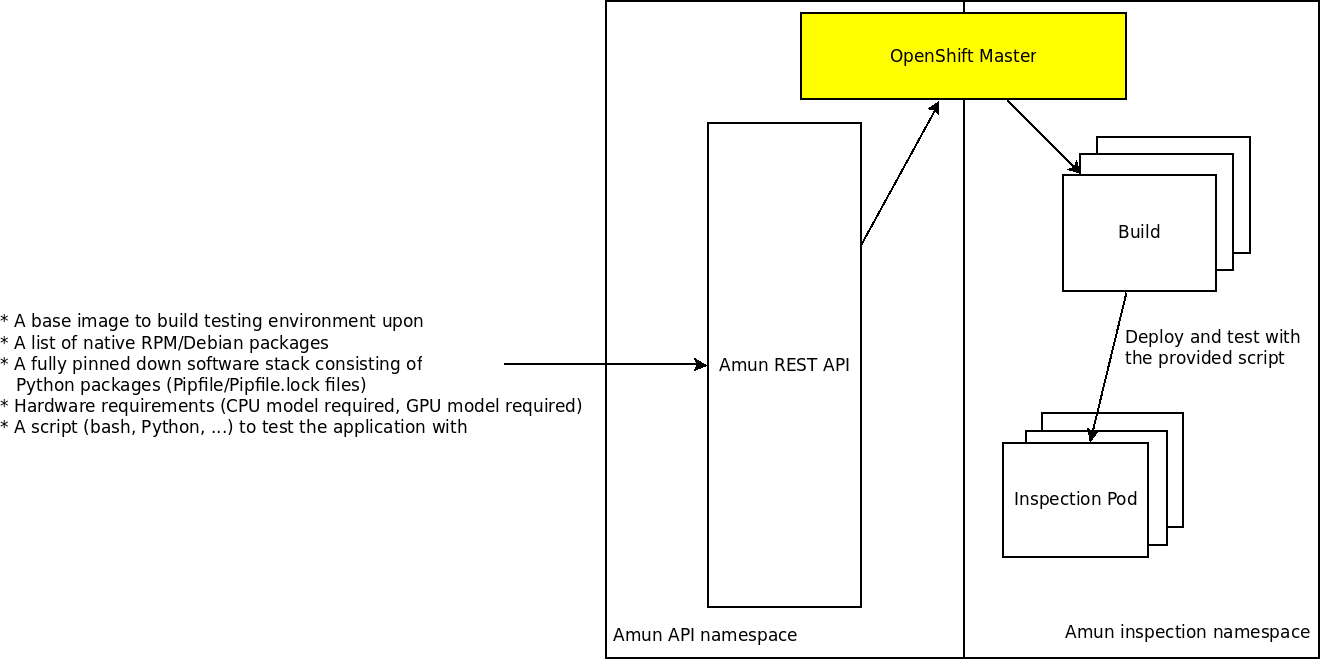
Amun is a service that executes the given application stack in the requested environment - given the list of package that should be installed as well as given the hardware that is requested to run the application. Its primary purpose is to act as an execution engine for Thoth where applications are built and tested (applications are automatically generated given the software requirements).
There are performed 2 core steps by Amun: 1. Assemble/build the given environment by installing requested native packages and/or Python packages - there are utilized OpenShift's ImageStreams and builds that are created on the fly on a user request. 2. Execute the given application using a script that is provided by a user - there are run "inspection pods" that execute provided user script. The script has to ensure that results are printed to standard output or stored data on a remote (Amun is stateless and does not store any other information except build/inspection success/failures, build/inspection logs).
The second step is performed if the build succeeded and a user provided a script to test the application with in the given built environment on the requested hardware (there are used node selectors in the cluster for this purpose).
By omitting script that is required to run in inspection pods, there is executed only build (the first step). Omitting the second step can be helpful for gathering information such as "Does the given application stack assemble?".
The actual second step is used to gather information whether the application runs with packages being installed in the build step as well as information such as performance characteristics or any other runtime-related information of the assembled application.
As Amun accepts purely JSON on its input, the inspection step requires a test file that is written to disk with an execute flag and run. The script itself is responsible for gathering relevant information (no database is provided on Amun side for this purposes).
One can see Amun as a CI running in a cluster.
A single request to API is composed of:
- an identifer of the inspection
- a base image itself (Fedora:28)
- a list of native packages (RPM or Deb packages) that should be installed into the requested base image (e.g. Fedora:28)
- a list of upstream packages should be installed into the requested base image
- a script (bash, Python or any other scripting language - if the given environment knows how to execute the script; if it has required interpreter)
- hardware requirements for pod placement performing builds of application stack (installing necessary dependencies)
- hardware requirements for pod placement performing actual application execution
See provided OpenAPI/Swagger specification available in this Git repository. Only the base image is required parameter.
Upon a successful request to Amun API, a user obtains an inspection_id.
This identifier is used to reference the given request. On the build endpoints
there are leveraged information about build status and the actual build logs,
on the job endpoints, there are leveraged information about the actual
inspection run - logs and logs printed to standard output and standard error
stream. These are logs printed by the script provided by the Amun user.
Each time there is created a request with a script run (so there is actually
spawned job responsible for running the provided script), there is run an
init container that gathers information about hardware that is present on
node where the application is run. This information is available as a JSON
file unde /home/amun/hwinfo/info.json. The script that is provided by
user can pick this file as a metadata for the inspection run (and for example
submit it to a remote).
The actual application that gathers information about hardware present can be found in amun-hwinfo repository.
I, as an Amun user, would like to test performance of optimized TensorFlow builds available on the `AICoE Python package index https://index-aicoe.a3c1.starter-us-west-1.openshiftapps.com>`_. I would like to use:
- TensorFlow provided on AICoE index (provide a Pipfile and Pipfile.lock respecting Pipenv configuration to use different package indexes)
- Python3, CUDA in specific version, .. - installed as RPMs
- Use a cluster node that exposes a GPU with CUDA support
- I would like to use Fedora:28 as a base image
- I don't need a node with GPU support to assemble/build the TensorFlow application
- I provide a Python script that is a TensorFlow application run to gather information about TensorFlow (the application can print a JSON with results, but can also push data to a remote API stated in the Python script itself).
Amun guarantees the application is built as requested and it is placed on the correct node inside the cluster given the application requirements (a GPU with CUDA support).
If the build part fails, the script cannot be run. The build failures can be observed on exposed build endpoints.
To comunicate with Amun API, use the autogenerated Swagger client that available in the amun-client repository.