![]()
QMR is the CMCS MDCT application for collecting state data for related to measuring and quantifying healthcare processes and ensuring quality healthcare for Medicaid beneficiaries. The collected data assists CMCS in monitoring, managing, and better understanding Medicaid and CHIP programs.
- Getting Started
- Testing
- Services
- Year End Transition Documentation
- Quickstart
- License
The following are prerequisites for local development.
-
Clone this repository locally
git clone git@github.com:Enterprise-CMCS/macpro-mdct-qmr.git
-
Install Node
-
Install Node Version Manager (NVM)
- A specific version of Node is enforced and specified in the file
.nvmrc. This version matches the Lambda runtime.
- A specific version of Node is enforced and specified in the file
-
Install the correct version of Node
# nvm commands will default to Node version defined in .nvmrc nvm install nvm use -
Install Homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" -
Install Yarn
brew install yarn
-
Install Serverless
yarn global add serverless yarn upgrade serverless
-
Install the following Serverless plugins
yarn add serverless-offline yarn add serverless-dynamodb yarn add serverless-s3-local # or install simultaneously yarn add serverless-offline && yarn add serverless-dynamodb && yarn add serverless-s3-local
-
Install all other node packages.
yarn install # can be skipped, will run automatically in dev script -
Set up your local ENV. The dev script will create a .env file for you at the root of the repository on your first run. There should be no changes needed. Compare with other teammates if you encounter problems.
-
Set up the UI-SRC ENV.
- Navigate to
/services/ui-src/. - Make a new file:
.env - Copy the contents of
.env_exampleinto.env- If you want to connect to real resources for the branch you can tweak these values with the resource values found in AWS.
- Navigate to
-
Run the application.
./dev localA number of test users are defined in
users.json. See the AWS section for more specific instructions and test user passwords.
This repo uses the code formatter Prettier. The package is downloaded during yarn install and is run automatically in a pre-commit hook. Additionally, the Prettier formatter can be run on file save in many IDEs or run ad hoc from the command line.
The Prettier extension can be downloaded from the VS Code Marketplace.
Once installed, open VS Code's Preferences. Search for "Format on Save". Clicking the checkbox should engage the Prettier formatter on file save.
VS Code is used almost ubiquitously across the current development team, but similar instructions are available for other IDEs.
Using this command, or a variant of it, will format all matching files in the codebase and write the changes. Prettier has complete CLI documentation on their website.
npx prettier --write . # format everything relative to the pwd
npx prettier --write "**/*.tsx" "**/*.ts" # format all TypeScript filesThe JavaScript unit testing framework being used is Jest, and the React component testing library being used is the React Testing Library.
First, make sure your node_modules are up to date:
- Navigate to tests and run
yarn install
- Navigate to tests/cypress and run
yarn install
- Set Up AWS Credentials Locally
- On your local QMR environment, navigate to
cd tests/cypress - Run
./configureLocal.sh master
The Cypress environment (.env) file will be generated and populated under tests/cypress.env.json.
Once your local environment is up and running, these steps need to be taken to set up Cypress:
cd tests/
yarn install
cd cypress/
yarn install
To run the end-to-end (E2E) Cypress tests:
cd tests/
yarn test
The Cypress application will kick off, where you can find a list of all the available E2E tests.
To run an individual Child Measure test, you first need to create these measures by running the create_delete_child.spec.ts test.
Similarly, to run an individual Health Home Measure test, you first need to create these measures by running the create_delete_healthhome.spec.ts test.
To run the Jest unit tests on the React components:
cd services/ui-src/
yarn test
To run the Jest unit tests on the API endpoints:
cd services/app-api/
yarn test
On the terminal, you will see the unit test results.
For example:

Many of commonly used components and common question components are tested with snapshot tests. Jest's documentation describes what snapshot testing is and how to interact with their tooling.
If a change is made that affects the way a component renders, and that component is covered by snapshot testing, the snapshot tests will fail. This is expected behavior. Output logs should highlight clearly the discrepancies between the rendered component and the stored snapshot. Assuming the changes are anticipated the snapshot should be updated to match the component so tests will pass going forward. See the "Updating Snapshots" section of the Jest docs for specific instructions on overwriting the snapshots. Alternatively, the old snapshot file can be deleted and will be re-generated on the next run of the test.
To view a unit test code coverage report on the React components:
cd services/ui-src/
yarn test --coverage
To view a unit test code coverage report on the API endpoints:
cd services/app-api/
yarn test --coverage
On the terminal, there will be a detailed coverage report followed by a coverage summary similar to this one:


This project is built as a series of micro-services using the Serverless Framework. Serverless looks and feels like a more useful version of CloudFormation Templates, and you can even write Cloudformation inside serverless files.
Every microservice in this project has a corresponding serverless file that deploys everything in the service to a cloudformation stack in AWS. Check out The Docs to learn more about it. But we'll cover a few things here.
The following values are used to configure the deployment of every service (see below for more background and context).
| Parameter | Required? | Accepts a default? | Accepts a branch override? | Purpose |
|---|---|---|---|---|
| .../iam/path | N | Y | Y | Specifies the IAM Path at which all IAM objects should be created. The default value is "/". The path variable in IAM is used for grouping related users and groups in a unique namespace, usually for organizational purposes. |
| .../iam/permissionsBoundaryPolicy | N | Y | Y | Specifies the IAM Permissions Boundary that should be attached to all IAM objects. A permissions boundary is an advanced feature for using a managed policy to set the maximum permissions that an identity-based policy can grant to an IAM entity. If set, this parmeter should contain the full ARN to the policy. |
This project uses AWS Systems Manager Parameter Store, often referred to as simply SSM, to inject environment specific, project specific, and/or sensitive information into the deployment. In short, SSM is an AWS service that allows users to store (optionally) encrypted strings in a directory like hierarchy. For example, "/my/first/ssm/param" is a valid path for a parameter. Access to this service and even individual paramters is granted via AWS IAM.
An example of environment specific information is the id of a VPC into which we want to deploy. This VPC id should not be checked in to git, as it may vary from environment to environment, so we would use SSM to store the id information and use the Serverless Framework's SSM lookup capability to fetcn the information at deploy time.
This project has also implemented a pattern for specifying defaults for variables, while allowing for branch (environment specific overrides). That pattern looks like this:
sesSourceEmailAddress: ${ssm:/configuration/${self:custom.stage}/sesSourceEmailAddress, ssm:/configuration/default/sesSourceEmailAddress}
The above syntax says "look for an ssm parameter at /configuration//sesSourceEmailAddress; if there isn't one, look for a parameter at /configuration/default/sesSourceEmailAddress". With this logic, we can specify a generic value for this variable that would apply to all environments deployed to a given account, but if we wish to set a different value for a specific environment (branch), we can create a parameter at the branch specific path and it will take precedence.
In the above tabular documentation, you will see columns for "Accepts default?" and "Accepts a branch override?". These columns relate to the above convention of searching for a branch specific override but falling back to a default parameter. It's important to note if a parameter can accept a default or can accept an override, because not all can do both. For example, a parameter used to specify Okta App information cannot be set as a default, because Okta can only support one environment (branch) at a time; so, okta_metadata_url is a good example of a parameter that can only be specified on a branch by branch basis, and never as a default.
In the above documentation, you will also see the Parameter value denoted as ".../iam/path", for example. This notation is meant to represent the core of the parameter's expected path. The "..." prefix is meant to be a placeholder for either "/configuration/default" (in the case of a default value) or "/configuration/myfavoritebranch" (in the case of specifying a branch specific override for the myfavoritebranch branch.
As you are developing you may want to debug and not wait for the 12-20 minutes it takes for changes to go through GitHub actions. You can deploy individual services using serverless.
- Ensure all stages of the branch have deployed once through github actions
- set up local AWS credentials
- Navigate to the service you are trying to deploy ie:
/services/app-api - Run
sls deploy --stage branchname, where branchname is the name of your branch.
Destroying is largely the same process as deploying.
- Ensure all stages of the branch have deployed once through github actions
- set up local AWS credentials
- Navigate to the service you are trying to deploy ie:
/services/app-api - Run
sls destroy --stage branchname, where branchname is the name of your branch.
Some known issues with this process of destroying is that S3 buckets will not be deleted properly, so I would recommend destroying through GithubActions or destroying the entire branch.
In some circumstances you may want to remove all resources of a given branch. Occasionally there will be orphaned infrastructure that was not destroyed when the branch was destroyed for one reason or another. The process for destroying the branch
- set up local AWS credentials
brew install jqInstall jq (command-line JSON processor). This is necessary for the destroy script to run properly.sh destroy.sh name_of_your_branchRun destroy script. You will be prompted to re-enter the branch name once it has found all associated resources. (There shouldn't be any errors but if there are any. Re-running the script should fix it)
The API service contains all of the API calls for the application. It is deployed with serverless and depends on the database service to exist first. It can be updated independently from the rest of the application as long as the inital infrastructure for the application has been created. This is to help speed up local deployment and debugging of branch resources and not for updates of any of the higher environments.
Parameters are passed in by the URL in this order state/year/coreset for coreset endpoints and state/year/coreset/measure for measures and are used to determine the unique id of the dynamo record.
The only endpoints that need a body is update
create: Creates the identified coreset, and then creates all child measures corresponding to the Adult, Child, or Health Home coreset.
delete: Deletes the identified coreset, and then deletes all child measures to that coreset.
get: Returns the identified coreset.
list: Given with parameters: state/year to return all the coresets for a given state and year.
update: The body can contain submitted or status to change the status of the coreset
create: Creates the identified coreset. Right now this is only fired directly from the application when a new custom Health Home Measure is created. Otherwise it is used by the create coreset endpoint.
delete: Deletes the identified coreset. Right now this is only fired directly from the application when a new custom Health Home Measure is created. Otherwise it is used by the delete coreset endpoint.
get: Returns the identified measure
list: Given with parameters: state/year/coreset to return all measures corresponding to a given coreset.
update: The body can contain data, status, reporting, description, detailedDescription
The Kafka Queues we link to are in the BigMac account and are currently not being used for any downstream purposes
postKafkaData: Fires when an update to the database happens and syncs kafka to reflect the current state of the database.
forceKafkaSync: This can be manually triggered to force kafka to reflect the current state of the database.
convertToDynamoExpressionVars: Dynamo requires very specific variable naming conventions which are unwieldly to interact with so this util will take all of the arguments and converts them into a dynamo readable version.
A known issue with this utility is that right now it only ands arguments, so if you have a list or get query that needs to exclude characteristics, this utility will need to be updated
createCompoundKey: creates the dynamo key for the coreset or measure based on the passed in parameters.
measureList: A list of all of the measures and the type of coreset they belong to. This is used when a new coreset is created to create new measures for that coreset.
We are using DynamoDb for our database solution for QMR. When looking for the databases in AWS search for branchName-tableName to find the tables for your branch.
coresets: Takes a compound key containing a unique combination of state, year, and coreset ID.
measures: Takes a compound key containing a unique combination of state, year, coreset ID, and Measure ID.
In order to run dynamodb locally you will need to have java installed on your system. If not currently installed go here: https://java.com/en/download/ to download the latest version.
If you want to a visual view of your dynamodb after the application is up and running you can install the dynamodb-admin tool from here: https://www.npmjs.com/package/dynamodb-admin
To run the dynamodb gui, run DYNAMO_ENDPOINT=http://localhost:8000 dynamodb-admin in a new terminal window
From here you can view the tables and perform operations on the local tables.
The stream functions fire deltas when updates to its table happens. These changes are picked up in the API where these changes are communicated to the kafka streams for the application.
The UI Service creates the URL's associated with the application and the cloudfront logs that monitor traffic.
For Master, Val, and Prod these URL's end with .gov the branch URL's end with .com
The Endpoints created by a branch are random and can be found in the output of the cloudformation stack for the UI, it can also be found as an output of the deploy step of our github actions.
The UI Auth service creates and manages the Authentication of the UI.
User data is synced from IDM to Cognito to allow for login to the application and the IDM roles are used to determine what a user has access to in the UI.
Okta is the Federated Identity Provider being used to allow users to use their IDM credentials with our application.
There is one lambda function in the UI-Auth Service, this is to create test users that can login to the branch environments, dev, and Val, for testing, but not production.
To add new users with new attributes, you can edit the users.json
The ui-src service contains all of our frontend code and is therefore the largest service in the project. Our project uses the React Web Framework, Typescript, Chakra-UI for components, react-icons for various icons in the application, and react-query
| Technology | Use | Reason |
|---|---|---|
| React | Library for writing UI Components and Application Organization | We went with React because the majority of the team was comfortable with it, and the quickstart from which this application was forked came with a good React Skeleton |
| Typescript | Maintaining and enforcing types throughout the application | JavaScript does not throw compile-time errors for types which can lead to extremely difficult debugging. It also helps enforce code quality. Typscript's plugins with IDE's also make local development faster and easier by autofilling pieces for known types. |
| Chakra_UI | Rendering UI components and page Layout | We went with Chakra over material because we did a test. We chose one simple component and created it first with Material and then with Chakra. We found that chakra was far easier to develop with so we went with chakra |
| React-Icons | Simple Icons throughout the application | It was free, easy to use, and had all of the icons we needed |
| React-Query | State management | It was the more lightweight option and was more simple to plugin to the application compared to its competetors |
At it's core QMR consists of several small simple components in /services/ui-src/src/components
These are then used to create more complex components in /services/ui-src/src/measures/year/CommonQuestions
These complex components are then used along with some of the simple components to create the forms for the application in /services/ui-src/src/measures/year
When creating a new form it's best to find an existing form that is as close to what you are trying to make as possible, then modifying it with complex components if necessary, or creating a new complex component and modifying it with simple components if necessary etc...
The Uploads service consists of a few S3 buckets and some integration functions. It is the only point where the downstream applications owned by Mathematica interact with our application. This is in two buckets.
- Uploads: This is where attachment files are stored
- DynamoSnapshotBucket: This is where snapshots of our dynamo database are stored as JSON objects for Mathematica to download.
Any uploads are first stored in an inaccessible folder until they are scanned by the anti-virus scanner. Antivirus definitions are updated daily. This is to prevent anyone from uploading malicious files.
The IAM roles that we receive from Mathematica are stored as SSM parameters and can be accessed and changed in the corresponding AWS account.
Go into the services/ui-src/src/measures directory and one should see past years as
folders (2021, 2022, etc.). Ideally, changes to measures would be made from the previous
year to the next so one would make a copy the folder of the most recent year and rename
it to the next year (e.g. 2021 -> 2022). Then go into the folder and make any additions
or removals of measures as needed per requirements.
Once the directory for the new year has been made there are a couple of changes one needs to make in order to get that year working.
-
Go into the
index.tsxfile for the directory you just created (services/ui-src/src/measures/2022/index.tsx) and update the name of the export (twentyTwentyOneMeasures->twentyTwentyTwoMeasures) -
Go to the
services/ui-src/src/measures/index.tsxfile and add that new export (before and after shown below)Before
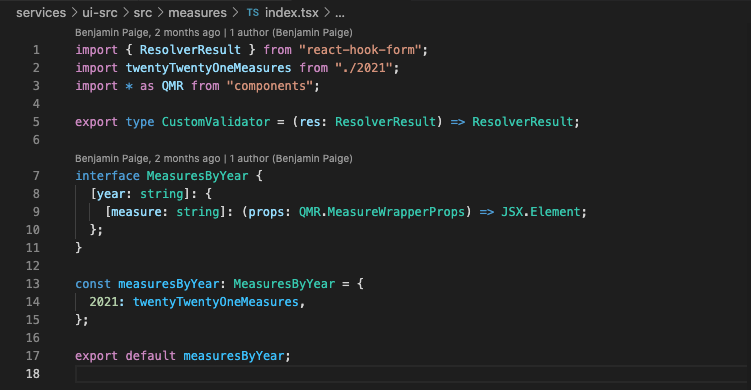
After
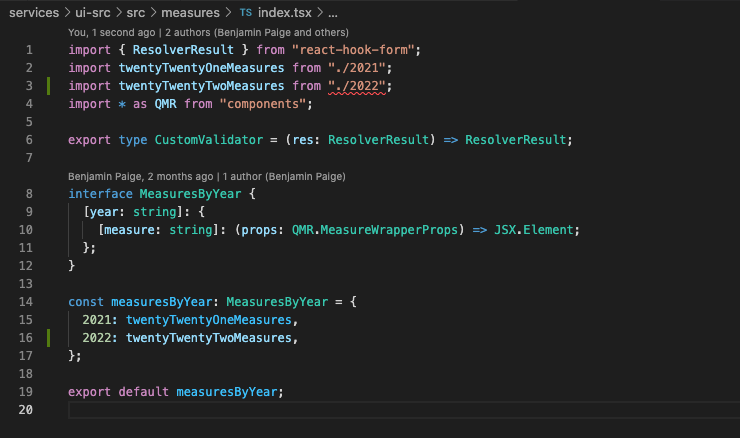
-
Go to the
services/app-api/handlers/dynamoUtils/measureList.tsand copy the array of measures from the previous year and copy them into the new year. Make any additions or removals of measures as needed per requirements. -
Update any import names from the past year to the latest year (e.g. 2021 -> 2022)
Before

After

-
Copy over the
/globalValidations,/CommonQuestions, and/Qualifiersdirectories to the latest year -
Similar to Step 4, update import names from the previous year to the most recent year
Before
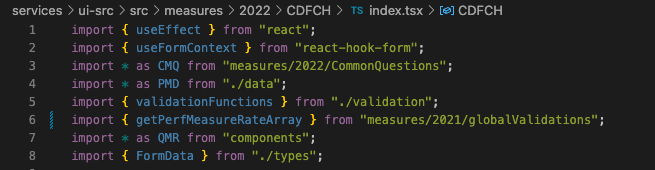
After
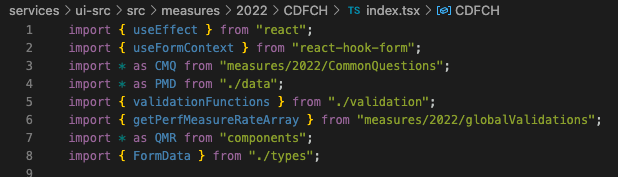
-
In
services/ui-src/src/libs/spaLib.ts, copy over the prior year's entry into the array. -
In
services/ui-src/src/measures/measureDescriptions.ts, copy over the prior year's entry into the array.






If you are creating a new shared component (e.g. files under /globalValidations) while editing the previous year's files, it is possible that merge conflicts will arise. Make sure these concurrent changes are not overwriting or removing necessary code.
This application was forked from the Quickstart Repository and efforts are made to feedback any applicable changes to that repository from this one and vice versa.
See LICENSE for full details.
As a work of the United States Government, this project is
in the public domain within the United States.
Additionally, we waive copyright and related rights in the
work worldwide through the CC0 1.0 Universal public domain dedication.