Implementing folds can be tricky, brain-bending conquests in Haskell. This becomes all the more challenging in domains where associativity and strictness properties are less straightforward, such as when writing Template Haskell. While folds appear deceptively simple, they can be confusing to work with in practice. Without a structured way to fact-check your intuition, it can be easy to overlook subtle intricacies, naively choose a left fold when your problem required a right fold, etc. Re-thinking original assumptions costs precious time and can leave you feeling like a dysfunctional baby. Luckily, there is a more methodical way to navigate these handy and useful higher-order functions.
Instead of doing frustrating mental gymnastics to determine which fold is most appropriate for your problem, you can lean on GHCi. My teammate Patrick introduced me to a systematic framework which involves using some basic heuristics in conjunction with REPL trial-and-error to alleviate the cognitive load. It was a game-changer for me, so I thought I'd pass along this bit of wisdom to potentially guide other dysfunctional Haskell babies trying to navigate folds.
For the sake of brevity, I'll keep an introduction to folds short and shallow. For more background, read this wiki. This post will instead focus on demonstrating how to figure out which fold is most suitable for a given function you wish to refactor.
"Folds" refer to a group of higher-order functions that operate over a data structure that can be folded (think lists, trees, etc.), and collapse them into another data structure or final result as the return value. These functions are provided by the Foldable type class.
Functions used to express recursion over lists and list-like data structures often share common behavior. When expressed via pattern matching, this common behavior tends to follow a similar theme: we first define the edge case for an empty list, think through what happens for one element, and then the rest of the elements in the list using the (x:xs) pattern. The recursive step is usually what we apply to the xs, ie., the remaining list elements. The behavior shared by these frequently occurring recursive patterns was extracted out into a set of functions that encapsulate this common technique, and these functions are known as folds!
The Foldable class defines many functions. I will limit my discussion to the four types of different fold functions with similar, but subtly varying orientation and behavior:
| Higher-order function | What it does |
|---|---|
foldl: |
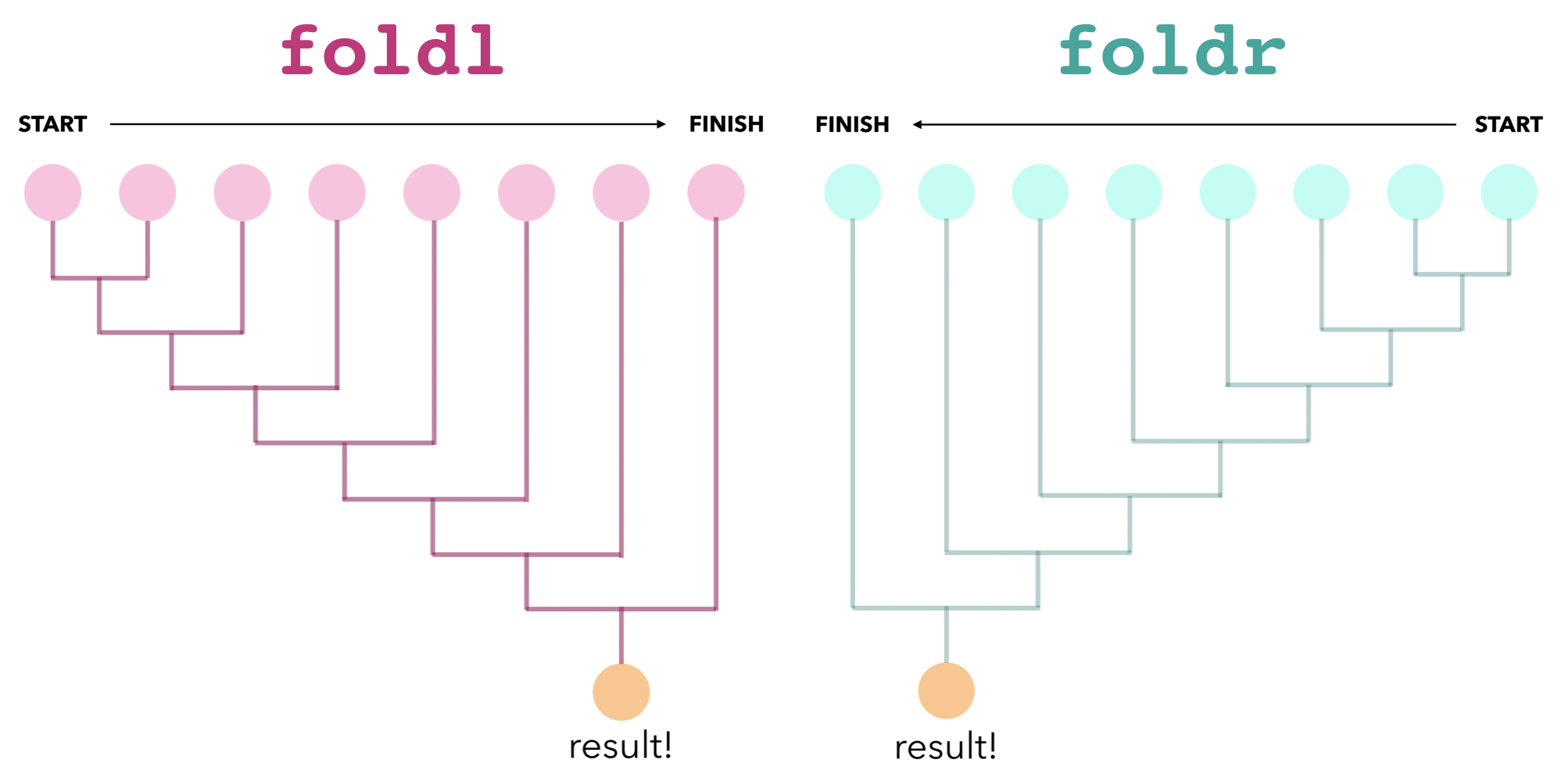
Starts from the leftmost element, takes a combining function, an initial value, and moves toward the right. This is bad news bears for infinite lists, since you'll have a non-terminating situation on your hands. |
foldr: |
Starts from the rightmost element, takes a combining function, an initial value, and moves left. This terminates when operating on infinite lists. |
foldl1: |
Like foldl, but you don't need to provide an explicit starting value. They assume the first element of the list to be the starting value and then start the fold with the element next to it. This requires non-empty inputs and will otherwise throw an exception. |
foldr1: |
Like foldl1, but the default starting value will be the last element, and the fold will move leftward. This requires non-empty inputs and will otherwise throw an exception. |
foldl': |
Like foldl, but strict in the accumulator. |
Visualization of left vs. right folds:
Real life photograph of the runtime exception that occurs when you use foldl on infinite lists:
Before I show you how to choose the correct fold using GHCi, it's important to understand how folds are used to abstract away recursion.
Rewriting manual recursion in terms of folds is a frequently occurring refactoring opportunity in Haskell code bases (though whether or not it's the right decision is a discussion that appears later in this tutorial). To learn how this works, let's start with a super simple function you were introduced to in grade school: sum!
We would like to add up all of the values in this list: [1,2,3,4,5].
If we write a regular-schmegular manually recursive function, our definition will look something like this:
sumManual :: (Num a) => [a] -> a
sumManual [] = 0
sumManual (x:xs) = x + sumManual xsThis behaves as expected in ghci:
>>> sumManual [1,2,3,4,5]
15
We have the base case of the empty list, [], and the recursive case. Turns out, the definition of foldl contains all of that sweet recursive machinery needed to power our manual sum function:
foldl :: (a -> b -> a) -> a -> [b] -> a
foldl f z [] = z
foldl f z (x:xs) = foldl f (f z x) xsThis means we can take foldl and just plug it in to our sum implementation.
We know from the above source that foldl takes some binary function f with the signature (b -> a -> b) (in our case + since we're summing), a starting value b (in our case, 0), and some structure t a (in our case a list [a]).
This is how we can rewrite sum using foldl:
sumFold :: (Num a) => [a] -> a
sumFold = foldl (+) 0Cool! I can read this function without being exposed to its recursive guts. Let's test its behavior:
>>> sumFold [1,2,3,4,5]
15
- Maintainability: Abstracting away the recursion part allows us to decouple the logic of what we are doing from how we do it. Instead of appearing explicitly in our code, the recursion part is neatly packaged up and handled by a higher-order function. This is more idiomatic. The intent is expressed more clearly and focus is on what the function achieves, without introducing the potential of getting bogged down in the how the recursion works, and introducing possible errors.
- Performance: GHC is relatively reluctant to inline manually-written recursive code, but it is very happy to inline
foldl'andfoldr. Additionally, the use of a fold operation can make performance issue more clear, since we can examine the performance of the function independently of how it implements its recursion. - Folds are generic: Folds are generic and can work over any container type (such a list, binary tree, etc.) This gives us a more general expression we can specialize for our particular container.
- Confusing to read: Despite their benefits, folds are not straightforward. They can introduce a lot of cognitive overhead. While they provide a neat logical separation and a clever way to express code more concisely, they can also reduce the clarity given by explicit recursion. The recursive part is now opaque and handled by this abstraction. Separation of concerns is generally a useful design strategy, and folds are a prime example of that—but separation of concerns can also be problematic. This is predicated on whether or not the introduction of folds reduce or increase the complexity of your code (referencing the fundamental theorem: “Every problem can be solved by adding another layer of abstraction, unless the problem is too many layers of abstraction”).
- Confusing to write: Folds are also difficult to write. Often times, it isn't immediately clear whether something will be a left or right fold, and whether you need to provide an initial value.
- Performance: Fold is inherently
O(n)*complexity_of_fold_function. You ideally want steps of a fold to beO(1),O(log n)or generally sublinear, so there are cases where folds could result in speed ups, and other cases where they could hurt your performance (though you can almost always safely turn manual recursion into a fold operation without hurting performance).
The recipe for using folds in your function more or less to:
- Know the type signature of the function you want to write. This will give you an understanding of the data structure you wish to process, and the output you wish to produce.
- Optional step: think through how to determine something as an explicit function (this step may be omitted, but I find it helpful to do the explicit thing first, before using a higher-order function to handle it).
- Use these heuristics to hypothesize how your input will be processed. Protip: you almost never want to use
foldl. - Use ghci: test your assumptions by using your knowledge of types, the expected result and feed some dummy inputs to the REPL. This will quickly confirm or deny whether your hypothesis was correct.
The example I will use to illustrate this practice comes directly from code I refactored in a library I'm building to deserialize JSON ASTs and auto-generate Haskell code using Template Haskell. Rather than taking a boring journey through ghci errors, I'm going to tell the story of Foldilocks and the three folds.

Foldilocks is uncovering the differences between three folds: foldr, foldl and foldl'. Let's walk through how she figures out how to find the fold that's juuuuust right.
Consider this function that takes a string input in snake_case, remove underscores from input strings, and outputs dromedaryCase:
-- Helper function to remove underscores from output of data type names (hello_world -> helloWorld)
removeUnderscore :: String -> String
removeUnderscore ('_':cs) = initUpper (removeUnderscore cs)
removeUnderscore (c:cs) = c : removeUnderscore cs
removeUnderscore "" = ""It is expressed here with an explicit recursive call. Off hand, we know that the data structure we wish to process is a list (since a String is a list of Char). Because we process the string from left to right, my intuition leads me to assume we want to use foldl (start on the left, proceed right). In fact, I think what we want is actually foldl' since it uses strict application and gives us better performance. Our list will certainly be finite, so this seems like a safe guess. Let's explore this intuition by using ghci to check whether or not it holds.
The strategy can be broken down into this general recipe:
- Start at the type level, and find what signature you want with type applications.
- Switch to the value level, and find what values you want using type holes.
According to its type signature, foldl takes a function that takes two different types, b -> a -> b, a value b, and folds over container t consisting of a:
>>> :t foldl'
foldl' :: Foldable t => (b -> a -> b) -> b -> t a -> b
This gives us a polymorphic type signature. If we specialize t for lists, we get:
foldl :: (b -> a -> b) -> b -> [a] -> b
If we further specialize this according to the type signature of removeUnderscore, we get:
foldl :: (String -> Char -> String) -> String -> [Char] -> String
Switching back to our REPL, we can use type applications to demonstrate how this polymorphic function will be used for lists:
>>> :set -XTypeApplications
>>> :t foldl' @[]
foldl' @[] :: (b -> a -> b) -> b -> [a] -> b
This first [] application is to handle the Foldable constraint. It abides by the rule that this needs to be a structure we can fold over. We can add in our second parameter, a String:
>>> :t foldl' @[] @String
foldl' @[] @String
:: (String -> a -> String) -> String -> [a] -> String
Finally, we can introduce the type of our last remaining parameter, Char:
>>> :t foldl' @[] @String @Char
foldl' @[] @String @Char
:: (String -> Char -> String) -> String -> [Char] -> String
This function requires that we build the output string by processing an input string left to right, adding a single element Char to the beginning of the list if it is not an underscore, and discarding it if it is one. The cons or : operator allows us to do that. (:) is a binary operator.
The arguments to foldl are a binary operator, some current value, and an initial value. Let's partially apply the function (:) to foldl:
>>> :t foldl' (:)
<interactive>:1:8: error:
• Occurs check: cannot construct the infinite type: a ~ [a]
Expected type: [a] -> [a] -> [a]
Actual type: a -> [a] -> [a]
• In the first argument of ‘foldl'’, namely ‘(:)’
In the expression: foldl' (:)
*Main Data.List Data.Foldable>
We get an error because passing in : doesn't type check. Let's look at the type of (:):
>>> :t (:)
(:) :: a -> [a] -> [a]
If we use type applications once again to specialize for lists:
:t (:) @Char
(:) @Char :: Char -> [Char] -> [Char]
Passing : to foldl doesn't type check because (:) :: Char -> String -> String, which doesn’t match (b -> a -> b). There are two functions of type String -> Char -> String:
- one is
\a b -> b : a(which is synonymous withflip (:)) - The other is
\str char -> str ++ [char]
The second option is O(n), and since we run it n times it would make the function O(n^2), therefore the first one is the one we want, so let's use flip (:) instead:
>>> :t foldl' (flip (:))
foldl' (flip (:)) :: Foldable t => [a] -> t a -> [a]
Ok, so far so good! Let's test with our edge case, the empty string:
>>> :t foldl' (flip (:)) ""
foldl' (flip (:)) "" :: Foldable t => t Char -> [Char]
Now, just as we used type applications to test with earlier, let's do so with the flip (:)
>>> :t foldl' @[] (flip (:)) ""
foldl' @[] (flip (:)) "" :: [Char] -> [Char]
This gives us something partially applied, because we have only provided the starting value, not the entire structure we wish to process. In order to fully apply it and see a result, let's give it a simple list:
>>> foldl' @[] (flip (:)) "" "abcd"
"dcba"
Oops! That reversed our list, and that's not what we want! We're doing things in the wrong order! Foldilocks' nemesis, Foldemort, appears and tells you this is the incorrect fold!

Turns out, it is not foldl we want, but foldr. Let's run through the same dance with foldr:
>>> :t foldr
foldr :: Foldable t => (a -> b -> b) -> b -> t a -> b
>>> :t foldr @[]
foldr @[] :: (a -> b -> b) -> b -> [a] -> b
>>> :t foldr @[] @Char
foldr @[] @Char :: (Char -> b -> b) -> b -> [Char] -> b
>>> :t foldr @[] @Char @String
foldr @[] @Char @String
:: (Char -> String -> String) -> String -> [Char] -> String
This seems to align with the type signature we want. Since the type signature of foldr is foldr :: Foldable t => (a -> b -> b) -> b -> t a -> b, we can provide it with the (:) operator without having to flip the arguments. (:) also happens to be O(1).
>>> :t foldr (:) ""
foldr (:) "" :: Foldable t => t Char -> [Char]
>>> foldr (:) "" "abcd"
"abcd"
Yay! This works! Now let's test it with the actual logic, which is to ensure we remove an underscore, and capitalize the letter succeeding the removed underscore. To do so, (:) won't be enough on its own. We need to create a function that has all of the logic beyond simply prepending a character.
Let's create a function called foo in terminal that does this and test it out:
>>> let foo '_' cs = initUpper cs; foo c cs = c : cs
>>> foldr foo "" "ab_cd"
"abCd"
Success!
foldr takes a binary function, the starting value, and the data structure. We can define this function in a where clause:
-- Helper function to remove underscores from output of data type names
removeUnderscore :: String -> String
removeUnderscore xs = foldr appender "" xs
where appender :: Char -> String -> String
appender '_' cs = initUpper cs
appender c cs = c : csNotice that this function, which we've named appender only cares about one value at a time. The foldr will handle the task of applying this function recursively to all elements of the list.
If we eta-reduce it, we get:
-- Helper function to remove underscores from output of data type names
removeUnderscore :: String -> String
removeUnderscore = foldr appender ""
where appender :: Char -> String -> String
appender '_' cs = initUpper cs
appender c cs = c : csFast feedback loops from the REPL help check your intuition. This is especially valuable when working with folds. If you're a beginner to Haskell, my hope is that this helped illuminate the mystical and sometimes elusive path toward becoming a fold Sufi.
Implement the following recursive functions with folds. Solutions are provided here. I've also created a repl.it project for in-browser experiments.
max :: (Ord a) => [a] -> areverse' :: [a] -> [a]elem' :: (Eq a) => a -> [a] -> Boolproduct' :: (Num a) => [a] -> afilter' :: (a -> Bool) -> [a] -> [a]head' :: [a] -> alast' :: [a] -> amap :: (a -> b) -> [a] -> [b]usingfoldrmap :: (a -> b) -> [a] -> [b]usingfoldlFoldableinstance for a binary tree usingfoldrFoldableinstance for a binary tree usingfoldMap