Wiktionary is my go-to place for learning new words. The second is UrbanDitionary. Doing this ten times a day I decided to see if I could make my experience faster. As a first step, I'll try to extract some meaningful data from Wiktionary.
The goal is to be able to extract minimal content that would explain the meaning of words to me, and to skip all the material that I don't use. Sections like etymology, examples, pronunciation, quotation, and definition go in, sections like descendants, see also, references, derived terms, et al. go out.
The problems I can see at first glance:
- Sections structure does not always match the recommendation.
- Section names have typos (that I'm trying to fix in this post).
So I need to manually define section names that I want to keep and ignore all others. The most challenging parts of it are dealing with the inconsistent structure of sections, most notable on pages that explain homography, and handling different parts of speech sections.
In Wiktionary, homographs are resolved by specifying several etymologies on one page, which follows the Oxford Dictionary recommendation. Such pages would be structured with all related sections nested under that Etymology section. In the result, I want to have different objects for different Wiktionary Etymology sections, and all POSes that relate to the same etymology definition within that Etymology object.
Here is the structure difference:

In another case, if a word in Wiktionary has only one meaning (hence only one etymology definition), the Pronunciation and POS sections go on the same level as the Etymology.
To do the conversion I need, I have to understand how consistently the content is organized in Wiktionary in reality. Based on the section name analysis that I did, I have generated parents and children stats for every section. The sections statistics data is available here.
We can see that Pronunciation is a more rare subsection of Etymology than any POS. In the same time, Pronunciation section sometimes contains POS sections, hence is used as the term root, instead of Etymology. These observations mean that homograph pages in Wiktionary do not always follow the recommendation. To be clear on numbers, only about 2% of Wiktionary pages are homographs. You might want to consider ignoring them entirely. But I don't want to miss them, especially the homographs.
Below are some more of subsection stats on the most mentioned Wiktionary sections:
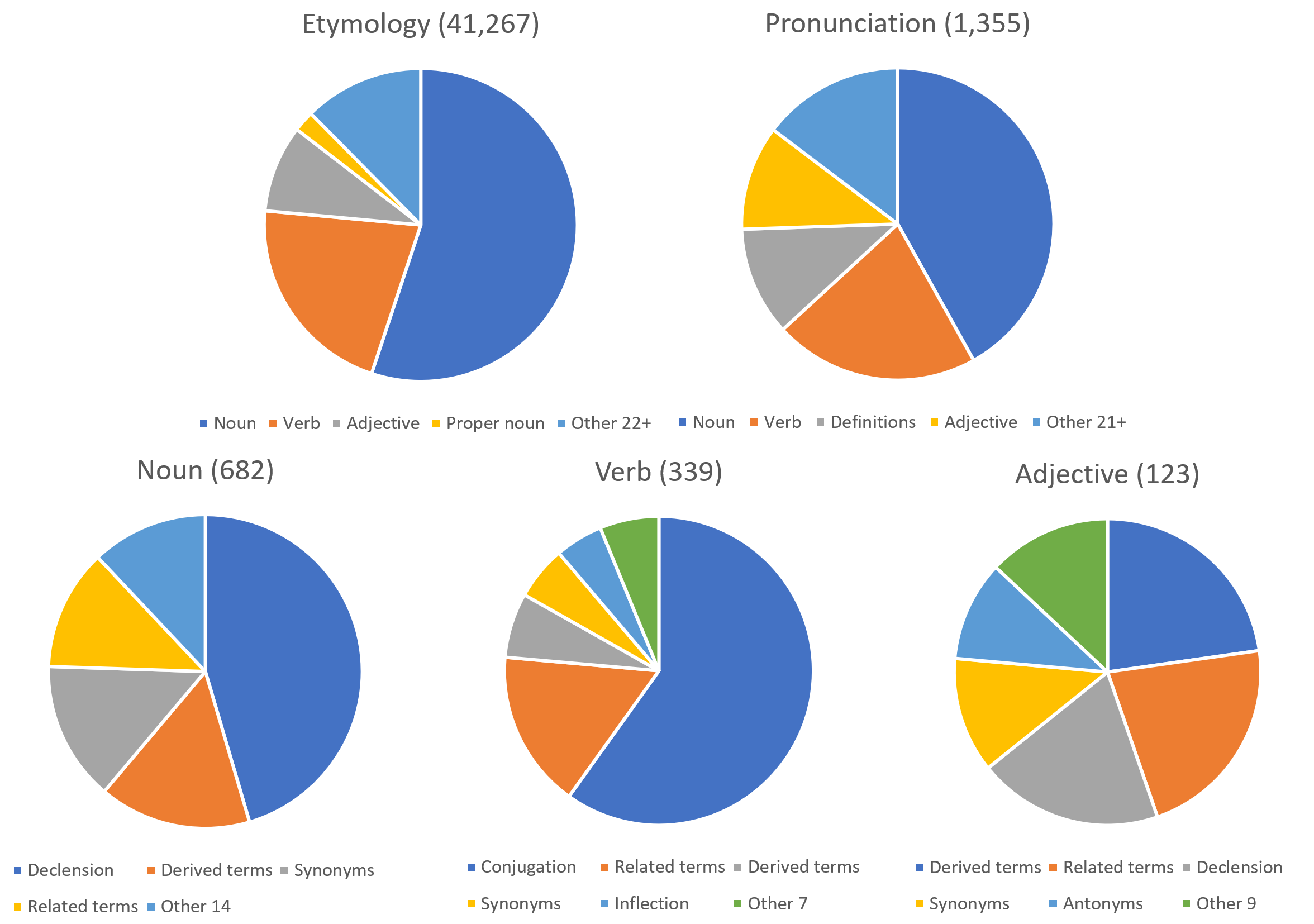
Numbers in the braces are the numbers of these sections that have any child sections. 98%+ of the shown sections do not have any subsections at all.
So we can see that there is no specific structure that we can rely on. Instead, there is a graph that can look like this:

I have to start with saying that I don't need all data from Wiktionary. As I mentioned before, I only need data that would help the learner to learn the work, or to be more precise, to learn using the word.
I ended up with a shrunk version of the knowledge graph:

The challenge is that on Wiktionary pages the root item, defining a separate term, can be a language, an etymology, or a pronunciation. I want to ignore all other types of structure as it is a minority or not very interesting terms. I'll show some statistics below.
The features of our graph are: A. It is actually a tree, B. It is directed, i.e., nodes are enriched by the content from their child nodes, C. Siblings relate to each other unless they are twins, D. I'll define twins as similar sections, e.g., all language names are twins, sections called "Contoso 1", "Contoso 2", etc. are also twins. In short, twins do not relate to each other an can define separate terms.
With these features in mind I follow the next steps to extract a set of terms from a page:
- Clean up the graph to include only the sections I know. All other sections are simply ignored.
- Go through the graph with the following recursive routine:
void ProcessGraph(GraphItem item)
{
if (item.CanDefineTerm) // a fixed subset of sections
item.DefineTerm(); // create an instance of a term
foreach (var child in item.Children)
{
if (child.IsLanguage)
child.SetLanguage(); // update this and dependent nodes
else if (item.AllowsMember(child)) // subset of sections
item.UpdateMember(child);
else child.UpdateTerm(); // update an existing term
ProcessGraph(child); // repeat for the child
}
}- The GraphItem.DefineTerm takes advantage of all features A-D in order to link proper terms to proper graph nodes:
void DefineTerm()
{
// If this node can define a term, we need to:
// a. trash the already defined term
_term.Status = Term.TermStatus.Void;
// b. but inherit all its properties
_term = _term.Clone();
_term.Language = Language;
// c. and store the new term
_createdTerms.Add(_term);
if (_parent != null && !IsLanguage) // languages are all twins
{
foreach (var sibling in _parent._children)
{
if (sibling != this &&
sibling.ItemTitle != this.ItemTitle) // not twins
{
sibling._term = _term; // inherit this term
ForEachChild(sibling,
(p, nephew) => nephew._term = _term);
}
}
}
// children inherit this term
ForEachChild(this, (p, child) => child._term = _term);
// redefine the term
_term.Status = Term.TermStatus.Defined;
// save content of this node to the defined term
if (!IsLanguage)
AddMember(_term, this);
}- Finally, when the page is processed, we take only the terms that are defined:
_createdTerms.Where(i => i.Status == TermStatus.Defined)
Some statistics as promised:
- Pages processed: 5,887,239
- Words defined: 5,464,020 (word is a set of terms on one page, so we could successfuly extract data from 92.8% of wiktionary pages)
- Total terms: 5,839,711
The statistics looks really awesome to me. As the next step I will be working on coverting Wikitext to a form suitable to myself. Yes, I was wrong, Wikimedia websites use Wikitext and not Creole. That is going to be a challenge, not limited to processing the various templates that it has.
I have to start with saying that I don't need all data from Wiktionary. As I mentioned before, I only need data that would help the learner to learn the work, or to be more precise, to learn using the word.
I ended up with a shrunk version of the knowledge graph:
The challenge is that on Wiktionary pages the root item, defining a separate term, can be a language, an etymology, or a pronunciation. I want to ignore all other types of structure as it is a minority or not very interesting terms. I'll show some statistics below.
The features of our graph are: A. It is actually a tree, B. It is directed, i.e., nodes are enriched by the content from their child nodes, C. Siblings relate to each other unless they are twins, D. I'll define twins as similar sections, e.g., all language names are twins, sections called "Contoso 1", "Contoso 2", etc. are also twins. In short, twins do not relate to each other an can define separate terms.
With these features in mind I follow the next steps to extract a set of terms from a page:
- Clean up the graph to include only the sections I know. All other sections are simply ignored.
- Go through the graph with the following recursive routine:
void ProcessGraph(GraphItem item)
{
if (item.CanDefineTerm) // a fixed subset of sections
item.DefineTerm(); // create an instance of a term
foreach (var child in item.Children)
{
if (child.IsLanguage)
child.SetLanguage(); // update this and dependent nodes
else if (item.AllowsMember(child)) // subset of sections
item.UpdateMember(child);
else child.UpdateTerm(); // update an existing term
ProcessGraph(child); // repeat for the child
}
}- The GraphItem.DefineTerm takes advantage of all features A-D in order to link proper terms to proper graph nodes:
void DefineTerm()
{
// If this node can define a term, we need to:
// a. trash the already defined term
_term.Status = Term.TermStatus.Void;
// b. but inherit all its properties
_term = _term.Clone();
_term.Language = Language;
// c. and store the new term
_createdTerms.Add(_term);
if (_parent != null && !IsLanguage) // languages are all twins
{
foreach (var sibling in _parent._children)
{
if (sibling != this &&
sibling.ItemTitle != this.ItemTitle) // not twins
{
sibling._term = _term; // inherit this term
ForEachChild(sibling,
(p, nephew) => nephew._term = _term);
}
}
}
// children inherit this term
ForEachChild(this, (p, child) => child._term = _term);
// redefine the term
_term.Status = Term.TermStatus.Defined;
// save content of this node to the defined term
if (!IsLanguage)
AddMember(_term, this);
}- Finally, when the page is processed, we take only the terms that are defined:
_createdTerms.Where(i => i.Status == TermStatus.Defined)
Some statistics as promised:
- Pages processed: 5,887,239
- Words defined: 5,464,020 (word is a set of terms on one page, so we could successfuly extract data from 92.8% of wiktionary pages)
- Total terms: 5,839,711
The statistics looks really awesome to me. As the next step I will be working on coverting Wikitext to a form suitable to myself. Yes, I was wrong, Wikimedia websites use Wikitext and not Creole. That is going to be a challenge, not limited to processing the various templates that it has.