We suppose to apply traditional offline reinforcement learning technique to multi-agent algorithm.
In this repository, we implemented behavior cloning(BC), offline MADDPG, MADDPG+REM (MADDPG w/ REM), MADDPG+BCQ (MADDPG w/ BCQ) with pytorch.
Now, BCQ is in ' Working In Progress', and it's not implemented completely.
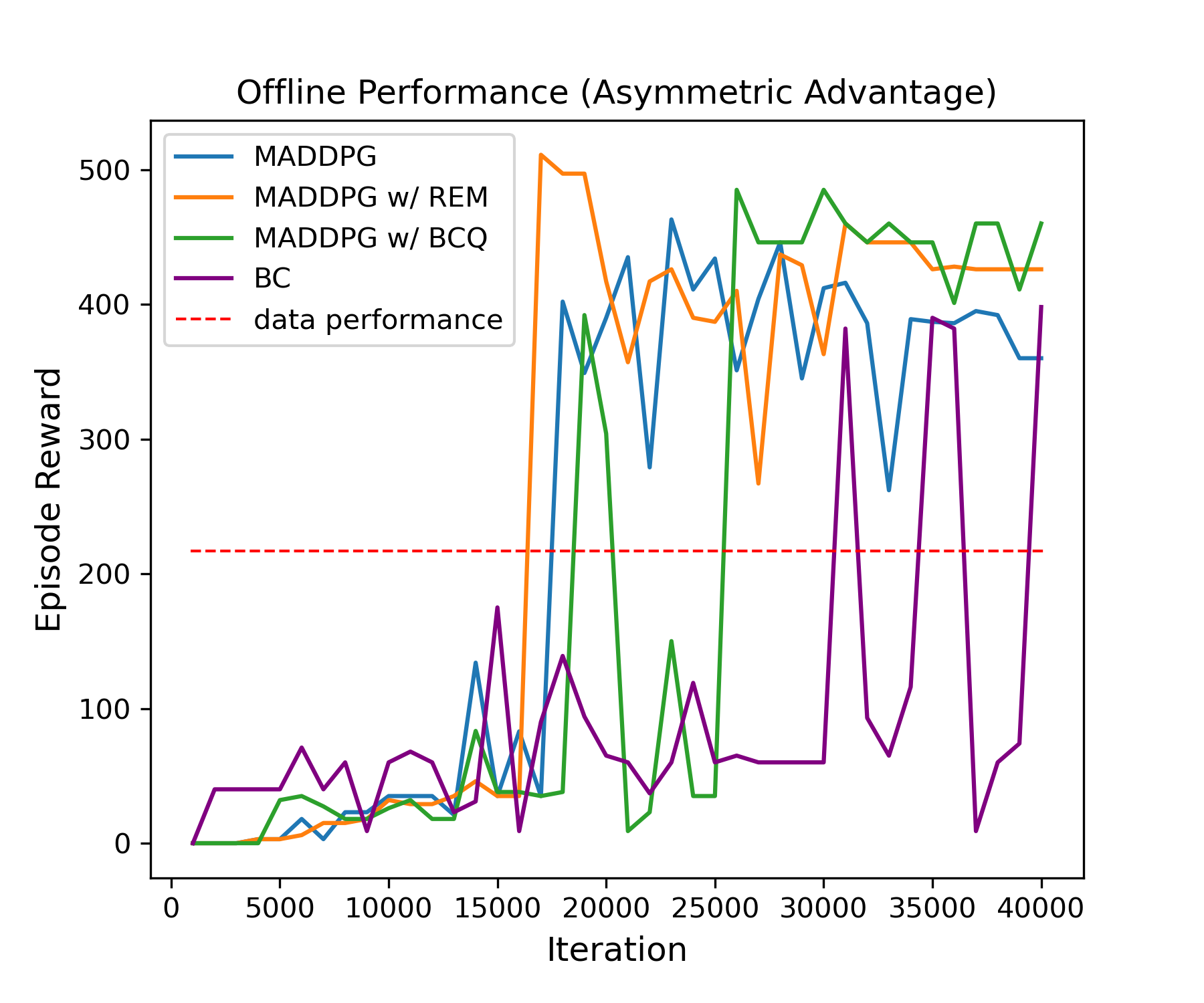
We collected 0.5M multi-agent offline RL dataset and experimented with each comparison methods. We collected this data with online MADDPG agents, and it includes exploration trajectories using OU noise.
The experiments are ran on Asymmetric Advantages on the Overcooked environment.
We are looking forward your contribution!
python train_online.py agent=maddpg save_replay_buffer=trueWhile the agents train with 0.5M steps, the trajectory replay buffer will be dumped in your experiment/{date}/{time}_maddpg_{exp_name}/buffer folder.
Please replace the path in config/data/local.yaml to the experiment by-product directory.
Or, if you want to use our dataset pre-collected, please enjoy this link.
We provide 0.5M trajectories in Asymmetric Advantages layout.
Please download our dataset in your local computer and replace the path in config/data/local.yaml
python train_bc.py agent=bc data=localpython train_offline.py agent=maddpg data=localpython train_offline.py agent=rem_maddpg data=localpython train_offline.py agent=bcq_maddpg data=local| Online | Offline (0.5M Data) | Offline (0.25M Data) |
|---|---|---|
 |
 |
 |
| Online | BC | Offline /w REM |
|---|---|---|
 |
 |
 |