Busy Teaching Mechanism: Self-ensembling with Shift Augmentation and Progressive Distillation for 3D Detection This repository contains the official implementation for our manuscript "Busy Teaching Mechanism: Self-ensembling with Shift Augmentation and Progressive Distillation for 3D Detection".
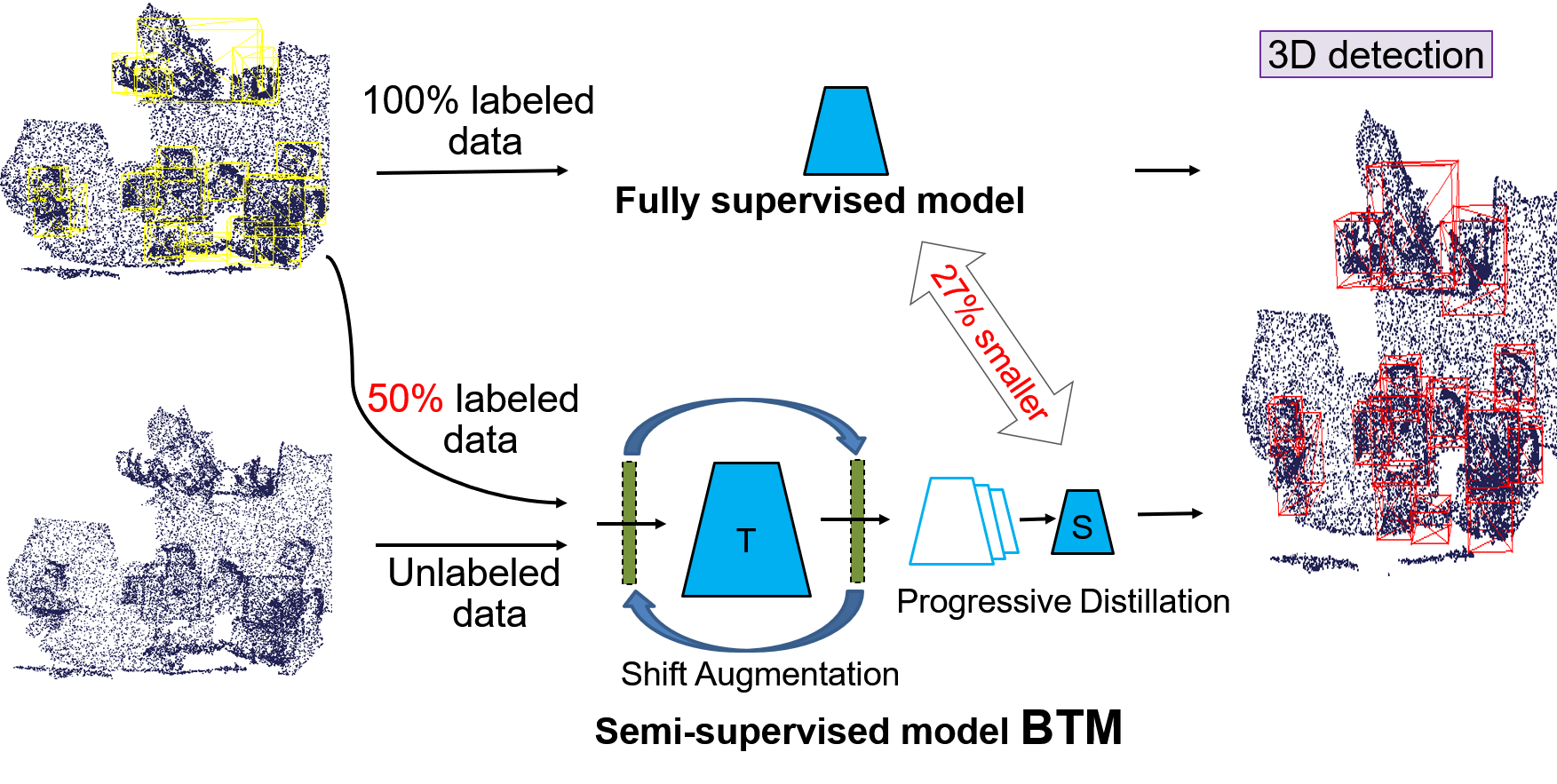
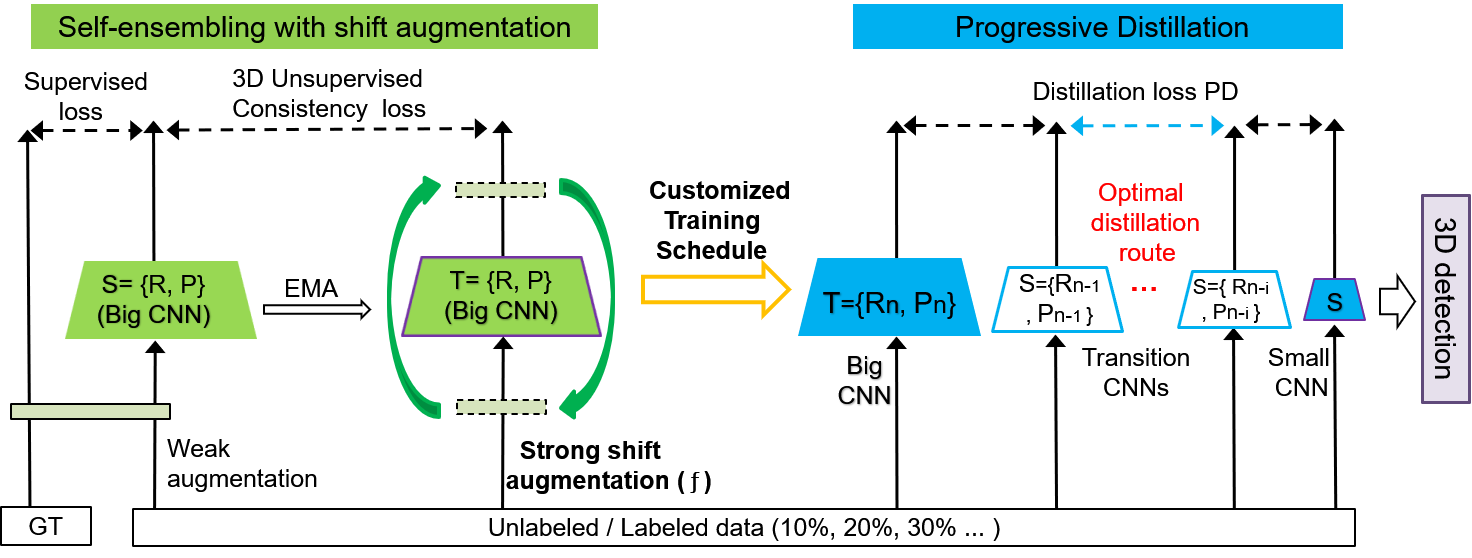
Currently, point cloud-based 3D detection methods performance tediously relies on high-quality 3D annotations, which are often expensive and time-consuming to obtain. Semi-supervised learning is an excellent option to moderate the data annotation matter. Motivated by the development of the self-ensembling and knowledge distillation technique in the semi-supervised image classification task, we propose Busy Teaching Mechanism (BTM), a semi-supervised 3D target detection framework. BTM needs to be busy accepting the data augmented by the shift augmentation (SA), training the big teacher network by a customized training schedule, and progressively distilling to a small student network for reducing the deployment cost. Specifically, we innovatively proposed the SA that periodically shifts the data augmentation operations at both ends of the big network to improve the network's generalization on new unseen and unlabeled data. The big network is required for benefiting the large scale augmented data as much as possible, and trained by customized training schedule to solve the over-flat after data augmentation and the overfitting for the big model. Then the oversized gap between the big teacher and small student network is bridged by the Progressive Distillation (PD), to obtain an efficient 3D detection model with low deployment cost.
Extensive experiments conducted on SUN RGB-D and ScanNetV2 datasets prove the effectiveness of BTM in both inductive and transductive semi-supervised 3D target detection. Finally, using only 50% labeled data and a 27% smaller model size, BTM achieves better performance than the state-of-the-art fully supervised approach.