Model classification for article category with 4 categories funny, sport, entertainment and other (train data: 250K titles and test data: 60K).
Dataset include 4 categorical text, which the precentage of data is represent in the diagram below.
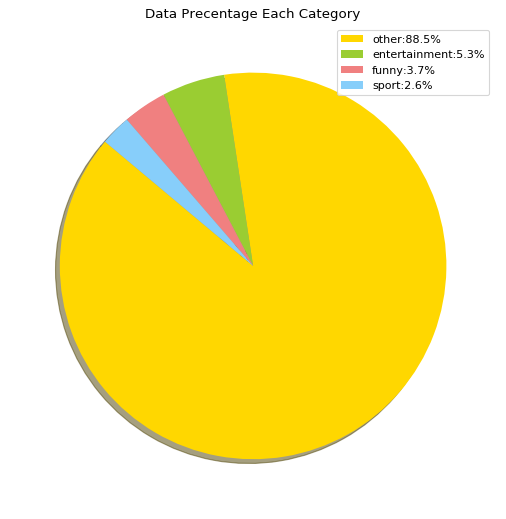
For train dataset can downloaded here : https://drive.google.com/file/d/1ai-Vt5-e_2tNAHuu93cnsgWJx4W1auu9/view?usp=sharing
In this discussion that will be split as 3 process, pre-processing data, prediction method, and implementation model.
- Pre-processing data.
- Import dataset .json and convert to data frame and drop column ‘id’ because it’s not important for making prediction model
- Then clean the data from non-letters characters, setting lower case in each sentence, and removing stopwords and save into new clean data in datafame
- Replace each categorical to be numerical using dictonary : {'entertainment': 2, 'funny': 3, 'other': 1, 'sport': 4}
- Create wordclouds from each categorical data to know what the frequent words appear in each category
- Prediction method using LSTM model
- Vectorizer article title text by turning each text title into sequenve of of integer
- Set limit for number vocabulary that will use in model (I choose 5000 words)
- Set maximum number of each word titile text (I choose 100)
- Set word embedding maximum dimension (I choose 50)
- Find unique token using Tokenizer from dataset (merge from data_train and data_test)
- Convert text into sequence that contain index of word contains in each text and make the data as tensor with size respectively for data_train and data_test : (250116, 100) (62534, 100)
- Convert categorical labels to vector that is : {'entertainment': [0,1,0,0], 'funny': [0,0,1,0], 'other': [1,0,0,0], 'sport': [0,0,0,1]}
- Make deep learning architecture :
- The first layer is embedded layer that has output 100 represent vector each text and 50 represent embedding dimension
- SpatialDropout1D performs variational dropout in NLP models
- Next layer is LSTM with 100 memory units
- The output creates 4 output values for each class (probability)
- The loss function is categorical_crossentropy because it is classification problem with multi-class label
This is model.summary() from the deep learning architecture :
- In the model has added callbacks using EarlyStopping for stopping epoh when min_delta of loss is 0.0001
- Result of model training

- This is plot of Loss and Accuracy from train data and validate data where validate data set 20% from train data.


- Model testing result :

- Predict New Text Imput
- First teks input will cleaning using the function that has been created for cleaning data
- Convert text to sequence using word_index from the model
- Pad sequence so it has same length as the model input before
- Predict the padded array
- The output is probability of each class so find the greatest number that it’s mean probability the text is that category is biggest then others.






