Lempel–Ziv–Storer–Szymanski(LZSS)是一个无损数据压缩算法,属于LZ77的派生,1982年由James Storer和Thomas Szymanski创建。LZSS发布于《Journal of the ACM》的“Data compression via textual substitution”。
LZSS是一种字典编码技术。它会尝试以符号字符串替换相同字符串为一个字典位置的引用。
压缩前 177字节
I am Sam
Sam I am
That Sam-I-am!
That Sam-I-am!
I do not like
that Sam-I-am!
Do you like green eggs and ham?
I do not like them, Sam-I-am.
I do not like green eggs and ham.
压缩后 94字节
I am Sam
(5,3) (0,4)
That(4,4)-I-am!(19,16)I do not like
t(21,14)
Do you(58,5) green eggs and ham?
(49,14) them,(24,9).(112,15)(93,18).
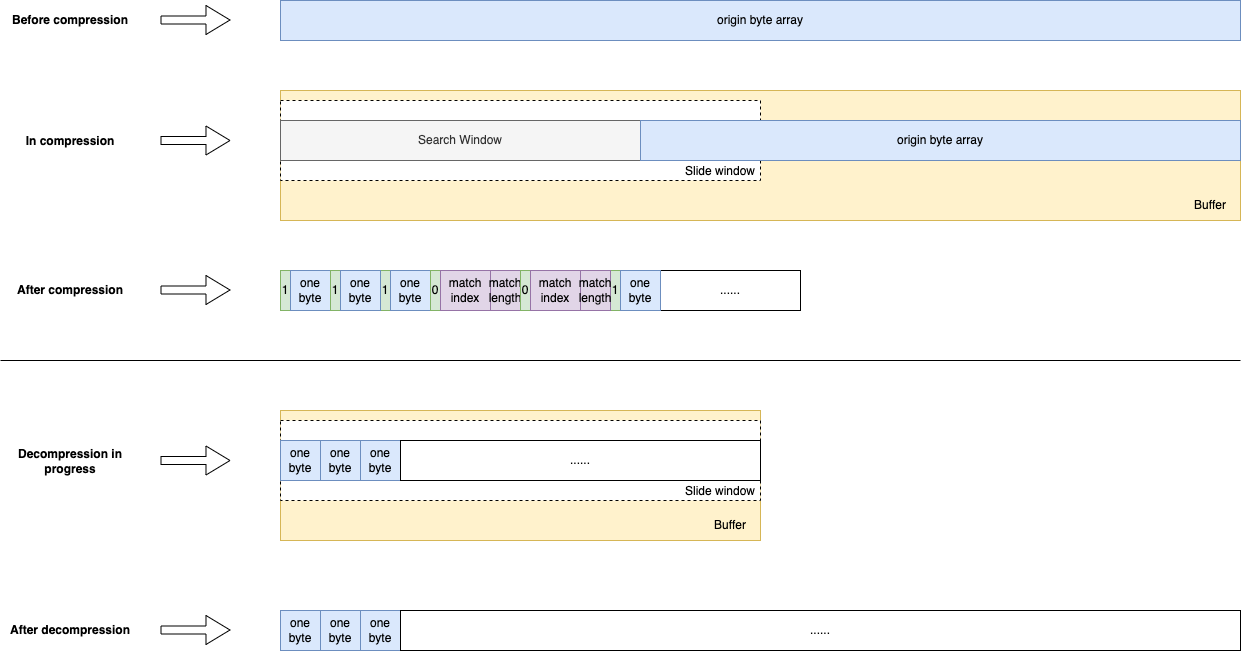
LZSS 算法的压缩效果与多个因素有关:
- 原始数据重复数据越高,压缩效果可能越好,但重复的数据最好能在一个窗口内,否则起不到效果
- 重复数据的长度越长,压缩效果越好;如果重复数据都是单字节,那基本没有压缩效果
- 窗口越大更容易找重复数据,但是窗口占的bit也越多
所有实现的参考项目, 源代码来自 https://oku.edu.mie-u.ac.jp/~okumura/compression/lzss.c
- 实现了文件的压缩和解压
- 为参考项目添加了单元测试
基于参考项目稍微做了一些改造:
- 直接对字节数组进行压缩和解压,而不是文件
- 允许方法同一时间多次调用:移除共享变量,新增 EncodeBuffer、DecodeBuffer 等结构
- 单元测试新增十六进制字符串和字节数组相互转换
基于C语言实现,改造成了Java实现
- 添加了部分注释,帮助理解算法逻辑
- 重新为变量命名,起到了见名知义的效果
- 单元测试