[TOC]
<-. (`-')_ (`-') _ (`-') (`-') _
\( OO) ) ( OO).-/ .-> <-.(OO ) (OO ).-/ <-.
,--./ ,--/ (,------.,--.(,--. ,------,) / ,---. ,--. )
| \ | | | .---'| | |(`-')| /`. ' | \ /`.\ | (`-')
| . '| |)(| '--. | | |(OO )| |_.' | '-'|_.' | | |OO )
| |\ | | .--' | | | | \| . .'(| .-. |(| '__ |
| | \ | | `---.\ '-'(_ .'| |\ \ | | | | | |'
`--' `--' `------' `-----' `--' '--' `--' `--' `-----'
作者:echo(李景枫 or 李茹钰)
微服务架构中的神经组织,主要为分布式架构提供了集群容错的三大利刃:限流、降级和熔断。并同时提供了SPI、过滤器、JWT、重试机制、插件机制。此外还提供了很多小的黑科技(如:IP黑白名单、UUID加强版、Snowflake和大并发时间戳获取等)。
核心功能:
- 限流:致力于解决外部流量的冲击压力
- 降级:致力于解决内部服务的故障事件
- 熔断:致力于解决内部服务的稳定性
- 重试:致力于提高外部服务的成功率
交流群
| QQ交流群:191958521(微服务基础设施) | 微信交流群:echo-lry(备注拉群要求) | 微信公众号:微技术栈 |
 |
 |
 |
- 分布式限流(
Limiter)- 致力于分布式服务调用的流量控制,可以在服务之间调用和服务网关中进行限流!
- 服务降级(
Degrade)- 致力于提供分布式的服务降级开关!
- 个性化重试(
Retryer)- 致力于打造更加智能的重试机制,带你见证重试AI!
- 服务鉴权(
Auth)- 致力于保证每次分布式调用鉴定,可在服务注册、订阅及调用环节进行服务鉴权!
- 链路追踪(
Trace)- 致力于为微服务架构提供链路追踪的埋点!
- 黑科技
Perf:性能测试神器,可以用于为单个方法或代码块进行性能测试NUUID:UUID扩展版,提供更丰富的UUID生产规则Filter:基于责任链模式的过滤器IPFilter:IP黑白名单过滤器Snowflake:基于Snowflake算法的分布式ID生成器SystemClock:解决大并发场景下获取时间戳时的性能问题
- JDK标准的SPI会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源
- 不支持扩展点的IoC和AOP
- 不支持实现排序
- 不支持实现类分组
- 不支持单例/多例的选择
- 支持自定义实现类为单例/多例
- 支持设置默认的实现类
- 支持实现类order排序
- 支持实现类定义特征属性category,用于区分多维度的不同类别
- 支持根据category属性值来搜索实现类
- 支持自动扫描实现类
- 支持手动添加实现类
- 支持获取所有实现类
- 支持只创建所需实现类,解决JDK原生的全量方式
- 支持自定义ClassLoader来加载class
TODO:需要实现对扩展点IoC和AOP的支持,一个扩展点可以直接setter注入其它扩展点。
第一步:定义接口
@SPI
public interface IDemo {}第二步:定义接口实现类
@Extension("demo1")
public class Demo1Impl implements IDemo {}
@Extension("demo2")
public class Demo2Impl implements IDemo {}第三步:使用接口全路径(包名+类名)创建接口资源文件
src/main/resources/META-INF/neural/io.neural.demo.IDemo
第四步:在接口资源文件中写入实现类全路径(包名+类名)
io.neural.demo.Demo1Impl
io.neural.demo.Demo2Impl
第五步:使用ExtensionLoader来获取接口实现类
public class Demo{
public static void main(String[] args){
IDemo demo1 =ExtensionLoader.getLoader(IDemo.class).getExtension("demo1");
IDemo demo2 =ExtensionLoader.getLoader(IDemo.class).getExtension("demo2");
}
}在分布式架构中,限流的场景主要分为两种:injvm模式和cluster模式。

使用JDK中的信号量(Semaphore)进行控制。
public class Test{
public static void main(String[] args){
Semaphore semaphore = new Semaphore(10,true);
semaphore.acquire();
//do something here
semaphore.release();
}
}使用Google的Guava中的限速器(RateLimiter)进行控制。
public class Test{
public static void main(String[] args){
RateLimiter limiter = RateLimiter.create(10.0); // 每秒不超过10个任务被提交
limiter.acquire(); // 请求RateLimiter
}
}分布式限流主要适用于保护集群的安全或者用于严格控制用户的请求量(API经济)。
https://www.jianshu.com/p/a3d068f2586d
- 定义:瞬时并发数,系统同时处理的请求/事务数量
- 优点:这个算法能够实现控制并发数的效果
- 缺点:使用场景比较单一,一般用来对入流量进行控制
- 定义:时间窗最大请求数,指定的时间范围内允许的最大请求数
- 优点:这个算法能够满足绝大多数的流控需求,通过时间窗最大请求数可以直接换算出最大的QPS(QPS = 请求数/时间窗)
- 缺点:这种方式可能会出现流量不平滑的情况,时间窗内一小段流量占比特别大
算法描述
- 假如用户配置的平均发送速率为r,则每隔1/r秒一个令牌被加入到桶中
- 假设桶中最多可以存放b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃
- 当流量以速率v进入,从桶中以速率v取令牌,拿到令牌的流量通过,拿不到令牌流量不通过,执行熔断逻辑
属性
- 长期来看,符合流量的速率是受到令牌添加速率的影响,被稳定为:r
- 因为令牌桶有一定的存储量,可以抵挡一定的流量突发情况
- M是以字节/秒为单位的最大可能传输速率。 M>r
- T max = b/(M-r) 承受最大传输速率的时间
- B max = T max * M 承受最大传输速率的时间内传输的流量
优点:流量比较平滑,并且可以抵挡一定的流量突发情况
在分布式架构中,熔断的场景主要分为两种:injvm模式和cluster模式。
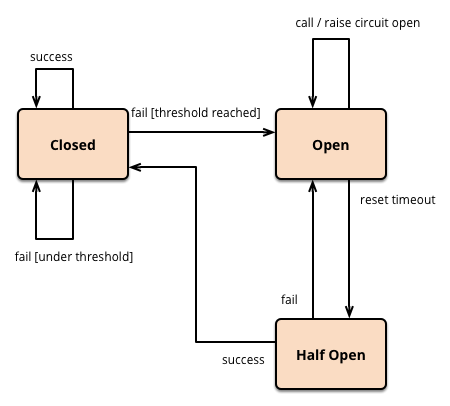
在指定时间周期内根据事件发生的次数来实现精简版熔断器。如10秒之内触发5次事件,则进行熔断。
TODO
服务降级是指当服务器压力剧增时,根据当前业务情况及流量对一些服务和页面有策略的降级,以此缓解了服务器资源压力,以保证核心任务的正常运行,同时也保证了部分甚至大部分客户得到正确响应。
当服务器检测到压力增大,服务器监测自动发送通知给运维人员,运维人员根据自己或相关人员判断后通过配置平台设置当前运行等级来降级。降级首先可以对非核心业务进行接口降级。如果效果不显著,开始对一些页面进行降级,以此保证核心功能的正常运行。
业务确定好对应业务的优先级别,指定好分级降级方案。当服务器检测到压力增大,服务检测自动发送通知给运维人员。运维人员根据情况选择运行等级。
使当前线程使用Thread.sleep()的方式进行休眠重试。
- NeverStopStrategy:从不停止策略
- StopAfterAttemptStrategy:尝试后停止策略
- StopAfterDelayStrategy:延迟后停止策略
- FixedWaitStrategy:固定休眠时间等待策略
- RandomWaitStrategy:随机休眠时间等待策略,支持设置随机休眠时间的下限值(minmum)与上限值(maxmum)
- IncrementingWaitStrategy:定长递增休眠时间等待策略
- ExponentialWaitStrategy:指数函数(2^x,其中x表示尝试次数)递增休眠时间等待策略。支持设置休眠时间的上限值(maximumWait)
- FibonacciWaitStrategy:斐波那契数列递增休眠时间等待策略。支持设置休眠时间的上限值(maximumWait)
- CompositeWaitStrategy:复合等待策略,即支持以上等待策略的组合计算休眠时间,最终休眠时间是以上策略中休眠时间之和
- ExceptionWaitStrategy:异常等待策略
retryIfResult(Predicate< V> resultPredicate):设置重试不满足条件的结果
eg:如果返回结果为空则重试:retryIfResult(Predicates.< Boolean>isNull())
- retryIfException():重试所有异常
- retryIfRuntimeException():重试运行时异常
- retryIfExceptionOfType(Class<? extends Throwable> exceptionClass):重试指定类型异常
- retryIfException(Predicate< Throwable> exceptionPredicate) :自定义过滤后的异常重试
withRetryListener(RetryListener listener):添加重试监听器
withAttemptTimeLimiter(AttemptTimeLimiter< V> attemptTimeLimiter):添加尝试时间限制器
功能来源于java-jwt项目,但有一定的调整,后续会继续简化。
基于@SPI扩展方式和责任链模式实现的过滤器机制。
- Perf:性能测试工具
- IPFilter:IP黑白名单过滤器
- SystemClock:解决大并发场景中获取System.currentTimeMillis()的性能问题
- Snowflake:基于Snowflake算法实现的高性能Long型ID生成器。理论QPS > 400w/s
- MicroUUID:UUID扩展版。支持36/32/22/19位的UUID生成方式(不牺牲精度),支持牺牲一定精度后的15位超短UUID