_data = np.empty((n_channels, data.shape[0], data.shape[1]))
for ch in range(n_channels):
torchlike_data[ch] = data[:,:,ch]
return torchlike_data
torchlike_image = torchlike_data(img)
batch_images.append(torchlike_image)
Image to torch tensor;
torch_image=torch.as_tensor(batch_images,dtype=torch.float32).float()
Generated tensor output;
torch.Size([4, 2, 224, 224])
The same procedures are applied to masks. In addition, one hot encoding was done. One Hot Encoding means binary representation of categorical variables. This process first requires the categorical values to be mapped to integer values. Then, each integer value is represented as a binary vector with all values zero except the integer index marked with 1.
def one_hot_encoder(res_mask,n_classes):
one_hot=np.zeros((res_mask.shape[0],res_mask.shape[1],n_classes),dtype=np.int)
for i,unique_value in enumerate(np.unique(res_mask)):
one_hot[:,:,i][res_mask==unique_value]=1
return one_hot
mask=one_hot_encoder(mask,n_classes)
One Hot Encoder output;

You can access the complete code in the preprocess.py file.

We used the U-Net model in this project. Because it is seen that U-Net model is used in many autonomous vehicle projects while searching for the best model for semantic segmentation. Semantic segmentation, also known as pixel-based classification, is an important task in which we classify each pixel of an image as belonging to a particular class. U-net is a encoder-decoder type network architecture for image segmentation. U-net has proven to be very powerful segmentation tool in scenarios with limited data (less than 50 training samples in some cases). The ability of U-net to work with very little data and no specific requirement on input image size make it a strong candidate for image segmentation tasks.
-
The encoder is the first half in the architecture diagram. Apply convolution blocks followed by a maxpool downsampling to encode the input image into feature representations at multiple different levels.
self.maxpool = nn.MaxPool2d(2)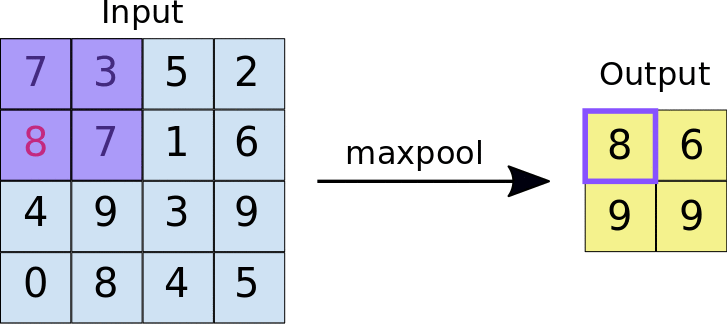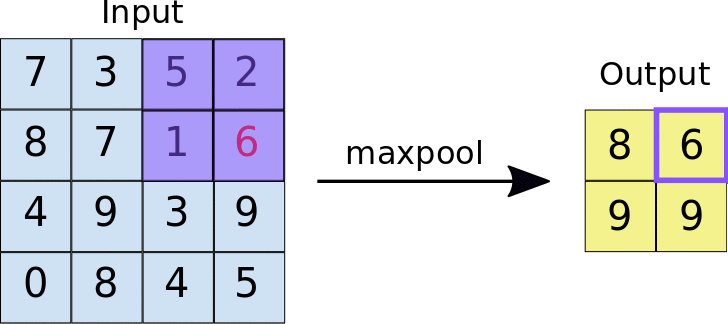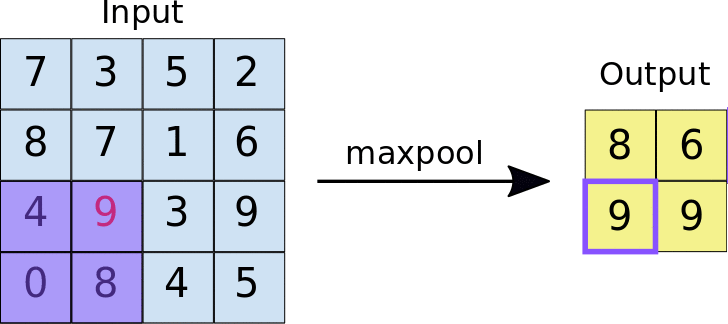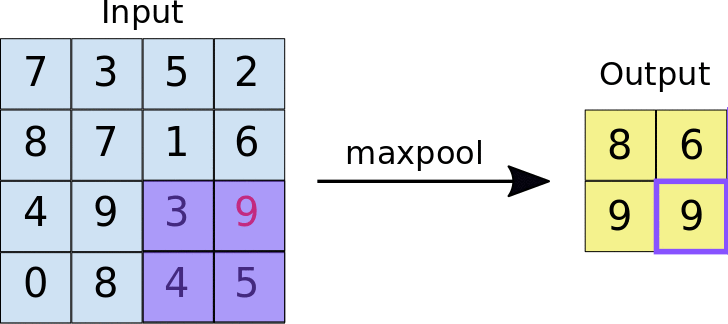
-
The decoder is the second half of the architecture. The goal is to semantically project the discriminative features (lower resolution) learnt by the encoder onto the pixel space (higher resolution) to get a dense classification. The decoder consists of upsampling and concatenation followed by regular convolution operations.
self.upsample = nn.Upsample(scale_factor=2,mode='bilinear', align_corners=True) -- x = torch.cat([x, conv2], dim=1)


Relu was used as the activation function.
-
The rectified linear activation function or ReLU for short is a piecewise linear function that will output the input directly if it is positive, otherwise, it will output zero. It has become the default activation function for many types of neural networks because a model that uses it is easier to train and often achieves better performance.
-
A neural network without the activation function will act like a linear regression with limited learning power. Relu is chosen if your network is very deep and your processing load is a major problem
nn.ReLU(inplace=True)

Batch normalization is another method used to make the convolutional neural network more organized. Besides a regulating effect, the batch norm also gives a resistance to the extinction gradient of the convolutional neural network during training. This can reduce training time and make the model perform better.
The softmax function is a function that turns a vector of K real values into a vector of K real values that sum to 1. The input values can be positive, negative, zero, or greater than one, but the softmax transforms them into values between 0 and 1, so that they can be interpreted as probabilities. If one of the inputs is small or negative, the softmax turns it into a small probability, and if an input is large, then it turns it into a large probability, but it will always remain between 0 and 1.
x = nn.Softmax(dim=1)(x)

You can find all the details about the model in the model1.py file.
In this section, we will train the model we created in the previous section.
First, we determined the parameters we will use while training the model.
valid_size = 0.3
test_size = 0.1
batch_size = 8
epochs = 35
cuda = True
input_shape = (224,224)
n_classes = 2
Then Train, validation and test data were determined.
# SHUFFLE INDICES
indices = np.random.permutation(len(image_path_list))
# DEFINE TEST AND VALID INDICES
test_ind = int(len(indices) * test_size)
valid_ind = int(test_ind + len(indices) * valid_size)
# SLICE TEST DATASET FROM THE WHOLE DATASET
test_input_path_list = image_path_list[:test_ind]
test_label_path_list = mask_path_list[:test_ind]
# SLICE VALID DATASET FROM THE WHOLE DATASET
valid_input_path_list = image_path_list[test_ind:valid_ind]
valid_label_path_list = mask_path_list[test_ind:valid_ind]
# SLICE TRAIN DATASET FROM THE WHOLE DATASET
train_input_path_list = image_path_list[valid_ind:]
train_label_path_list = mask_path_list[valid_ind:]
Then, data is taken from the train data set to batch_size. It is convert to Tensor. It is given to the model. The output from the model is compared with what should be. And a loss value is obtained. It updates the parameters by propagating back to the network according to this loss value.
# DEFINE LOSS FUNCTION AND OPTIMIZER
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
Creates a criterion that measures the Binary Cross Entropy between target and output. The loss function can be a function of the mean square of the losses accumulated over the entire training dataset. Hence the weights are updated once at the end of each cycle.
optimizer.zero_grad()
Resets the gradient so no buildup after each iteration.
We test our model with the validation data set at the end of each epoch. Thus, the loss value is calculated.
for (valid_input_path, valid_label_path) in zip(valid_input_path_list, valid_label_path_list):
batch_input = tensorize_image([valid_input_path], input_shape, cuda)
batch_label = tensorize_mask([valid_label_path], input_shape, n_classes, cuda)
outputs = model(batch_input)
loss = criterion(outputs, batch_label)
val_loss += loss.item()
val_losses.append(val_loss)
The above processes take place as many as the number of epochs. And the loss values are kept in a list. After the training is finished, a graph is drawn with these loss values. The resulting graphic;

We will try to improve these values in the following sections.
You can access the complete code in the train.py file.
To see the predictions of the trained model, predict operation is performed with the test data set. The images in the test data set are converted to tensor. It is given to the model. And the outputs are converted to masks. Then, these masks are printed on the images and the results are observed.
def predict(test_input_path_list):
for i in tqdm.tqdm(range(len(test_input_path_list))):
batch_test = test_input_path_list[i:i+1]
test_input = tensorize_image(batch_test, input_shape, cuda)
outs = model(test_input)
out=torch.argmax(outs,axis=1)
out_cpu = out.cpu()
outputs_list=out_cpu.detach().numpy()
mask=np.squeeze(outputs_list,axis=0)
img=cv2.imread(batch_test[0])
mg=cv2.resize(img,(224,224))
mask_ind = mask == 1
cpy_img = mg.copy()
mg[mask==1 ,:] = (255, 0, 125)
opac_image=(mg/2+cpy_img/2).astype(np.uint8)
predict_name=batch_test[0]
predict_path=predict_name.replace('image', 'predict')
cv2.imwrite(predict_path,opac_image.astype(np.uint8))
We do the opposite of what we do when converting mask to tensor, here to convert the tensor coming from the model to mask.
Predicted image;

The model gave good results in bright and normal way, but the accuracy was low in dark images such as tunnels;

Data Augmentation was implemented to prevent this situation.
The data in the Train data set was reproduced with augmentation at different angles and applying different contrast, brightness and hue values.
for image in tqdm.tqdm(train_input_path_list):
img=Image.open(image)
color_aug = T.ColorJitter(brightness=0.4, contrast=0.4, hue=0.06)
img_aug = color_aug(img)
new_path=image[:-4]+"-1"+".png"
new_path=new_path.replace('image', 'augmentation')
img_aug=np.array(img_aug)
cv2.imwrite(new_path,img_aug)
The replicated data was added to the train data set;
aug_size=int(len(aug_mask_path_list)/2)
train_input_path_list=aug_path_list[:aug_size]+train_input_path_list+aug_path_list[aug_size:]
train_label_path_list=aug_mask_path_list[:aug_size]+train_label_path_list+aug_mask_path_list[aug_size:]
Epoch number changed to 25. A few examples of new data added after these processes are applied;

The model was retrained with the duplicated train data set. New loss values and graph;


There is a good improvement in the results obtained after data augmentation;


