Windows10 20H2
gcc version 8.1.0
编写语法分析程序,实现对算术表达式的语法分析。要求所分析算术表达式由如下文法产生:
-
在对输入的算法表达式进行分析的过程中,依次输出所采用的表达式。
-
编写LL(1)语法分析程序,要求如下。
- 编程实现如下算法1,为给定文法自动构造预测分析表。
for(文法中的每一产生式A->α) { for(每个终结符号a∈First(α)) 把A->α放入表项M[A,a]中; if(ε∈FIRST(α)) for(每个b∈FOLLOW(A))把A->α放入表项M[A,b]中; }
- 编程实现如下算法2,构造LL(1)预测分析程序。
do { 令X是栈顶文法符号,a是ip所指向的输入符号; if(X是终结符号或者$) { if(X==a) { 从栈顶弹出X; ip前移一个位置; } else error(); } else /* X是非终结符号 */ { if(M[X,a] = X->Y1Y2...Yk) { 从栈顶弹出X; 依次把Yk,Yk-1,...,Y2,Y1压入栈; /* Y1在栈顶 */ 输出产生式X->Y1Y2...Yk; } else error(); } }while(X!=$) /* 栈非空,分析继续 */
本次实验要使用到上次实验的词法分析器,不过会因为文法进行一定程度的修改。本次文法仅支持num、+、-、*、/、(、)这7种非空终结符存在,所以其他所有终结符都是非法字符。因为分析式中有数字,可能会有字母,所以需要先用词法分析器将分析式进行初步加工,加工成能用以上7中终结符囊括的式子,再去进行语法分析。
由于First集合Follow集都有涉及到相互包含关系,可能会出现复杂的递归情况,所以先手动计算出该文法的First集和Follow集会更为方便。并且由于要求First集,所以需要将文法消除左递归,得到如下文法:
从而得到First集和Follow集
| E | E' | T | T' | F | |
|---|---|---|---|---|---|
| First |
(、num
|
+、-、ε
|
(、num
|
*、/
|
(、num
|
| Follow |
)、$
|
)、$
|
+、-、)、$
|
+、-、)、$
|
+、-、*、/、)、$
|
再将次表写入到程序中,通过算法1,生成对应的预测分析表:

通过算法2,对分析式进行预测分析,并记录下每一步的栈状态,输入字符串状态和输出结果。
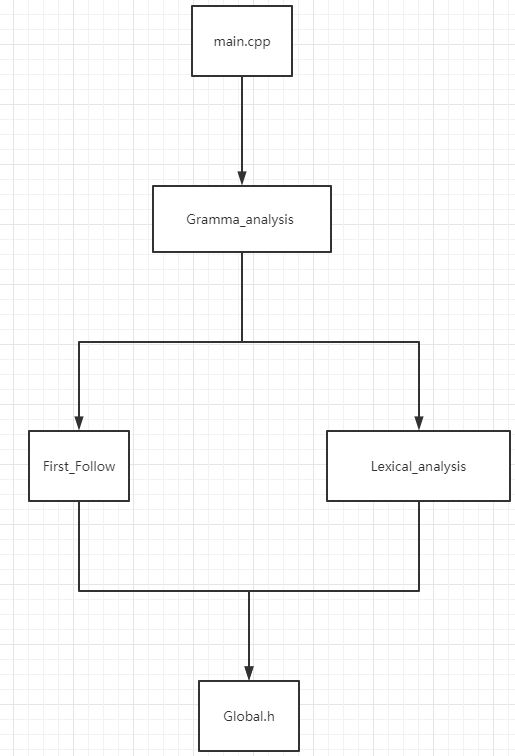
其中,Gramma_analysis是用来封装文法分析的类,First_Follow是用来封装First集和Follow集、以及预测分析表相关的类,Lexical_analysis是封装词法分析的类,Global.h用来保存调用的头文件和全部定量。
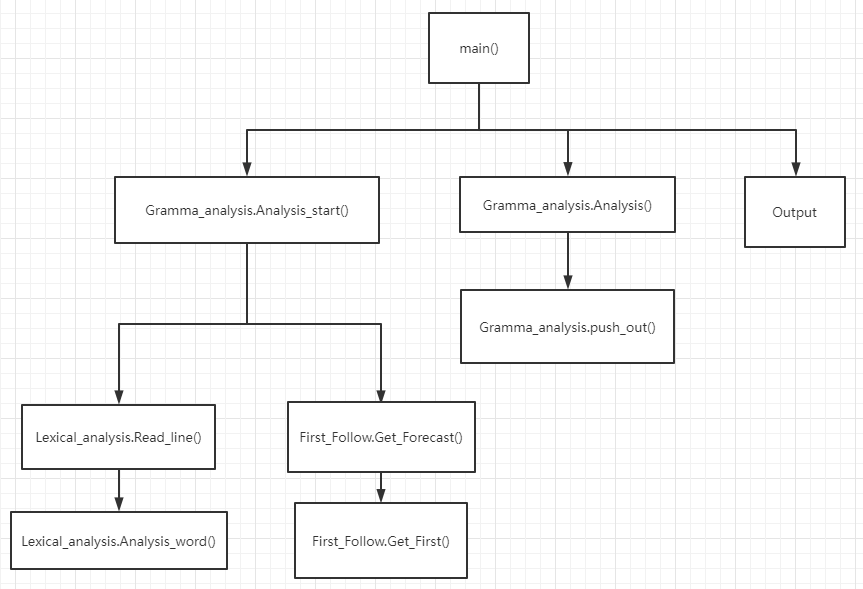
| 类 | 函数名 | 函数功能 |
|---|---|---|
Gramma_analysis |
Analysis_start() |
语法分析之前的准备工作,例如进行词法分析、构建预测分析表 |
Gramma_analysis |
Analysis() |
语法分析,算法2的实现 |
Gramma_analysis |
push_out() |
每一进行一步预测分析,保存一次结果 |
Lexical_analysis |
Read_line() |
按行读取分析式 |
Lexical_analysis |
Analysis_word() |
词法分析 |
First_Follow |
Get_Forecast() |
构建预测分析表 |
First_Follow |
Get_first(string) |
判断生成式(参数)的First集是否有空集 |
bool flag = false;
for (int i = 0; i < 5; i++)
{
flag = false;
for (int j = 0; j < mapping[i].size(); j++)//枚举生成式
{
flag = flag| Get_First(mapping[i][j],i);//将生成式填入M[A,a]中,同时判断生成式的First集是否有ε
}
if (flag)//生成式的FIRST集有ε
{
for (int j = 0; j < follow[i].size(); j++)
{
Forecast_Analysis_Table[i][follow[i][j]] = "ε";
}
}
} 先判断是否有生成式就是$$\varepsilon$$
bool First_Follow::Get_First(string now_mapping,int now_num)//查询生成式的FIRST集
{
bool flag = false;
vector <string> words = splitx(now_mapping, " ");//切割单词,求每个生成式的FIRST
if (words[0] == "null") return true;
{
/* 中间部分 */
}
return flag;//true则说明有ε
} 然后判断从左到右判断是否是非终结符,非终结符First集是否有$$\varepsilon$$
for (int i = 0; i < words.size(); i++)
{
bool flag1 = false;
bool flag2 = false;
for (int j = 0; j < 5; j++)//如果首部是非终结符
{
if(words[i] == not_terminal[j])
{
flag1 = true;
for (int k = 0; k < first[j].size(); k++)
{
if (first[j][k] == 8)//非终结符的FIRST有空集
{
flag2 = true;
continue;
}
Forecast_Analysis_Table[now_num][first[j][k]] = now_mapping;
}
break;
}
}
if (flag1 && !flag2) //非终结符非空
{
flag = false;
break;
}
if (flag1 && flag2) //非终结符含空
{
flag = true;
continue;
}
/* 终结符部分 */
}判断是终结符,则该生成式First集就是该终结符:
for (int j = 0; j < 8; j++)//如果首部是终结符
{
if(words[i] == terminal[j])
{
flag = false;
Forecast_Analysis_Table[now_num][j] = now_mapping;
break;
}
}
if (!flag) break;//首部是非终结符,且FIRST有空集 每次读取栈顶元素
string now;
while(!stack_.empty())
{
now = stack_.top();
{
/* 非终结符部分 */
}
{
/* 终结符部分 */
}
}当栈顶是终结符的时候
if (get_terminal(now) != -1)//终结符
{
if(types[0] == now)
{
types.erase(types.begin());
push_out();
stack_.pop();
answer.push_back(MATCH_SUCCESS);
}
else
{
error(1);//栈顶终结符不匹配,说明出错
return;
}
}当栈顶是非终结符的时候
if (get_not_terminal(now) != -1)//非终结符
{
int word_number = get_terminal(types[0]);//找到在映射中的代号
int now_number = get_not_terminal(now);
string generative = first_follow_.Forecast_Analysis_Table[now_number][word_number];//查预测分析表
if (generative != "")
{
vector <string> word = first_follow_.splitx(generative, " ");
string now_answer = now + "=>";
for(int i =0;i<word.size();i++)
{
now_answer += word[i];
}
answer.push_back(now_answer);//保存生成式
push_out();
stack_.pop();//旧的非终结符出栈
for (int i = word.size() - 1; i >= 0; i--)
{
if (word[i] == "ε") continue;
stack_.push(word[i]);//生成式入栈
}
}
else//预测分析表该位置为空
{
error(0);
return;
}
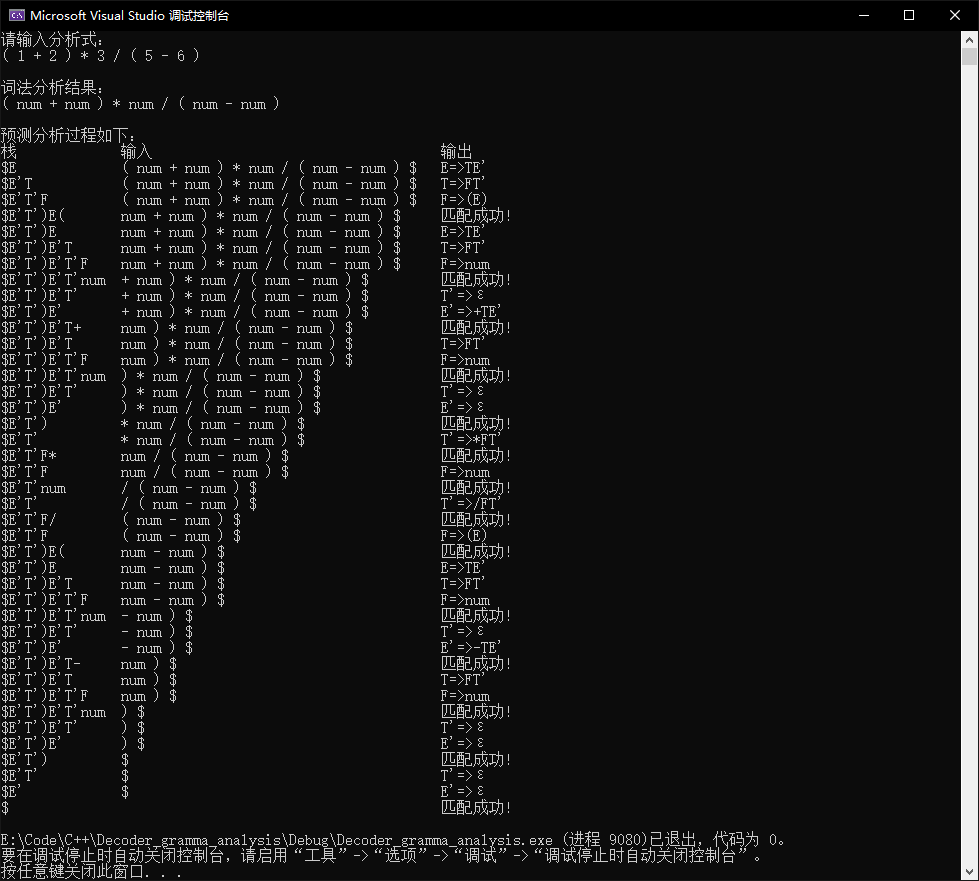
}( 1 + 2 ) * 3 / ( 5 - 6 )
正常的数据,包含所有的终结符,用来测试程序的正常进行。
正常运行。
12+3+
简单的语法错误测试
词法分析正确,输出词法分析结果,但语法分析错误

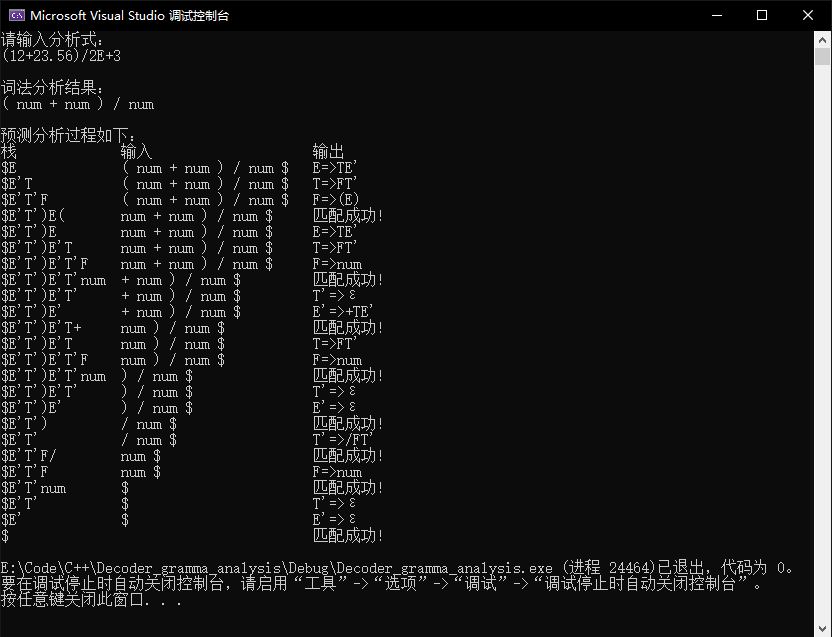
(12+23.56)/2E+3
含有小数和对数的测试,是对词法分析的测试
正常运行,正确识别数字
13++5
不符合文法的式子,用来测试语法分析器的校错能力
检测到预测分析表为空的部分的式子,直接报错结束程序。

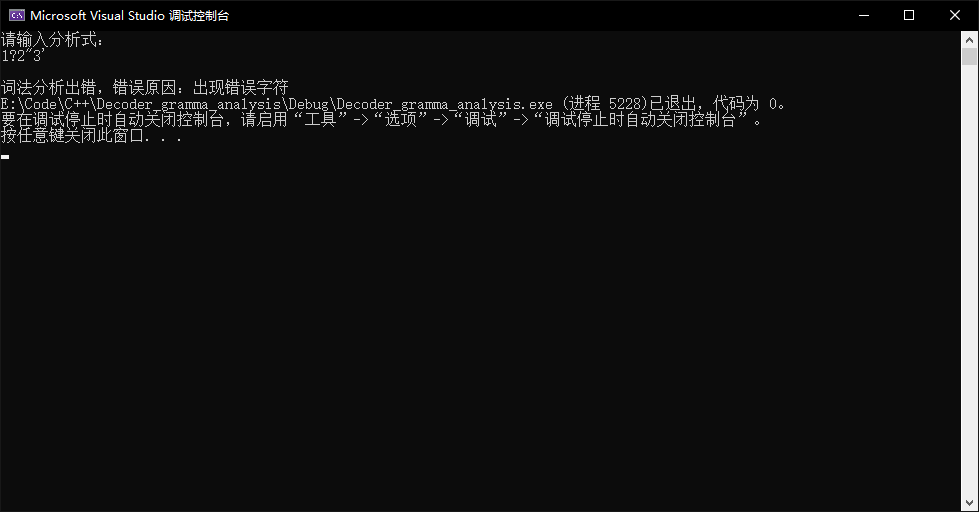
1?2"3'
非法字符,测试词法分析错误时,语法分析器会怎么响应
直接报错,报错内容为词法分析错误