CircuitStream 🌐⚡
A universal Language Model relay system, making it seamless to integrate with various models across different platforms! Designed to help developers achieve interoperability without hassles.
This type of relay is also useful if you're an organization with a single account distributed accross multiple teams or developers as rate limit can be configured at a per model level.
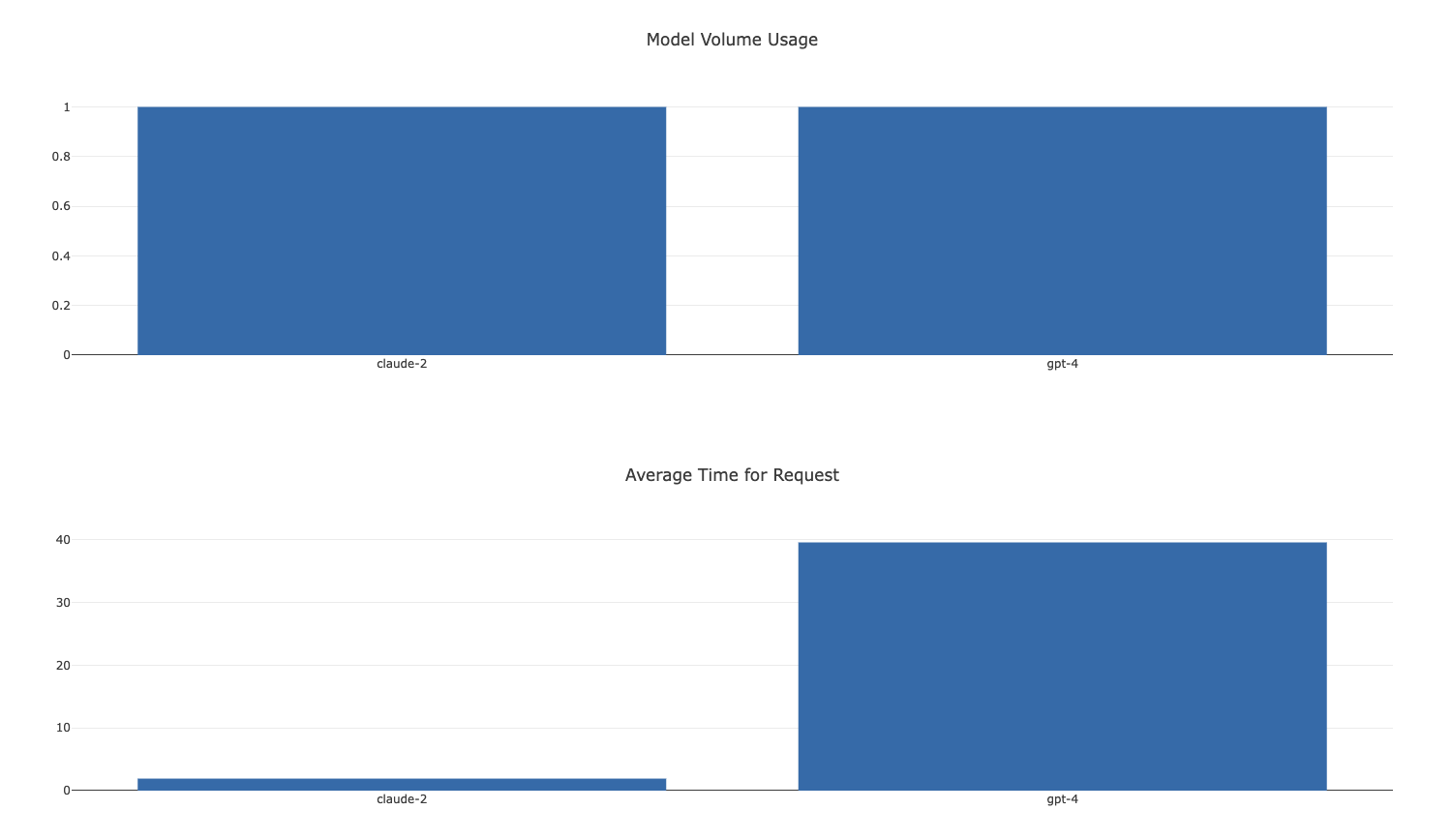
If you're running tests against multiple LLMs this is also a great way to generate centralized analytics.
Features 🌟
- Unified Interface: One API to rule them all! Easily call different models through a standardized interface.
- Configurable: Add or modify endpoints without touching the core logic.
- Rate Limiting: Safeguard against excessive requests with built-in rate limiting.

- Analytics: Dive deep into request analytics with logging and insights.
- Cross-Origin Resource Sharing (CORS): Built-in CORS support, making it browser friendly.
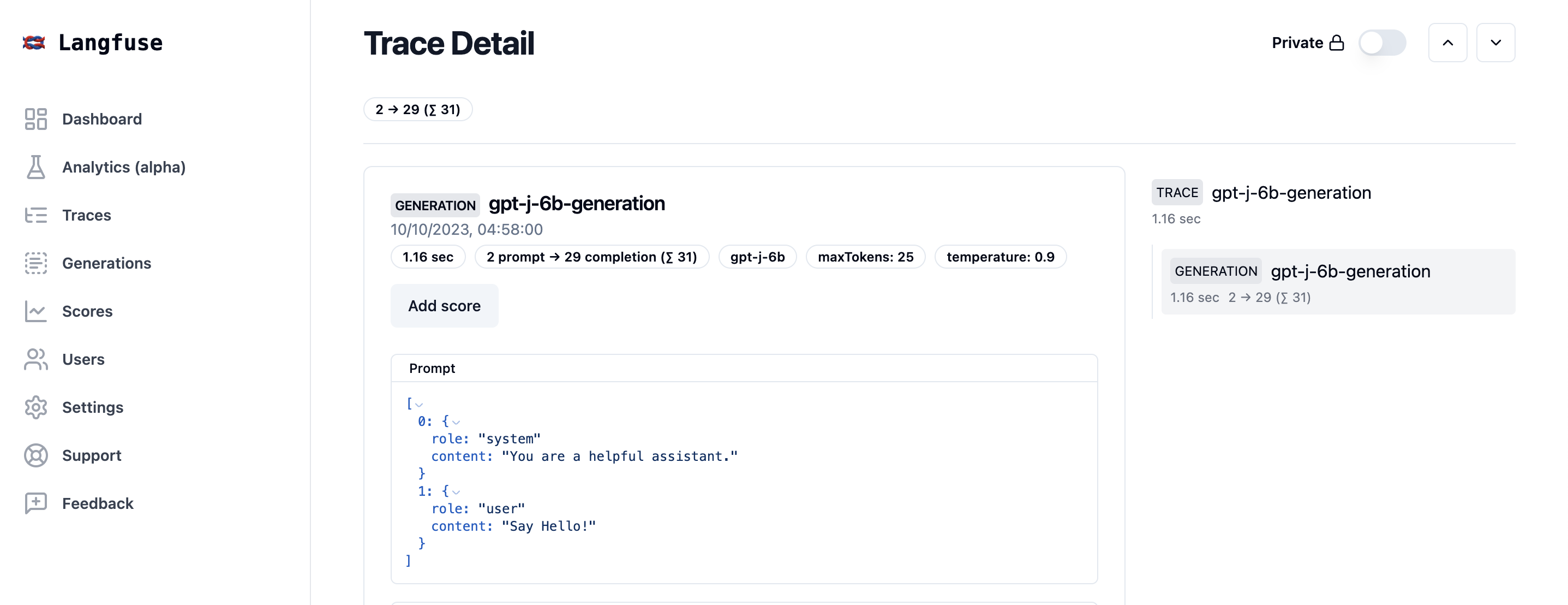
- Automated instrumentation of all models: Automated observability and analytics for all models with Langfuse.



Getting Started 🚀
Prerequisites
- Python 3.8+
- Virtual Environment (recommended)
Setup & Installation
- Clone the repository:
git clone https://github.com/balgan/CircuitStream.git
cd CircuitStream- Create and activate a virtual environment (Optional but recommended):
python -m venv venv
source venv/bin/activate # On Windows use `venv\Scripts\activate`- Install the dependencies:
pip install -r requirements.txt-
Modify the
config.jsonfile to match your desired configuration for various language models and platforms. -
Create create a
secrets.jsonwith your langfuse configuration with the following format:
{
"ENV_PUBLIC_KEY": "pk-XXX",
"ENV_SECRET_KEY": "sk-XXX",
"ENV_HOST": "http://xxx.xxx.xxx.xxx"
}
- Run the relay:
python llm_relay.py- Run a webserver to view the index:
python -m http.server 8081Now, your CircuitStream relay is up and running on http://localhost:8000/ and you can also browse http://localhost:8081 to view analytics.
Usage 🖥️
Here's how to send a request:
curl -X POST http://localhost:8000/callmodel \
-H "Content-Type: application/json" \
-d '{
"project_name": "openai",
"model_name": "gpt-4",
"prompt": "Hello World!",
"api_token": "your-api-key-here"
}'
curl -X POST http://localhost:8000/callmodel \
-H "Content-Type: application/json" \
-d '{
"project_name": "anthropic",
"model_name": "claude-2",
"prompt": "H\nHuman: Hello, world!\n\nAssistant:",
"api_token": "your-api-key-here"
}'
For additional routes and functionalities, refer to the API documentation generated with FastAPI.
Contributing 🤝
We love contributions! If you have any improvements or feature suggestions, please:
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/FeatureName) - Commit your Changes (
git commit -m 'Add some FeatureName') - Push to the Branch (
git push origin feature/FeatureName) - Open a Pull Request
License 📜
Distributed under the MIT License. See LICENSE for more information.
Acknowledgements 🎉
Support 🌐
Having issues? Open an issue and let's debug it together!