Sequence to sequence model for dependency parsing based on OpenNMT-py
This is a Seq2seq model implemented based on OpenNMT-py. It is designed to be presents a seq2seq dependency parser by directly predicting the relative position of head for each given presents a seq2seq dependency parser by directly predicting the relative position of head for each given word, which therefore results in a truly end-to-end seq2seq dependency parser for the first time.word, which therefore results in a truly end-to-end seq2seq dependency parser.
Enjoying the advantage of seq2seq modeling, we enrich a series of embedding enhancement, including firstly introduced subword and node2vec augmentation. Meanwhile, we propose a beam search decoder with tree constraint and subroot decomposition over the sequence to furthermore enhance our seq2seq parser.
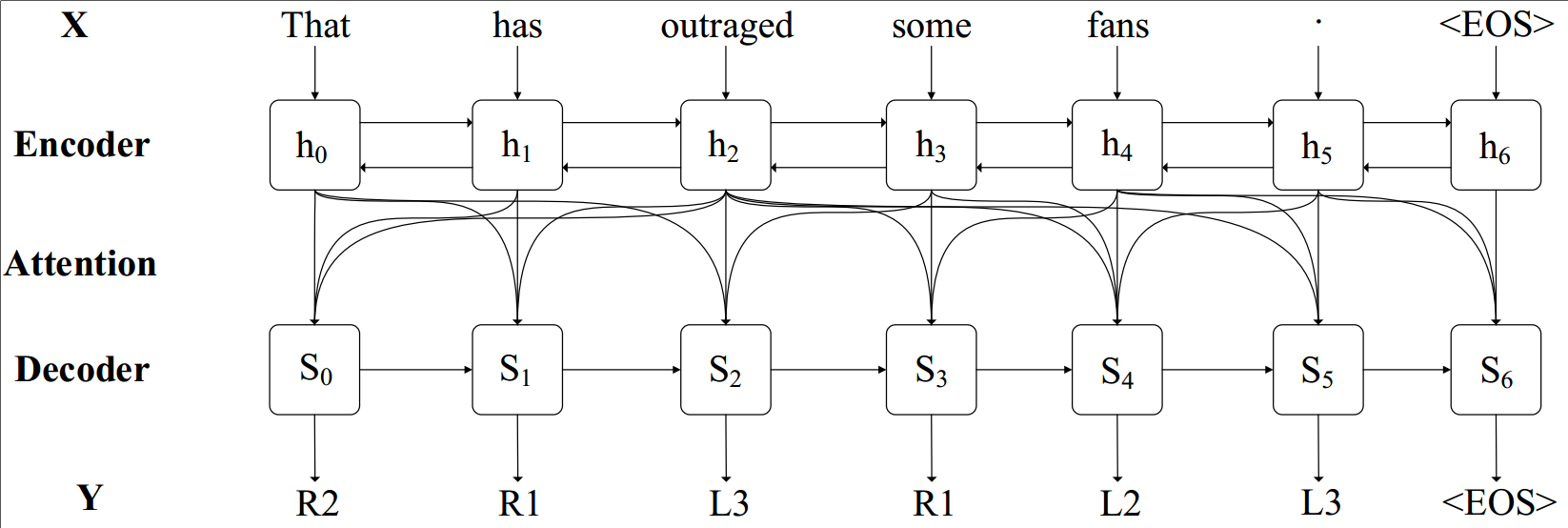
The framework of the proposed seq2seq model:
Requirements
pip install -r requirements.txtthis project is tested on pytorch 0.3.1, the other version may need some modification.
Quickstart
Step 1: Convert the dependency parsing dataset
python data/scripts/make_dp_dataset.pyStep 2: Preprocessing the data
python preprocess.py -train_src data/input/dp/src_ptb_sd_train.input -train_tgt data/input/dp/tgt_ptb_sd_train.input -valid_src data/input/dp/src_ptb_sd_dev.input -valid_tgt data/input/dp/tgt_ptb_sd_dev.input -save_data data/temp/dp/dpWe will be working with some example data in data/ folder.
The data consists of parallel source (src) and target (tgt) data containing one sentence per line with tokens separated by a space:
src-train.txttgt-train.txtsrc-val.txttgt-val.txt
Validation files are required and used to evaluate the convergence of the training. It usually contains no more than 5000 sentences.
After running the preprocessing, the following files are generated:
dp.train.pt: serialized PyTorch file containing training datadp.valid.pt: serialized PyTorch file containing validation datadp.vocab.pt: serialized PyTorch file containing vocabulary data
Internally the system never touches the words themselves, but uses these indices.
Step 2: Make the pretrain embedding
python tools/embeddings_to_torch.py -emb_file_enc data/pretrain/glove.6B.100d.txt -dict_file data/temp/dp/dp.vocab.pt -output_file data/temp/dp/en_embeddings -type GloVeStep 3: Train the model
python train.py -save_model data/model/dp/dp -batch_size 64 -enc_layers 4 -dec_layers 2 -rnn_size 800 -word_vec_size 100 -feat_vec_size 100 -pre_word_vecs_enc data/temp/dp/en_embeddings.enc.pt -data data/temp/dp/dp -encoder_type brnn -gpuid 0 -position_encoding -bridge -global_attention mlp -optim adam -learning_rate 0.001 -tensorboard -tensorboard_log_dir logs -elmo -elmo_size 500 -elmo_options data/pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json -elmo_weight data/pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 -subword_elmo -subword_elmo_size 500 -subword_elmo_options data/pretrain/subword_elmo_options.json -subword_weight data/pretrain/en.wiki.bpe.op10000.d50.w2v.txt -subword_spm_model data/pretrain/en.wiki.bpe.op10000.model- elmo_2x4096_512_2048cnn_2xhighway_options.json
- elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5
- subword_elmo_options.json
- en.wiki.bpe.op10000.d50.w2v.txt
- en.wiki.bpe.op10000.model
You can download these files from here.
Step 3: Translate
python translate.py -model data/model/dp/xxx.pt -src data/input/dp/src_ptb_sd_test.input -tgt data/input/dp/tgt_ptb_sd_test.input -output data/results/dp/tgt_ptb_sd_test.pred -replace_unk -verbose -gpu 0 -beam_size 64 -constraint_length 8 -alpha_c 0.8 -alpha_p 0.8Now you have a model which you can use to predict on new data. We do this by running beam search where constraint_length, alpha_c, alpha_p are parameters used in tree constraints.
Notes
You can refer to our paper for more details. Thank you!
Citation
@inproceedings{li2018seq2seq,
title={Seq2seq dependency parsing},
author={Li, Zuchao and He, Shexia and Zhao, Hai},
booktitle={Proceedings of the 27th International Conference on Computational Linguistics (COLING 2018)},
year={2018}
}