
On February 23rd, 2020, the Twitter account @java tweeted out the following:
A simple tip to print the Array or List with index in the front. #Java

https://twitter.com/java/status/1231443603102294019
While this does of course work, it may not be the best solution (both in terms of readability and in terms of performance).
Other suggestions made in the replies were:
int i = 0;
for (String name : names) {
System.out.println(i++ + “: “ + name);
}and
for (int i=0; i < names.length; i++) {
System.out.println(i + ": " + names[i]);
}Then, Carsten Reckord suggested, that someone writes a microbenchmark to compare the three options. This is that microbenchmark suite.
|
ℹ️
|
I decided to add one further alternative, which uses streams and may be more comparable to the other two solutions: IntStream.range(0, names.length)
.mapToObj(index -> index + ": " + names[index])
.forEach(blackhole::consume);The original stream solution looped through the names twice (once when mapping them and once when printing them).
This solution only goes through them once (since This alternative is not contained in the original measurements below - in part because I only thought of this problem after I had already started measuring and in part because every new benchmark increases the runtime considerably. I will add the results for this new benchmark in separate gists. |
This microbenchmark suite uses JMH, a “Java harness for building, running, and analysing nano/micro/milli/macro benchmarks written in Java and other languages targetting the JVM.” [1]
Rather than using System.out.println(..) (which will synchronously output the given string to stdout by default), I decided to use an instance of Blackhole#consume(Object) instead.
This will prevent dead-code elimination by the runtime.
The blackhole objects in the following code are instances of Blackhole.
With that, we have three implementations:
-
The original suggestion using Streams
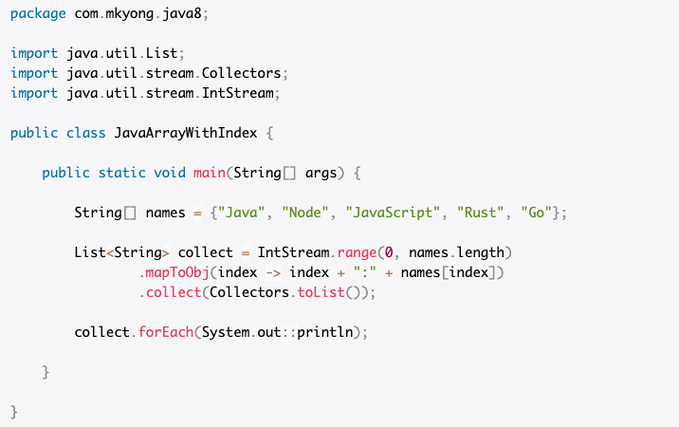
List<String> collect = IntStream.range(0, names.length) .mapToObj(index -> index + ": " + names[index]) .collect(Collectors.toList()); collect.forEach(blackhole::consume);
-
The suggestion by Coling MacLean using an enhanced for loop
int i = 0; for (String name : names) { blackhole.consume(i++ + ": " + name); }
-
My suggestion using a basic for loop with an index
for (int i = 0; i < names.length; i++) { blackhole.consume(i + ": " + names[i]); }
The benchmarks can be compiled with Maven:
$ ./mvnw clean package -DskipTestsfor the projects default Java version (8) to be used or
$ ./mvnw clean package -DskipTests -Djava.version=<java version>where <java version> can be anything between 8 and 14 (or maybe later), assuming you have a matching JDK available to Maven.
To check the Java version available to Maven, you can run:
$ ./mvnw -version
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: <home path>/.m2/wrapper/dists/apache-maven-3.6.3-bin/1iopthnavndlasol9gbrbg6bf2/apache-maven-3.6.3
Java version: 13.0.1, vendor: AdoptOpenJDK, runtime: /usr/lib/jvm/adoptopenjdk-13-hotspot-amd64
Default locale: de_DE, platform encoding: UTF-8
OS name: "linux", version: "5.3.0-40-generic", arch: "amd64", family: "unix"To change the projects default Java version, you can modify the java.version property in the pom.xml:
<properties>
<!--
Java version to use for compilation.
Possible values: 8, 9, 10, 11, 12, 13, 14...
-->
<java.version>8</java.version>
<properties>The benchmarks can then be run with:
$ java -jar target/benchmarks.java|
|
Running these benchmarks takes a long time. The total completion time for one call for me (with the original 3 benchmarks) was about 50 minutes. Having added a fourth benchmark (as described here) the time is even longer (estimated: 1:06:40 hours). |
Alternatively, a version of the tests with fewer runs can also be run with
$ ./mvnw test|
ℹ️
|
The benchmarks run with Options opt = new OptionsBuilder()
.measurementTime(TimeValue.seconds(1))
.measurementIterations(3)
.forks(3)
.include(MyBenchmark.class.getSimpleName())
.build();In comparison, the full test suite has the following definitions: @Measurement(
iterations = 5,
time = 10,
timeUnit = TimeUnit.SECONDS
)
@Fork(5)This reduction reduces the time to run all tests to an estimated 21:12 minutes. |
This project is set up to be built in Travis CI.
The build job can be found here, including the measurements (using ./mvnw test) for multiple JDK versions.
I ran all benchmarks with multiple Java versions.
There are two variants (which is what the listVariant output refers to):
- FIVE_NAMES
-
The original five names from the tweet:
{"Java", "Node", "JavaScript", "Rust", "Go"} - AUTO_GENERATED_NAMES
-
Normally, you wouldn’t run this kind of algorithm on just 5 names. So, to make the whole thing a bit more realistic, I had the benchmark generate 1000 names:
// 1000 new names final String[] firstNames = {"Alice", "Bob", "Charles", "Dora", "Emanuel", "Fabienne", "George", "Hannelore", "Igor", "Janice"}; final String[] middleNames = {"Kim", "Landry", "Maria", "Nikita", "Oakley", "Perry", "Quin", "Robin", "Skyler", "Taylen"}; final String[] surnames = {"Underhill", "Vaccanti", "Wilson", "Xanders", "Yallopp", "Zabawa", "Anderson", "Bell", "Carter", "Diaz"}; names = Arrays.stream(firstNames) .flatMap(firstName -> Arrays.stream(middleNames).map(middleName -> firstName + " " + middleName)) .flatMap(firstAndMiddleName -> Arrays.stream(surnames).map(surname -> firstAndMiddleName + " " + surname)) .toArray(String[]::new);
This name generation occurs within a function annotated with
@Setup(Leve.Trial). This means, that the array is generated before each trial and this generation will not be included in the measurement itself.
$ java -version
openjdk version "1.8.0_242"
OpenJDK Runtime Environment (build 1.8.0_242-8u242-b08-0ubuntu3~19.10-b08)
OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)Benchmark (listVariant) Mode Cnt Score Error Units
MyBenchmark.mapAndPrintWithStreams FIVE_NAMES thrpt 25 5207121,355 ± 276740,844 ops/s
MyBenchmark.mapAndPrintWithStreams AUTO_GENERATED_NAMES thrpt 25 27035,503 ± 2851,299 ops/s
MyBenchmark.printInEnhancedForLoop FIVE_NAMES thrpt 25 10380706,822 ± 786963,780 ops/s
MyBenchmark.printInEnhancedForLoop AUTO_GENERATED_NAMES thrpt 25 38088,946 ± 348,914 ops/s
MyBenchmark.printInOldSchoolForLoop FIVE_NAMES thrpt 25 10453896,992 ± 796088,166 ops/s
MyBenchmark.printInOldSchoolForLoop AUTO_GENERATED_NAMES thrpt 25 38599,330 ± 358,688 ops/sFor the original, shorter list, both for loops had about twice the throughput compared to the stream. With the much longer array of names, the enhanced for loop clocked in at about 1.41 times the throughput of the stream solution basic for loop managed about 1.43 times the throughput.
The complete output can be found in this gist.
$ java -version
openjdk version "11.0.6" 2020-01-14
OpenJDK Runtime Environment (build 11.0.6+10-post-Ubuntu-1ubuntu119.10.1)
OpenJDK 64-Bit Server VM (build 11.0.6+10-post-Ubuntu-1ubuntu119.10.1, mixed mode, sharing)Benchmark (listVariant) Mode Cnt Score Error Units
MyBenchmark.mapAndPrintWithStreams FIVE_NAMES thrpt 25 4296358,352 ± 545014,011 ops/s
MyBenchmark.mapAndPrintWithStreams AUTO_GENERATED_NAMES thrpt 25 26803,661 ± 3479,115 ops/s
MyBenchmark.printInEnhancedForLoop FIVE_NAMES thrpt 25 9348700,863 ± 1023949,109 ops/s
MyBenchmark.printInEnhancedForLoop AUTO_GENERATED_NAMES thrpt 25 37878,684 ± 3026,570 ops/s
MyBenchmark.printInOldSchoolForLoop FIVE_NAMES thrpt 25 9819339,718 ± 1230652,392 ops/s
MyBenchmark.printInOldSchoolForLoop AUTO_GENERATED_NAMES thrpt 25 39678,611 ± 3593,970 ops/sFor the original, shorter list, the enhanced for loop had about 2.18 the throughput compared to the stream while the basic for loop had about 2.29 times the throughput. With the much longer array of names, the enhanced for loop clocked in at about 1.41 times the throughput of the stream solution basic for loop managed about 1.48 times the throughput.
The complete output can be found in this gist.
$ java -version
openjdk version "13.0.1" 2019-10-15
OpenJDK Runtime Environment AdoptOpenJDK (build 13.0.1+9)
OpenJDK 64-Bit Server VM AdoptOpenJDK (build 13.0.1+9, mixed mode, sharing)Benchmark (listVariant) Mode Cnt Score Error Units
MyBenchmark.mapAndPrintWithStreams FIVE_NAMES thrpt 25 5355473,456 ± 527496,942 ops/s
MyBenchmark.mapAndPrintWithStreams AUTO_GENERATED_NAMES thrpt 25 26485,990 ± 2196,793 ops/s
MyBenchmark.printInEnhancedForLoop FIVE_NAMES thrpt 25 8839903,376 ± 991895,966 ops/s
MyBenchmark.printInEnhancedForLoop AUTO_GENERATED_NAMES thrpt 25 35993,876 ± 2339,770 ops/s
MyBenchmark.printInOldSchoolForLoop FIVE_NAMES thrpt 25 9110027,753 ± 678835,086 ops/s
MyBenchmark.printInOldSchoolForLoop AUTO_GENERATED_NAMES thrpt 25 35559,584 ± 2999,247 ops/sFor the original, shorter list, the enhanced for loop had about 1.65 the throughput compared to the stream while the basic for loop had about 1.70 times the throughput. With the much longer array of names, the enhanced for loop clocked in at about 1.36 times the throughput of the stream solution basic for loop managed about 1.34 times the throughput.
The complete output can be found in this gist.
$ java -version
openjdk version "14-ea" 2020-03-17
OpenJDK Runtime Environment (build 14-ea+27-1339)
OpenJDK 64-Bit Server VM (build 14-ea+27-1339, mixed mode, sharing)Benchmark (listVariant) Mode Cnt Score Error Units
MyBenchmark.mapAndPrintWithStreams FIVE_NAMES thrpt 25 4755692,653 ± 410854,229 ops/s
MyBenchmark.mapAndPrintWithStreams AUTO_GENERATED_NAMES thrpt 25 24668,440 ± 2109,834 ops/s
MyBenchmark.printInEnhancedForLoop FIVE_NAMES thrpt 25 8991645,685 ± 841362,203 ops/s
MyBenchmark.printInEnhancedForLoop AUTO_GENERATED_NAMES thrpt 25 32641,574 ± 3623,476 ops/s
MyBenchmark.printInOldSchoolForLoop FIVE_NAMES thrpt 25 8576218,147 ± 790441,689 ops/s
MyBenchmark.printInOldSchoolForLoop AUTO_GENERATED_NAMES thrpt 25 27693,151 ± 2840,307 ops/sFor the original, shorter list, the enhanced for loop had about 1.89 the throughput compared to the stream while the basic for loop had about 1.80 times the throughput. With the much longer array of names, the enhanced for loop clocked in at about 1.32 times the throughput of the stream solution basic for loop managed about 1.12 times the throughput.
The complete output can be found in this gist.
Both for loops were considerably faster than the stream solution suggested in the original tweet (about twice the throughput for the short list and about 1.4 times the throughput for the much longer list). In both cases, the enhanced for loop was slightly better than the basic for loop.
The exact measurements may vary depending on a number of factors, including but not limited to:
-
the hardware used to run the benchmarks
-
the Java version used to run the benchmarks
-
other processes running at the same time as the benchmarks
The finding, that both for loops are faster than the solution using streams however is very likely to hold up, even taking those considerations into account.
One major point to be considered when writing code is the readability of this code - ideally, code should be easy to understand. Or, to quote Martin Fowler:
Any fool can write code that a computer can understand. Good programmers write code that humans can understand.
Refactoring: Improving the Design of Existing Code, 1999, p. 15
This microbenchmark suite can not (and does not try to) measure readability, in part because this is subjective. However, here are my thoughts on the three implementations.
List<String> collect = IntStream.range(0, names.length)
.mapToObj(index -> index + ": " + names[index])
.collect(Collectors.toList());
collect.forEach(blackhole::consume);This has a total of 4 lines of code (not counting the empty line). To understand what it’s doing, you have to understand how the stream is created, which and how many elements are contained in that stream, how the mapping works and how the collection works.
int i = 0;
for (String name : names) {
blackhole.consume(i++ + ": " + name);
}This also has a total of 4 lines of code.
To understand what it’s doing, you have to understand how an enhanced for loop[2] works and when the index is incremented for i++.
for (int i = 0; i < names.length; i++) {
blackhole.consume(i + ": " + names[i]);
}This has a total of 3 lines of code.
To understand what it’s doing, you have to understand how a basic for loop works and when the index is incremented for i++.
I am of the opinion (and you may disagree on this), that the basic for loop is the best choice here for the following reasons:
-
it has the fewest lines of code while still being easy to understand
-
it requires only very basic knowledge of the Java language and no APIs (such as the Stream API)
-
it makes explicit use of the index
i, not only to retrieve the item from the array but also to be part of the result