中文车牌识别系统基于crnn 车牌检测看这里车牌检测
- WIN 10 or Ubuntu 16.04
- **PyTorch > 1.2.0 (may fix ctc loss)**🔥
- yaml
- easydict
- tensorboardX
-
从CCPD和CRPD截下来的车牌小图以及我自己收集的一部分车牌 dataset 提取码:g08q
-
数据集打上标签,生成train.txt和val.txt
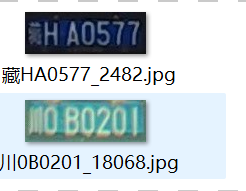
图片命名如上图:车牌号_序号.jpg 然后执行如下命令,得到train.txt和val.txt
python plateLabel.py --image_path your/train/img/path/ --label_file datasets/train.txt python plateLabel.py --image_path your/val/img/path/ --label_file datasets/val.txt数据格式如下:
train.txt
/mnt/Gu/trainData/plate/new_git_train/CCPD_CRPD_ALL/冀BAJ731_3.jpg 5 53 52 60 49 45 43 /mnt/Gu/trainData/plate/new_git_train/CCPD_CRPD_ALL/冀BD387U_2454.jpg 5 53 55 45 50 49 70 /mnt/Gu/trainData/plate/new_git_train/CCPD_CRPD_ALL/冀BG150C_3.jpg 5 53 58 43 47 42 54 /mnt/Gu/trainData/plate/new_git_train/CCPD_CRPD_OTHER_ALL/皖A656V3_8090.jpg 13 52 48 47 48 71 45 /mnt/Gu/trainData/plate/new_git_train/CCPD_CRPD_OTHER_ALL/皖C91546_7979.jpg 13 54 51 43 47 46 48 /mnt/Gu/trainData/plate/new_git_train/CCPD_CRPD_OTHER_ALL/皖G88950_1540.jpg 13 58 50 50 51 47 42 /mnt/Gu/trainData/plate/new_git_train/CCPD_CRPD_OTHER_ALL/皖GX9Y56_2113.jpg 13 58 73 51 74 47 48 -
将train.txt val.txt路径写入lib/config/360CC_config.yaml 中
DATASET: DATASET: 360CC ROOT: "" CHAR_FILE: 'lib/dataset/txt/plate2.txt' JSON_FILE: {'train': 'datasets/train.txt', 'val': 'datasets/val.txt'}

[run] python train.py --cfg lib/config/360CC_config.yaml
结果保存再output文件夹中
python demo.py --model_path saved_model/best.pth --image_path images/test.jpg
or your/model/path

结果是:

python export.py --weights saved_model/best.pth --save_path saved_model/best.onnx --simplify
导出onnx文件为 saved_model/best.onnx
python onnx_infer.py --onnx_file saved_model/best.onnx --image_path images/test.jpg
双层车牌这里采用拼接成单层车牌的方式:
python:
def get_split_merge(img):
h,w,c = img.shape
img_upper = img[0:int(5/12*h),:]
img_lower = img[int(1/3*h):,:]
img_upper = cv2.resize(img_upper,(img_lower.shape[1],img_lower.shape[0]))
new_img = np.hstack((img_upper,img_lower))
return new_img
c++:
cv::Mat get_split_merge(cv::Mat &img) //双层车牌 分割 拼接
{
cv::Rect upper_rect_area = cv::Rect(0,0,img.cols,int(5.0/12*img.rows));
cv::Rect lower_rect_area = cv::Rect(0,int(1.0/3*img.rows),img.cols,img.rows-int(1.0/3*img.rows));
cv::Mat img_upper = img(upper_rect_area);
cv::Mat img_lower =img(lower_rect_area);
cv::resize(img_upper,img_upper,img_lower.size());
cv::Mat out(img_lower.rows,img_lower.cols+img_upper.cols, CV_8UC3, cv::Scalar(114, 114, 114));
img_upper.copyTo(out(cv::Rect(0,0,img_upper.cols,img_upper.rows)));
img_lower.copyTo(out(cv::Rect(img_upper.cols,0,img_lower.cols,img_lower.rows)));
return out;
}
 通过变换得到
通过变换得到 
- 修改alphabets.py,修改成你自己的字符集,plateName,plate_chr都要修改,plate_chr 多了一个空的占位符'#'
- 通过plateLabel.py 生成train.txt, val.txt
- 训练
cd Text-Image-Augmentation-python-master
python demo1.py --src_path /mnt/Gu/trainData/test_aug --dst_path /mnt/Gu/trainData/result_aug/
src_path 是数据路径, dst_path是保存的数据路径
然后把两份数据放到一起进行训练,效果会好很多!
有问题可以提issues 或者加qq群:871797331 询问