AMP demonstrating Speech to Text Summarization on CML using OpenAI Whisper
- Speech to Text transcription using OSS Whisper Model
- Summarize transcribed Text using Llama-2 (can be changed during AMP deployment) and LangChain
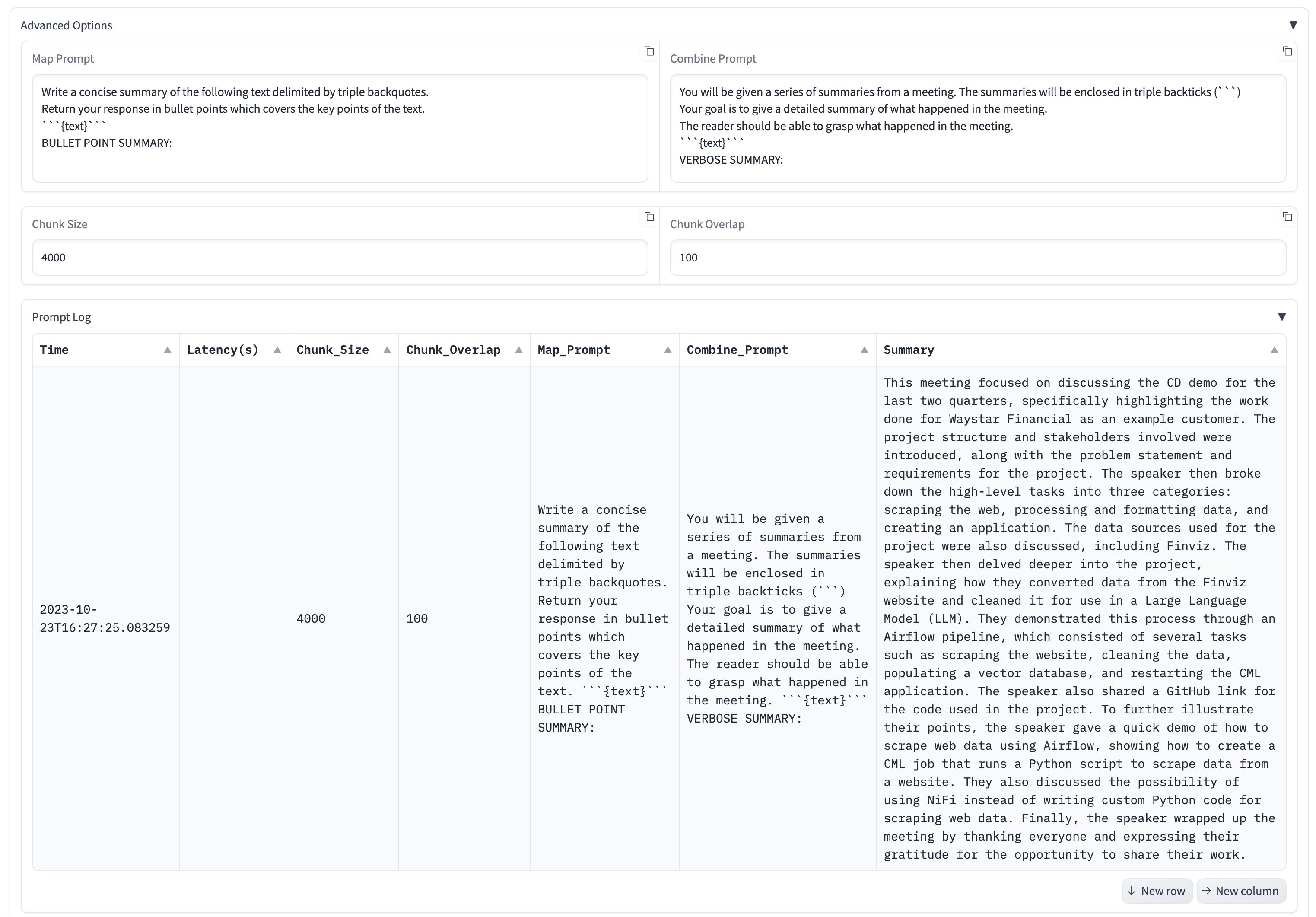
- Customizable Prompts for various summarization use cases
- Prompt Log for monitoring and tracking how different prompts perform. Log gets stored in CSV which can be used as data for fine tuning downstream.
- Custom Runtime Setup with ffmpeg package
The AMP Application has been configured to use the following
- 4 CPU
- 32 GB RAM
- 2 GPUs
-
Navigate to CML Workspace -> Site Administration -> AMPs Tab
-
Under AMP Catalog Sources section, We will "Add a new source By" selecting "Catalog File URL"
-
Provide the following URL and click "Add Source"
https://raw.githubusercontent.com/nkityd09/cml_speech_to_text/main/catalog.yaml
-
Once added, We will be able to see the LLM PDF Document Chatbot in the AMP section and deploy it from there.
-
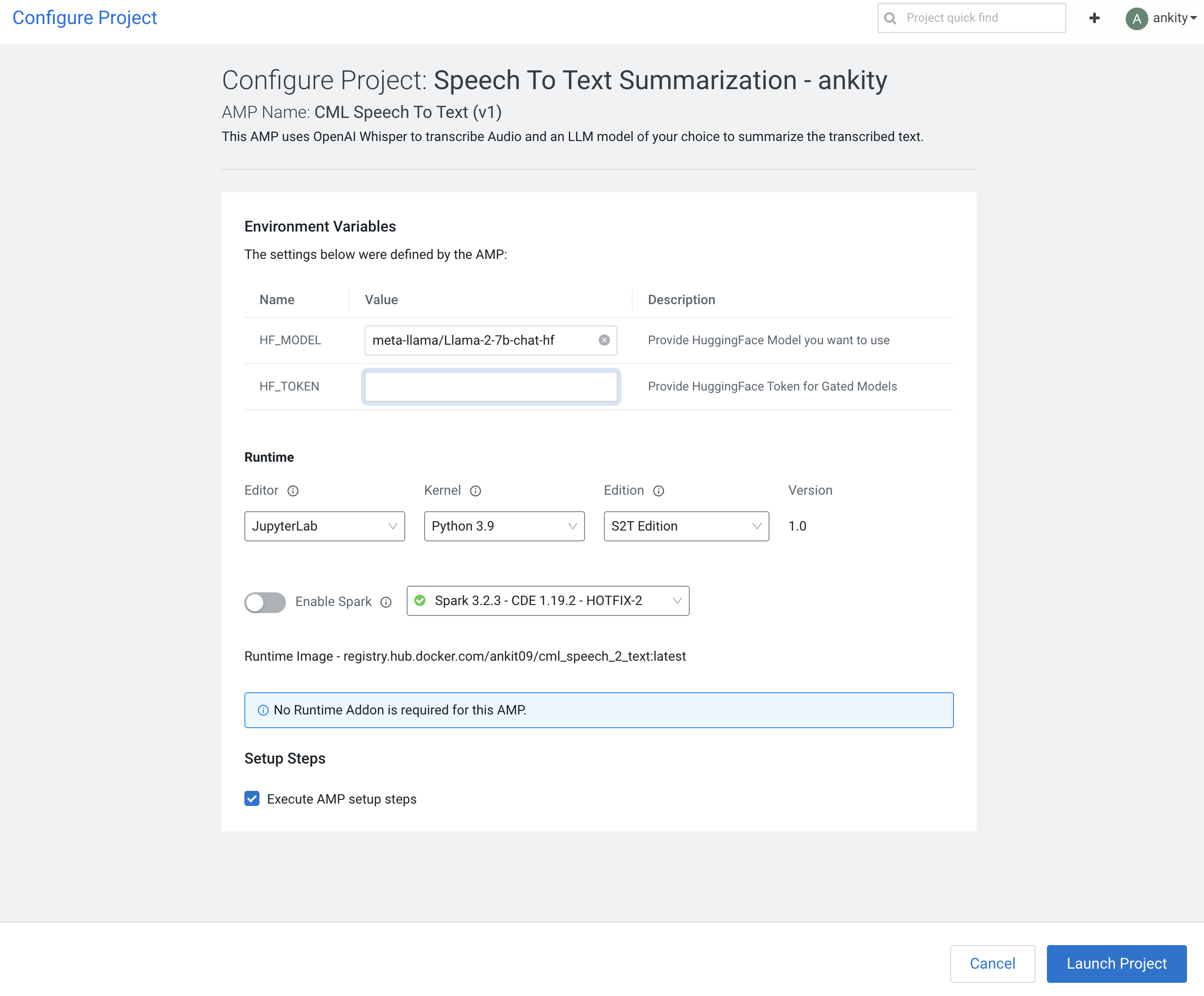
Click on the AMP and "Configure Project"
- Add HuggingFace Model Name, defaults to meta-llama/Llama-2-7b-chat-hf
- If accessing a gated model, add HuggingFace token. Can be left blank for non gated models
-
Once the AMP steps are completed, We can access the Gradio UI via the Applications page.

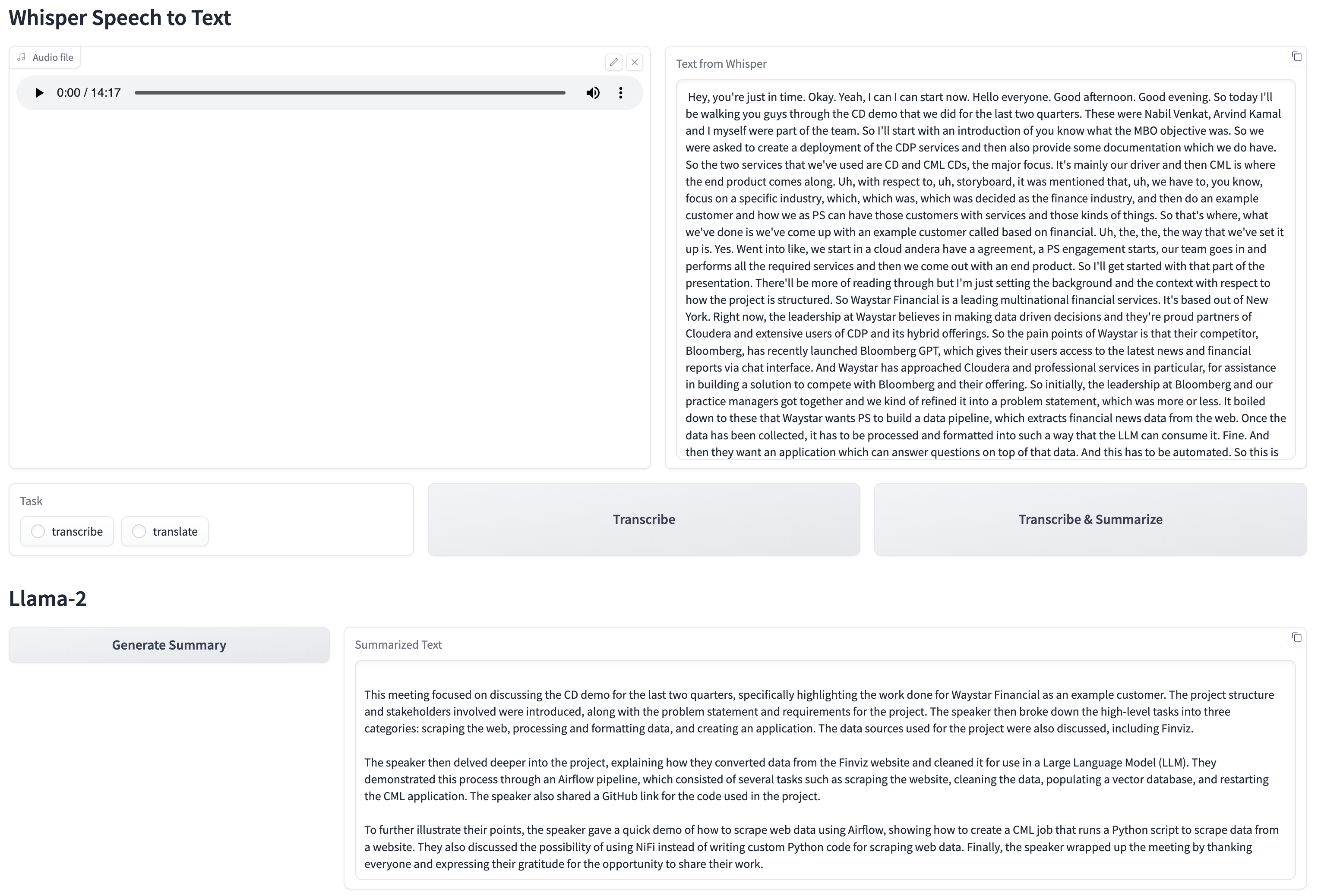
The CML Application serves a Gradio UI to upload Audio files and summarize the text transcribed from the Audio.
- The Gradio UI provides an upload widget which can be used to upload Audio files
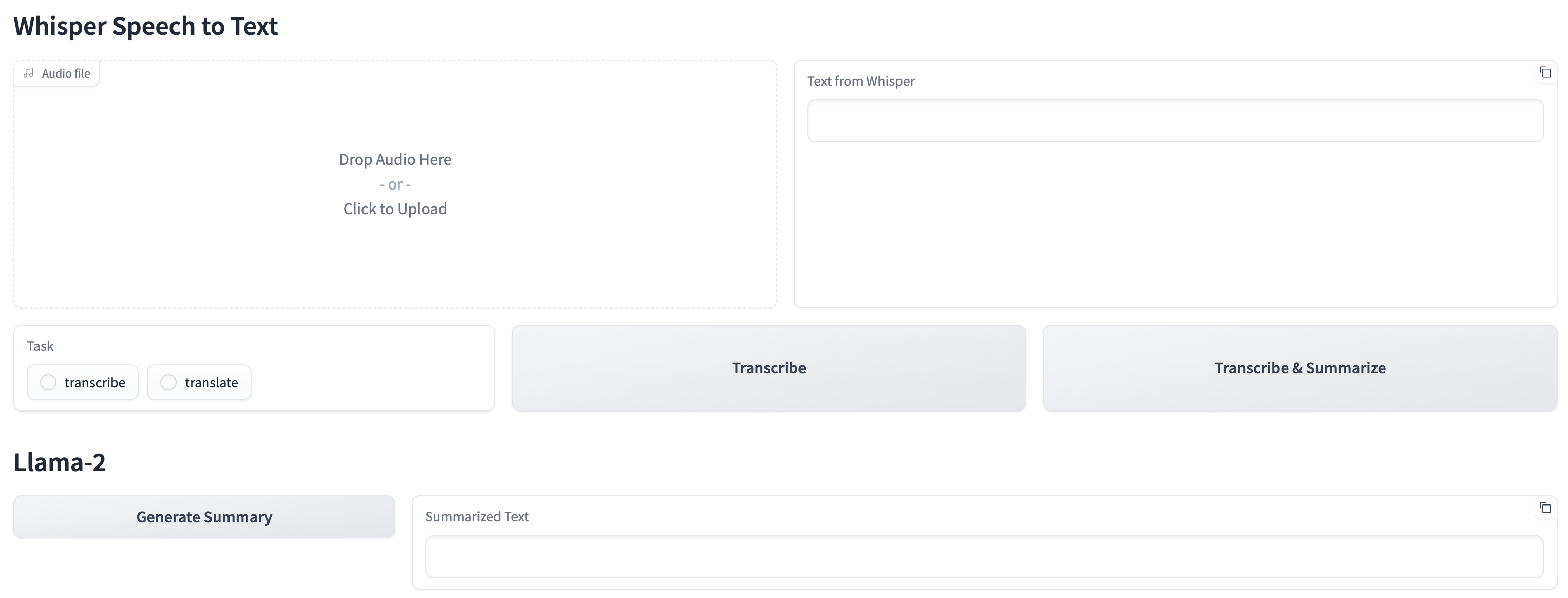
- Once the file has been uploaded, we can either Transcribe the audio file or Transcribe and Summarize its text.
- The default prompts are set for summarizing meeting notes but can be changed from the Advanced Options section