
In the fast-paced world of modern robotics, autonomous systems capture vast amounts of video data, but sifting through this information still relies heavily on human operators. This manual review process is time-consuming and mentally exhausting, limiting the efficiency and effectiveness of data utilization.
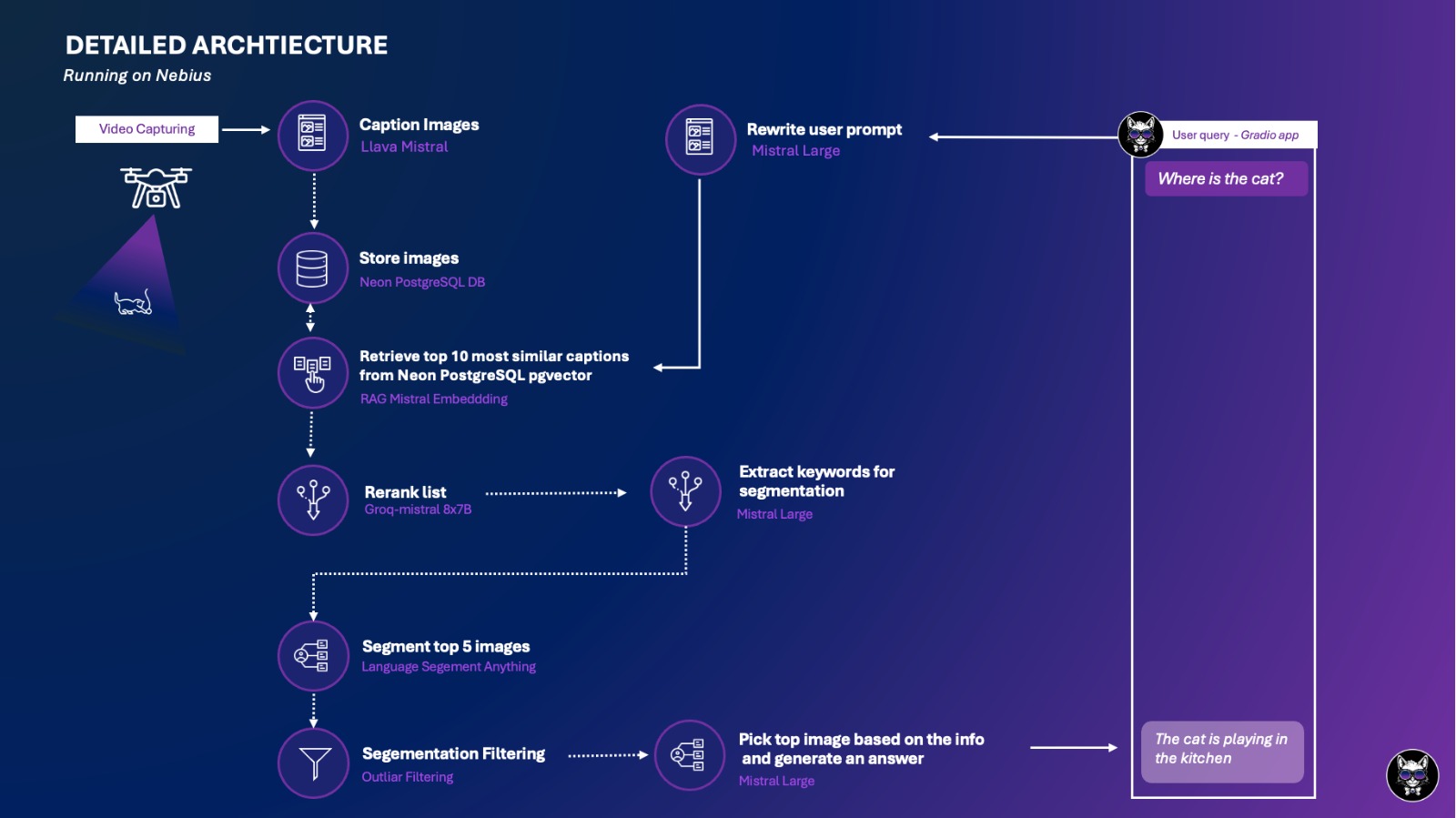
Enter Le ChatOn Vision, our revolutionary visual Retrieval-Augmented Generation (RAG) system. Le Chat-On Vision transforms how analysts interact with their data by allowing them to seamlessly query and understand captured videos through an intuitive chat interface. By significantly reducing cognitive load and accelerating insights, Le ChatOn Vision empowers analysts to focus on what truly matters—making informed decisions swiftly and accurately.
- Initially, a video dataset is collected and divided into individual frames.
- Subsequently, each frame undergoes captioning using a Visual Large Language Model (VLLM) during postprocessing. This involves feeding the frame image along with a task prompt instructing the VLLM to summarize the scene based on various features such as observable elements, activities, colors, and lighting. The output is textual data, which is then stored in the database.
- For user queries, a RAG pipeline is established to search and analyze the scene descriptions stored in the previous step. The Mistral embedding model is employed to find relevant scenes for a given query, while the Mistral LLM is used to interrogate the scenes and generate a helpful response.
During initial testing, it is evident that the VLLM performs well in generating broad qualitative descriptions of individual scenes but lacks in providing detailed quantitative descriptions, like the count of people in an image. To remedy this limitation, a segmentation model is introduced to precisely identify and quantify objects within the query. The obtained information supplements the VLLM frame caption, creating a context that combines both broad qualitative and detailed quantitative aspects.
Initially, the segmentation model encounters difficulties, leading to an abundance of outliers and inaccuracies in object segmentation. To tackle this issue, a Gaussian filter is introduced to eliminate outliers from segmented regions, thereby enhancing accuracy. As a result, Le ChatOn Vision can successfully count the number of people in the frame, even when the image is captured from a far distance. Additionally, it can provide a reasonably accurate count of the cans in the soda machine, despite the frames being of low quality due to motion blur.
Nebius cloud service was utilized, benefiting from its provision of a physical H100 GPU with 80GB RAM for compute tasks, augmented by an additional 160GB vRAM. This is particularly advantageous as the team was able to prioritize model selection over economic considerations for this project.
- The Mistral API was used for inference of the mistral-large and the embedding model for primary context interrogation and similarity searches using cosine similarity. Additionally, Mistral-derived LLaVA (
llava-v1.6-mistral-7Bcheckpoint) and Language Segment-Anything (vit_hcheckpoint) were deployed, both self-hosted locally on the compute server, for the VLLM and segmentation model, respectively. - For tasks like reranking the list of retrieved entites, the GroqAPI with a smaller size Mistral model (
8x7Bcheckpoint) was leveraged to ensure faster inference for text generation.
- A Postgres database hosted on Neon was used due to its user-friendly interface, which offers easy insights into the generated database via their web interface. This allows for straightforward deletion of columns and rows without the need to handle SQL commands, particularly beneficial during the testing phase of the project.
- Additionally, Neon's integration of pgvector simplifies and accelerates querying rows based on vector similarity, eliminating the need for manual cosine similarity calculations.
A Gradio application was developed to facilitate an efficient chat interface, featuring the display of the generated response alongside a representative image frame.
The system has been tested on Ubuntu 22.04.4 LTS with the following specs:
- Physical NVIDIA® Hopper H100 (80 GB RAM) SXM5 GPU card
- 20 vCPU Intel® Sapphire Rapids
- 160 GB vRAM on a virtual server
- Object storage – default 1 TB of space
- Disk storage - default 1 TB of network-ssd
Also check out the references in the next section:
git clone git@github.com:johanndiep/mistral_hackathon.git && cd mistral_hackathon
pip install -r requirements.txt
# deploy LLava [1] and fix in the same folder
cd ..
git clone git@github.com:kimborgen/LLaVA.git
cd LLavA
git checkout mistral-hackathon #quickfix
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
cd ..
# Deploy Language Segment-Anything [2, 3] and fix in the same folder
git clone git@github.com:kimborgen/lang-segment-anything
cd lang-segment-anything
git checkout mistral-hackathon
pip install -e .- Setup a Neon database and provide the database URL as an environment variable
DATABASE_URL[4] - Setup an environment variable
MISTRAL_API_KEYfor the Mistral key [5] - Setup an environment variable
GROQ_API_KEYfor the Groq API key [6]
python ui.py
- [1] LLaVA: https://github.com/haotian-liu/LLaVA
- [2] Segment Anything: https://github.com/facebookresearch/segment-anything
- [3] Language Segment Anything: https://github.com/luca-medeiros/lang-segment-anything
- [4] Neon Database: https://neon.tech/
- [5] Mistral API: https://github.com/mistralai/mistral-inference
- [6] Groq API: https://console.groq.com/docs/quickstart
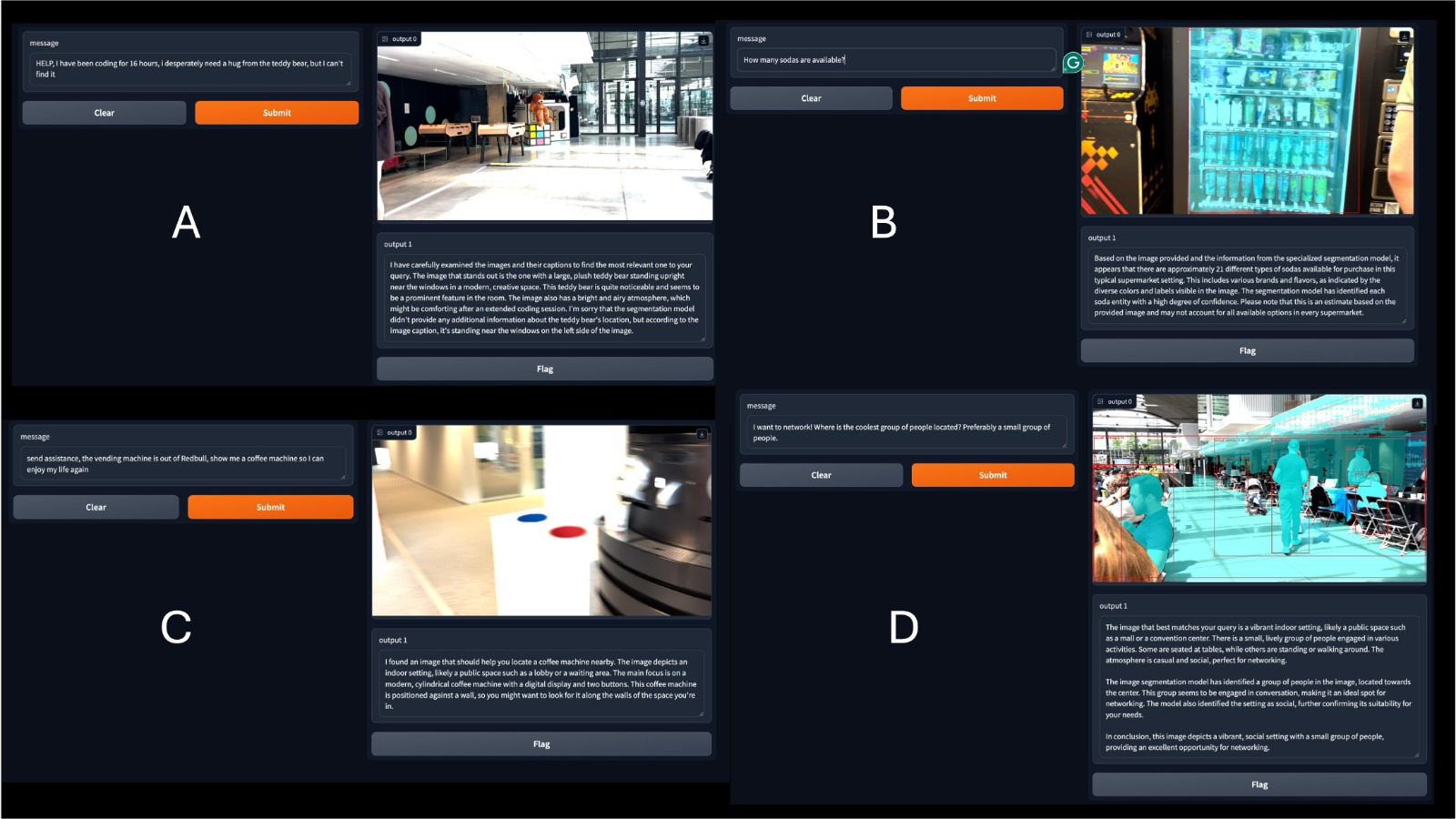
Le ChatOn Vision revolutionizes data analysis across industries. Fire-detecting drones, crop-inspecting robots, planetary rovers, and security patrol robots all benefit from its chat-based video querying. This system makes decision-making smarter, faster, and more efficient by transforming how video data is utilized.