This repository provides the basis for the COBECORE based Jungle Weather project's pre- and post-processing. However, this repository can also serve as a template for other data recovery project, especially those in which the forms used are fairly regular in nature.
The code base relies on python and OpenCV based pre-processing, including machine learning screening using TensorFlow. All post-processing, after annotation on Zooniverse, will be done in R. Given the convenient structure of R packages this approach is used to organize the project.
You can cite the code in this repository like this:
Hufkens K. (2022). The Jungle Weather workflow: facilitating data digitization https://doi.org/10.5281/zenodo.3378864
Note that all code is released under an AGPLv3 license, except for the transfer learning code which fall under an Apache license (for changes see code headers). All data, except the Burton data sheets, is (c) copyright of the COBECORE and the Belgian State Archive in particular, any re-use is NOT permitted without an explicit agreement. Any data is therefore included for testing and illustration purposes only, until a formal publication and lifting of this notice. Any use without permission will result in prosecution.
Note that this code comes without any guarantees. I refer to my consulting policy if you need custom advice on your project, unrelated to standard bug reports.
In our project we used a custom reproduction setup, however for general purposes we list all parts required for a light weight data recovery project.
- DSLR Camera (24MP) - e.g. Canon 750D or 850D (T6i T8 in the US)
- Semi wide angle lens - e.g. Canon EF-S 24mm f/2.8 STM Lens
- Dummy battery - allows you to run the camera indefinitely without having to recharge batteries
- Macro ring light - lens mounted, for illumination without shadow
- 2x Lighting panels - for side illumination in darker settings
- (Travel) tripod - Light and sturdy tripod, can be any brand
- Overhead camera boom pole - to avoid the tripod "feet" you will need a boom which extends horizontally
- 1 or 2TB SSD external hard drive - for shock resistant backups
- white table cloth as uniform background
Try to find USB powered peripheral electronics to limit the number of power sockets required, and keep things tidy.
In the COBECORE project we used a free software solution, built around a Ubuntu linux install and Entangle for image acquisition.
The Jungle Weather workflow relies on template matching. This technique is commonly used in automatic form completion and matches an existing, empty, template with a completed form. Although most historical data isn't designed from the ground up for template matching we can leverage this technique to reduce the workload required during transcription.
In particular, it addresses the issue of outlining locations in a table which contain data, and reducing the complexity of the transcription. As such the workflow will generate data which only presents one value at a time for transcription, limiting the chance of propagating errors in incomplete or corrupted series. At the same time this makes the task easier to complete in informal settings, on a cellphone or a tablet rather than a computer.
Below you find an outline of the steps required to set up a successfull template matching routine using the code in this repository. Throughout this process I also assume a consistent naming convention in which data is grouped per site, or archival id and delimited using underscores. All images are therefore structured: archive-id_scan-nr.jpg a real example therefore reads 6120_057.jpg. You will need to adjust some code below if this structure will not fit your data, as the file name is used as a way to store important meta-data.
Most historical tabulated data has a fixed format. This is a feature which I'll leverage later on. However, to ensure that the below procedures work well it is necessary to identify all the different table formats in a dataset. Particular care should be taken to ensure that small differences are accounted for, as even font changes can lead to less desirable post-processing results.
Overall make sure to:
- check for font differences
- check for line spacing differences
- overall correspondence between different tables should be high
In the Jungle Weather project we identified 20+ format of which three make up the bulk of all scanned data (>60%).
It is best to sort the images using a non-destructive method. It is therefore best to use a non-destructive photo editor or manager combined with tags rather to sort the data, rather than copying the source files around. In case of the Jungle Weather we used the Shotwell photo editor and manager, on Windows and OSX Adobe Lightroom might serve the same purpose.
In terms of the time required I estimate that sorting and labelling roughly 100K images would take at most a week of time. Within Jungleweather I finished the +70K images in less than a week, with a high variety of formats.
Once all different table formats are identified empty templates should be generated, and matching table cells annotated.
Where possible search the dataset for an already empty table. If no empty table exist use a table with as few data points as possible. Open this (almost) empty table using an image processing software. I suggest using GIMP, as I'll use a plugin later on to outline the cells of a table and it is freely available cross platforms.
Convert the this open file to a black and white template, while using the levels and curves to boost contrast and remove any unwanted gradients in the image. Remove all text which is not part of an empty template using the eraser. The final result should look as the image below.
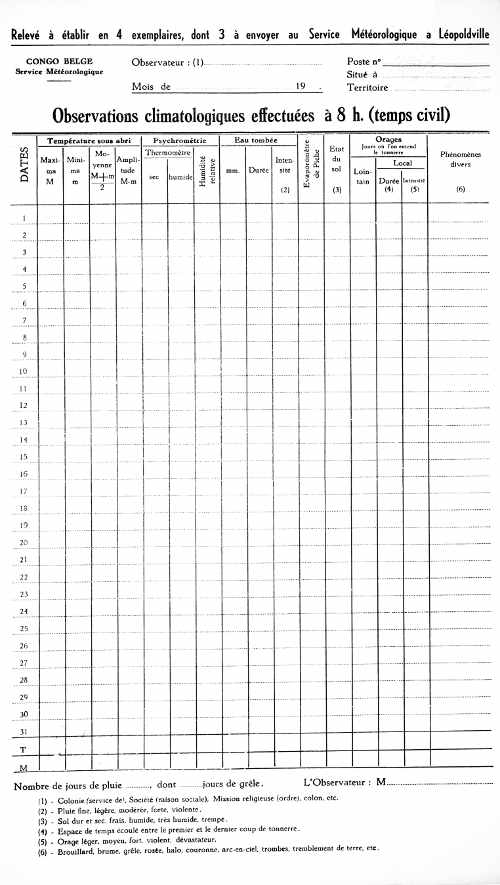
When saving these templates use a comprehensive naming scheme with a prefix and a number separated with an underscore (_) such as: "format_1.jpg" corresponding to the folder containing the image data.
This formatting is important for successful use of the python processing code!
To specify the location of data within a table we will use the guides in GIMP, and a plugin to save this information. To save the guides in GIMP first install the "save & load guides plugin". After installation of the plugin (and restarting GIMP) outline all cells in a table using GIMP guides. Below you see a template with all columns outlined with vertical guides.
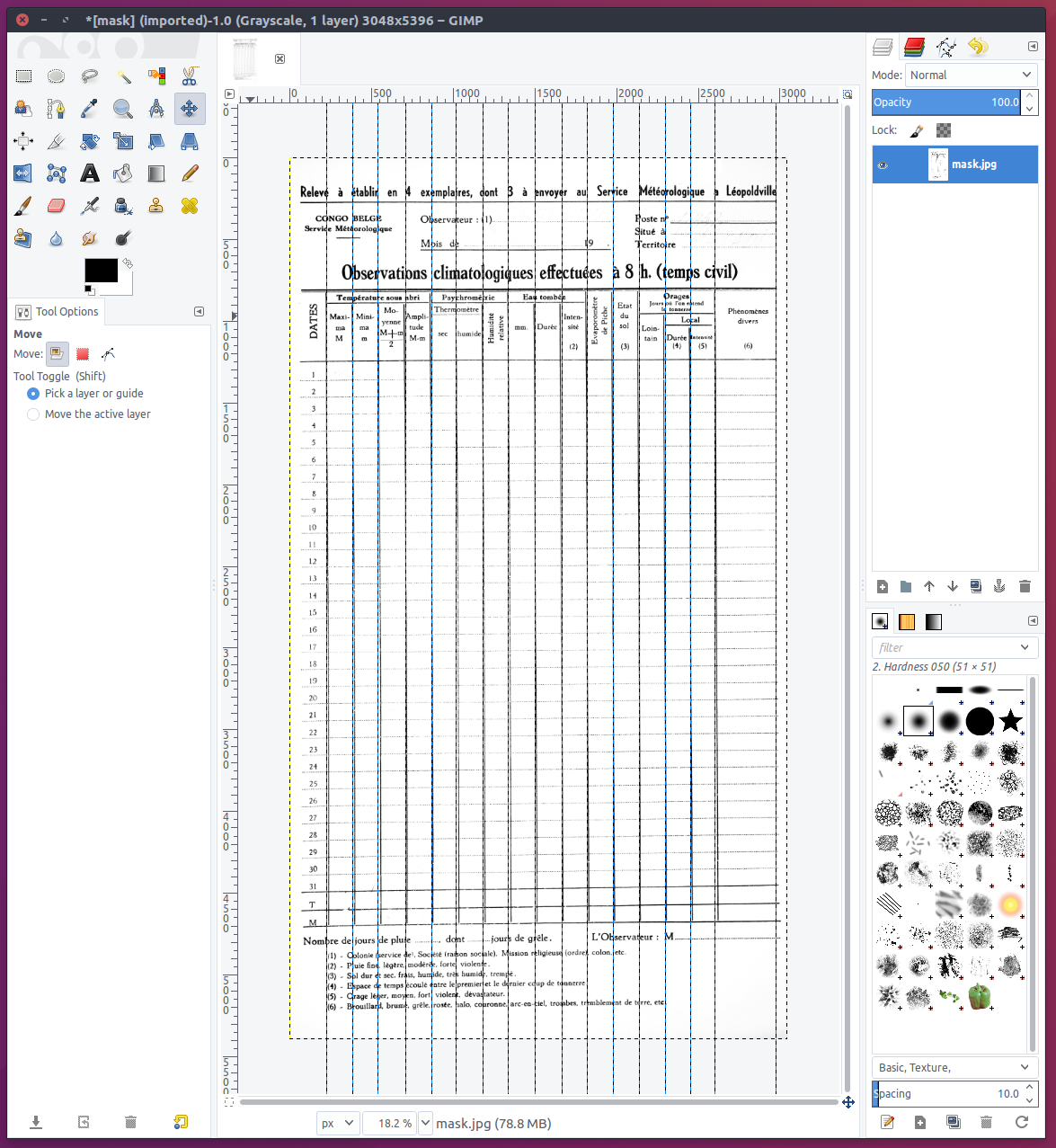
Once done, save the guides using the plugin (use: Image > Guides > Save). Make sure that the name used for the guides exactly matches the name of the image on which the guides are based. The guides will be saved in a file called "guides.txt" and stored this location: "[userfolder]/.gimp-2.8/guides/guides.txt". Copy this file to your project folder for future processing (I store template data in a dedicated template folder containing all template images and the guides.txt file).
Note that you can save multiple sets of guides for multiple templates in the same guides.txt file.
Both tasks depend on the amount of formats available. In case of the COBECORE data one day was sufficient to generate all template files and associated guides.
The pre-processing of the data depends on OpenCV, an open source computer vision library. As such a recent version (>3) of OpenCV must be running on your system. Screening tables for empty values is done using a TensorFlow based classifier, and requires these libraries to be installed (a trained model is included in this repository). Standard matrix operations are done using numpy and pandas libraries. Both can be installed using the below commands, or come as defaults with your python installation.
# install pip, the python package manager
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python get-pip.py
# install pandas
pip install pandas
# install numpy
pip install numpy
# install OpenCV
pip install opencv-contrib-python
# install tensorflow (CPU)
pip install tensorflow
# for those with CUDA enabled NVIDIA cards you may use
# pip install tensorflow-gpuThe python scripts used for template matching and general pre-processing are found in src directory of the repository. The scripts tackle various tasks but in general should need attention. The main function is called match_template.py which calls the other scripts or subroutines when required. All other scripts can be run stand-alone if so desired. The latter might be useful in debugging and development.
The match_template.py script uses ORB features to match the template as generated above, to a data table with completed cell values. Below you see a visual representation of matched features (connected with lines) between a complete table on the left and an empty template on the right.

If good correspondence is established we can transform the image containing data to align (perfectly) with the template. Below and example is given where the transformed data is shown in red/pink tints, the template is shown as light blue, the image is dark blue where there is correspondence between both images. Note how light blue, template, header texts transition into an almost perfect correspondence with the image which contains data.

Although the main feature of the code is focussed on matching the template with the provided data table additional functions are applied on the source data table. In particular, an inner crop is executed on the image which crops out the black boarder around scanned images in the COBECORE workflow.
The transformed image is subsequently divided into individual cells (with some padding to account for small misalignments) and written to disk. The code also includes screening the data for empty cells using a TensorFlow machine learning model trained on the dataset at hand. A detailed description of this routine is given below.
I use a machine (transfer) learning approach to retrain a TensorFlow based convoluted neural net (CNN) in order to detect empty cells in the historical data tables. For convenience the model is run on individual (extracted) cells rather than on the data sheet as a whole. Although the latter approach would be feasible, the workflow described above made it easier to deal with the data on a cell by cell basis.
For a number of data sheets the data was sorted in complete and empty cells. This data was then used in combination with the transfer learning code to train the CNN. The trained model is stored in the src/cnn_model directory and used when calling the label_table_cell.py code. The project includes a pre-trained model for reference.
At the end of the template matching all cells are evaluated and the results, together with a graphical preview, are written to the output directory as specified in the match_template.py routine. An example of the graphical preview is given below, with the colour coding the same as in the template matching example above, with the addition of white X marks for those cells flagged as empty.
Although the classification results aren't 100% perfect, the general agreement is good enough to pre-screen columns, on a column by column basis.
Template matching is automated so a time requirement in terms of true man hours is pointless. Howeve, the processing of one table takes ~7 seconds. Which translates in roughly 6 days of computational time to process the digitized tables within the COBECORE project. Although performance might vary depending on the system used the expected times would be reasonable, and measured in days rather than weeks.
Although the naming of fields as output by the Zooniverse database is project specific small adjustments should make it possible to re-use the code base quickly within a different context. Unlike the pre-processing which relies on a variety of mainly python tools, the post-processing will be done exclusively in R. Meeting the requirements for processing is easier as the tools can be installed using the internal R based packaging system.
In order to install the R code base for this project, clone the project using:
git clone https://github.com/khufkens/jungleweather.gitor use the download link.
With RStudio installed open the R project by double clicking on the .Rproj file. This will open up the project in RStudio. Explore the functions in the R directory and adjust to your needs (naming conventions).
As the project has not produced any results yet only very basic meta-data scripts are included. More will folow as the project progresses.
This project was supported by the Belgian Science Policy office COBECORE project (BELSPO; grant BR/175/A3/COBECORE),the Marie Skłodowska-Curie Action (H2020 grant 797668) and BlueGreen Labs.