Pour éxecuter vos programmes Hadoop Java, il faudra générer un .jar, puis le copier sur la machine virtuelle pour l’exécuter sur Hadoop, en premier lieu il faut faire une connexion SSH avec machine virtuelle, en utilisant un outil très connu c’est PuTTY, deuxièmement pour transférer votre fichiers qui existent dans votre machine physique vers votre machine virtuelle il faut utiliser WinSCP.
- Utilisation de PuTTY:
PuTTY : est un émulateur de terminal doublé d'un client pour les protocoles SSH, Telnet, rlogin, et TCP brut. Il permet également des connexions directes par liaison série RS-232. À l'origine disponible uniquement pour Windows, il est à présent porté sur diverses plates-formes Unix. Après l’installation de PuTTY, lancer l’émulateur et une fenêtre sera déclenché :
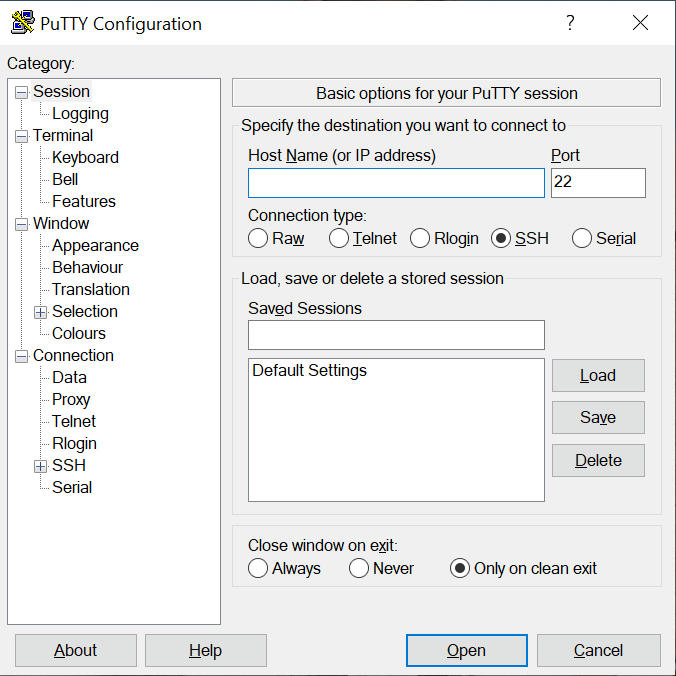
- Pour connecter avec votre machine virtuelle, il faut taper adresse ip de la machine virtuelle et Port (c'est par défaut =22)
- Utilisation de WinSCP :
WinSCP : est un client SFTP graphique pour Windows. Il utilise SSH et est open source. Le protocole SCP est également supporté. Le but de ce programme est de permettre la copie sécurisée de fichiers entre un ordinateur local et un ordinateur distant. Quand on ouvre WinSCP, il déclenche une fenêtre de connexion, il suffit d’entrer l’adresse ip de votre machine virtuelle et port (qui est par défault =2), aussi nom de l’utilisateur = mbds, et password = password.
Après la connexion il nous affiche une fenêtre qui contient deux interfaces, la première qui représente nos fichiers de machine physique et la deuxième interface pour déplacer vos fichiers vers la machine virtuelle.

- Sélectionner le fichier qui contient le code java Hadoop (celle-ci de mon repository), et cliquer sur envoyer pour le déplacer vers notre machine virtuelle :

- Compiler le code, avec la commande : javac analyseVente.java :
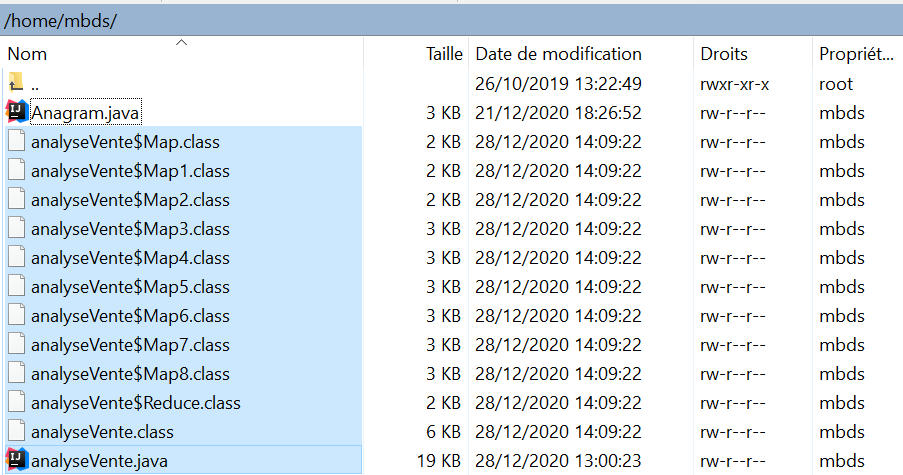
- Construire la hiérarchie du .jar et y déplacer le code compilé :

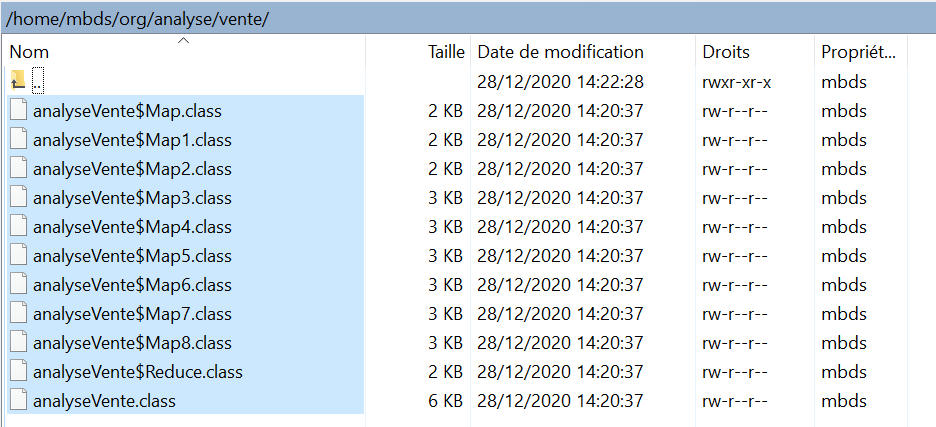
- Générer le jar avec la commande : jar -cvf mbds_analysevente.jar -C . org, j'ai nommé le jar "mbds_analysevente" :
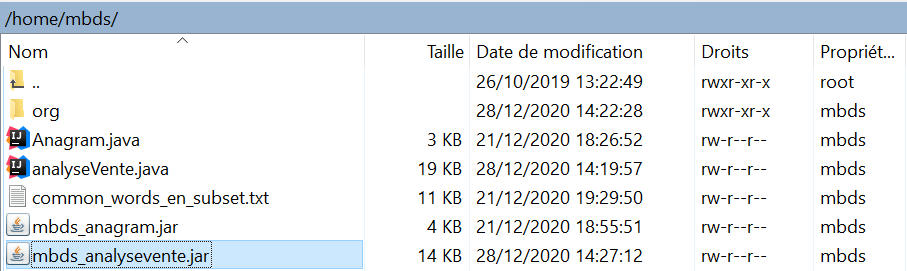
- Après supprimer le répertoire org avec la commande rm -rf org :
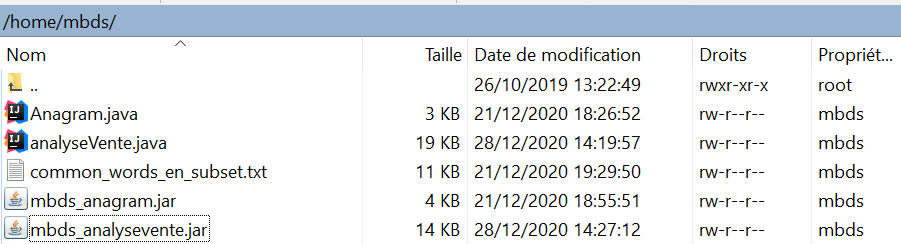
- j'ai déplacé le fichier excel 'sales_world_10k.csv', avec la commande : hadoop fs -put sales_world_10k.csv /

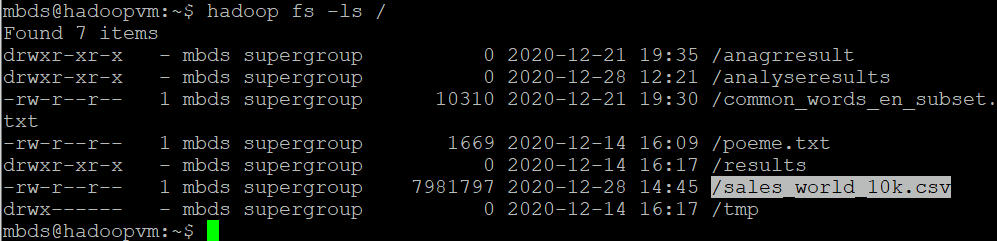
- Vérifiez la présence du fichier sur HDFS, avec la commande : hadoop fs -ls /
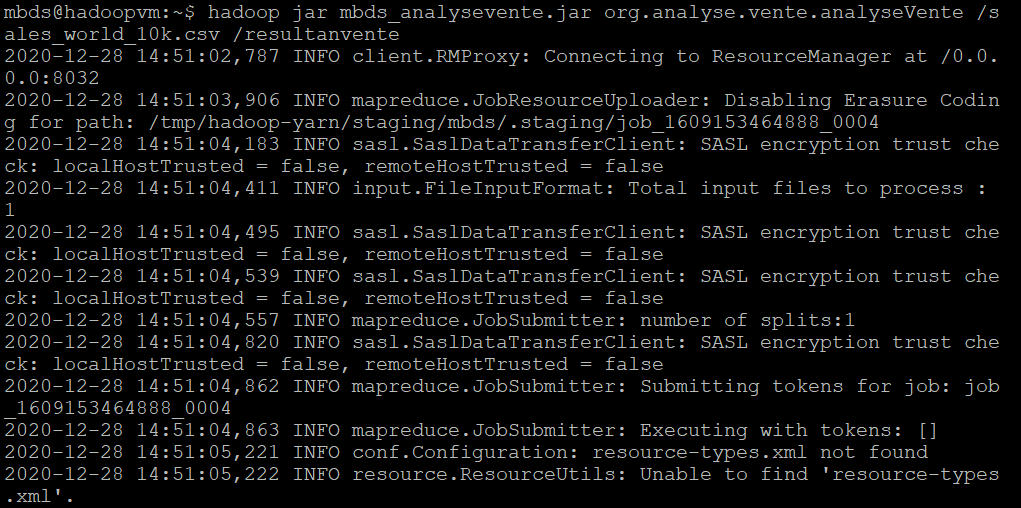
- Exécuter le programme avec la commande : hadoop jar mbds_analysevente.jar org.analyse.vente.analyseVente /sales_world_10k.csv /resultanvente
- Consulter les résultats aprés l’exécution, Taper la commande: hadoop fs -ls /resultanvente

- Ou bien vous pouvez tapez la comande : hadoop fs -cat /resultanvente/*
